Stock_Price_Analysis
1.0.0
Dieses Projekt wurde erstellt, um die Verwendung von Makros zu veranschaulichen, die mit VBA für Excel entwickelt wurden und zur Automatisierung der Erfassung und Visualisierung von Daten aus einer ausgewählten Gruppe grüner Energiebestände verwendet werden können. Dies wurde verwendet, um die Möglichkeiten der Verwendung von Makros zu demonstrieren und wie diese mithilfe grafischer Schnittstellen wie Schaltflächen automatisiert werden können, um eine wiederholbare Verwendung der Aufgabe zu ermöglichen. Für dieses Projekt wurden Bestandsdaten von 12 Aktien verwendet, die in den Jahren 2017 und 2018 gesammelt wurden. Zu den verwendeten Daten gehörten der Tickercode, die Eröffnungs- und Schlusswerte der Aktien sowie das tägliche Handelsvolumen für jeden Tag. Daraus konnten wir den ersten und letzten Aktienkurs sowie das gesamte Handelsvolumen für jede analysierte Aktie ermitteln.
Ein weiteres Ziel dieses Projekts bestand darin, zu untersuchen, wie die Effizienz des Codes mithilfe von Refactoring verbessert werden kann, um die zur Vervollständigung der Makros erforderliche Rechenleistung zu optimieren. Hierzu haben wir unsere ursprüngliche Version des Codes verwendet, die zwar funktionsfähig war, aber vom Programm eine Iteration des gesamten Datensatzes für jeden Börsenticker durchführen musste, den wir analysieren wollten. Das Ziel bestand darin, eine überarbeitete Version des Originalcodes zu entwickeln, bei der das Programm nur die Iteration des Datensatzes abschließen und dieselben Daten wie in der ersten Version erhalten musste.
Zunächst entwickelten wir Funktionscode, der die Erfassung des gesamten jährlichen Aktienvolumens und der Jahresperformance jeder Aktie, die wir analysieren wollten, ermöglichte. Wie in dem unten bereitgestellten Code zu sehen ist, wurden die Daten für jede Aktie erfasst, indem eine Iteration des Datensatzes durchgeführt und die Daten in das Excel-Arbeitsblatt eingefügt wurden, bevor mit der nächsten Aktie fortgefahren wurde.

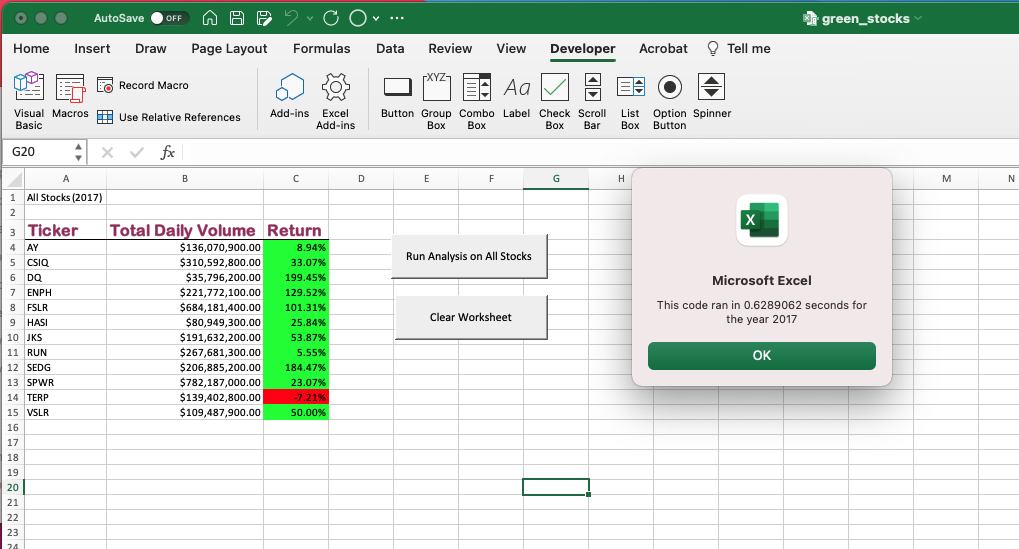
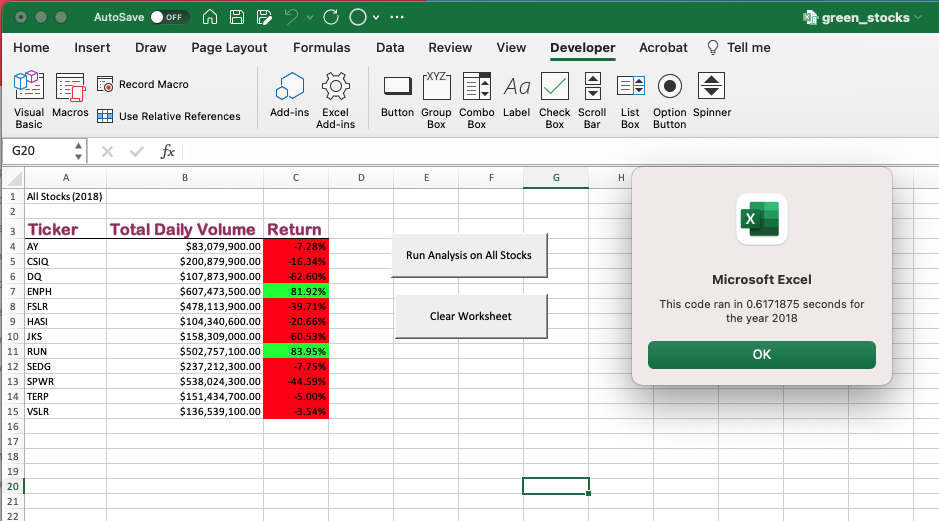
In den Code war ein Timer eingebettet, der die Zeit anzeigte, die das Programm zum Ausführen benötigte, und die Ergebnisse anzeigte. Auf diese Weise können wir die Zeit vergleichen, die zum Vervollständigen des ursprünglichen Codes zum Sammeln der Daten für die Datensätze für jedes Jahr erforderlich ist. Dies lieferte uns eine Ausführungszeit für den Code für jedes Jahr, wie in den Bildern unten zu sehen ist. Es zeigt, dass der ursprüngliche Code 0,6289062 Sekunden für die Vervollständigung des Datensatzes 2017 und 0,6171875 Sekunden für die Vervollständigung des Datensatzes 2018 benötigte.
Durch die Umgestaltung des ursprünglichen Arbeitscodes kann eine effizientere Nutzung der Rechenleistung erreicht werden, indem die Anzahl der Gesamtiterationen des Datensatzes reduziert wird, was zu einer Erhöhung der Geschwindigkeit der Ausführung der Aufgabe führt. Um diesen Code umzugestalten, mussten dem zu entwickelnden Makro zwei Komponenten hinzugefügt werden. Der erste war ein Index für jeden Ticker, der für jede Datenzeile in den analysierten Datensätzen iteriert wurde. Dadurch würde das Programm für jede Datenzeile innerhalb des Datensatzes identifizieren, welcher Ticker vorhanden war, und die relevanten Daten im Zusammenhang mit dem Indexwert speichern. Das zweite war eine Sammlung von Datenarrays zum Speichern der mehreren Datenpunkte für jeden Börsenticker. Da jeder im Array gespeicherte Wert in der Reihenfolge seiner Erfassung abgerufen werden konnte, war es möglich, diese Daten wieder mit dem verwendeten Tickerindex zu verknüpfen. Die Verwendung dieser beiden Tools ermöglichte die Umgestaltung des Codes, wie im folgenden Beispiel dargestellt.

Unter Verwendung desselben Codes, der zur Bestimmung der Ausführungszeit des ursprünglichen Codes verwendet wurde, konnte festgestellt werden, ob im umgestalteten Code für die Analyse eine Verbesserung der Ausführungszeit beobachtet wurde. Wie in den Bildern unten zu sehen ist, wurde die Zeit, die zum Abschluss der Analyse der Daten aus den Jahren 2017 und 2018 benötigt wurde, mit dem neuen Code verglichen und dieser wurde zum Vergleich mit dem ursprünglich verwendeten Code verwendet. Daraus konnten wir erkennen, dass die Fertigstellung des Datensatzes 2017 0,5273438 Sekunden und die Fertigstellung des Datensatzes 2018 0,516825 Sekunden dauerte.
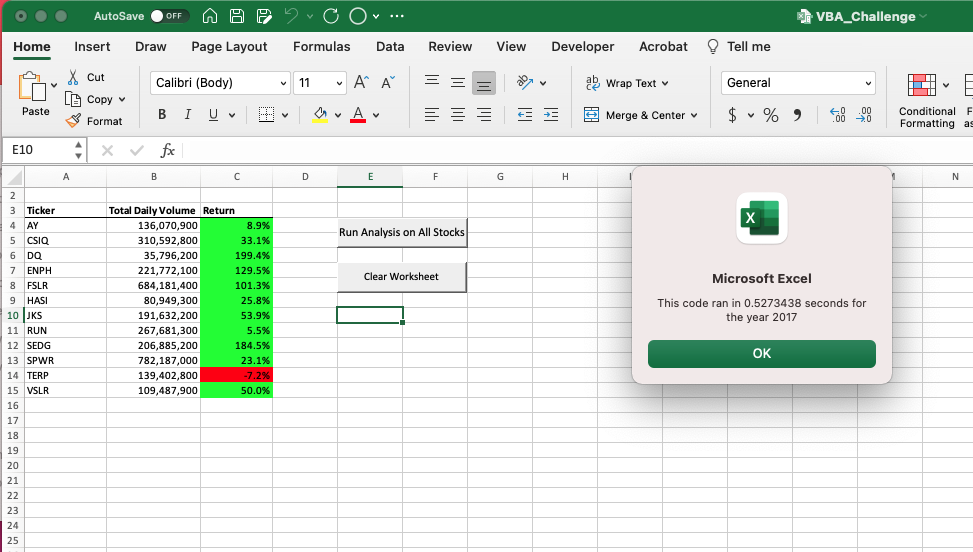
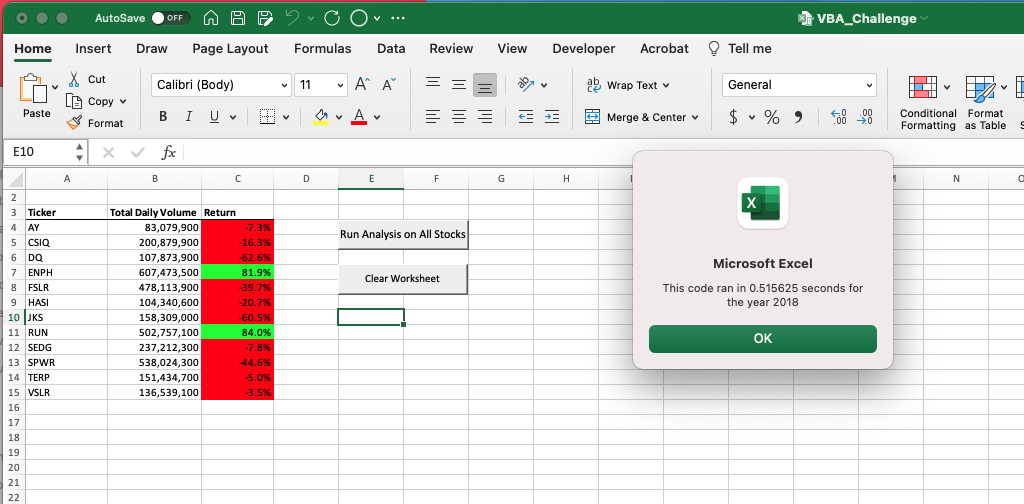
Aus den gesammelten Informationen, die auf der Zeit bis zum Abschluss der Ausführung des anfänglichen und umgestalteten Codes basieren, ergab sich eine Reduzierung um 0,1015624 Sekunden für den Datensatz 2017 und um 0,1103625 Sekunden für den Datensatz 2018.
Der Prozess des Refactorings von Code hat einige Vor- und Nachteile für seine Verwendung. Schauen wir uns zunächst einige der Vorteile an
Einige der Nachteile der Verwendung von Code-Refactoring.
In dem hier gezeigten Beispiel gab es einige Vor- und Nachteile des Refactorings, das durchgeführt wurde, um die Effizienz des Codes zu verbessern.
Einige der positiven Gedanken, die das Ergebnis der Codeänderung waren, sind wie folgt:
Reduzierte die zum Abschließen der Analyse benötigte Zeit, indem die Anzahl der zum Sammeln der Daten durchgeführten Iterationen reduziert wurde.
Das Ergebnis ist ein robusterer Code, der problemlos auf größere Datensätze und mehr Suchkriterien erweitert werden kann
Verwendete Arrays zum Speichern von Daten, die für andere Berechnungen oder Analysen verwendet werden können, wenn eine tiefergehende Analyse der Daten erforderlich wäre
Zu den negativen Faktoren für die Verwendung von Refactoring in diesem Code gehören die folgenden
https://www.c-sharpcorner.com/article/pros-and-cons-of-code-refactoring/" ↩ ↩ 2


