dream
v1.13.0
DeepPavlov Dream ist eine Plattform zur Erstellung generativer KI-Assistenten mit mehreren Fähigkeiten.
Um mehr über die Plattform und die Erstellung von KI-Assistenten damit zu erfahren, besuchen Sie bitte Dream. Wenn Sie mehr über den DeepPavlov Agent erfahren möchten, der Dream antreibt, besuchen Sie die Dokumentation zum DeepPavlov Agent.
Wir haben bereits sechs Distributionen beigefügt: Vier davon basieren auf dem leichtgewichtigen Socialbot Deepy, eine ist ein Dream-Chatbot in voller Größe (basierend auf der Alexa Prize Challenge-Version) auf Englisch und ein Dream-Chatbot auf Russisch.
Basisversion des Mondassistenten. Deepy Base enthält einen Spelling Preprocessing Annotator, einen vorlagenbasierten Harvesters Maintenance Skill und einen AIML-basierten Open-Domain Program-y Skill basierend auf dem Dialog Flow Framework.
Erweiterte Version des Mondassistenten. Deepy Advanced enthält Rechtschreibvorverarbeitung, Satzsegmentierung, Entity Linking und Intent Catcher-Annotatoren, Harvesters Maintenance GoBot Skill für zielorientierte Antworten und AIML-basierte Open-Domain-Program-y-Skill basierend auf dem Dialog Flow Framework.
FAQ-Version von Lunar Assistant. Deepy FAQ enthält einen Annotator zur Rechtschreibvorverarbeitung, eine vorlagenbasierte Fertigkeit für häufig gestellte Fragen und eine AIML-basierte Open-Domain-Programmierkompetenz basierend auf dem Dialog Flow Framework.
Zielorientierte Version des Mondassistenten. Deepy GoBot Base enthält einen Spelling Preprocessing Annotator, einen Harvesters Maintenance GoBot Skill für zielorientierte Antworten und einen AIML-basierten Open-Domain Program-y Skill basierend auf dem Dialog Flow Framework.
Vollversion von DeepPavlov Dream Socialbot. Dies ist fast die gleiche Version des DREAM-Socialbots wie am Ende der Alexa Prize Challenge 4. Einige API-Dienste werden durch trainierbare Modelle ersetzt. Einige Dienste (z. B. News Annotator, Game Skill, Weather Skill) erfordern private Schlüssel für die zugrunde liegenden APIs, die meisten davon sind kostenlos erhältlich. Wenn Sie diese Dienste in lokalen Bereitstellungen verwenden möchten, fügen Sie Ihre Schlüssel zu den Umgebungsvariablen hinzu (z. B. ./.env , ./.env_ru ). Diese Version von Dream Socialbot verbraucht aufgrund seiner modularen Architektur und seiner ursprünglichen Ziele (Teilnahme an der Alexa Prize Challenge) viele Ressourcen. Wir stellen auf unserer Website eine Demo von Dream Socialbot zur Verfügung.
Mini-Version von DeepPavlov Dream Socialbot. Dies ist ein generativ basierter Socialbot, der die meisten Antworten mithilfe des englischen DialoGPT-Modells generiert. Es enthält außerdem Intent-Catcher- und Responder-Komponenten, um spezielle Benutzerwünsche abzudecken. Link zur Distribution.
Russische Version von DeepPavlov Dream Socialbot. Dies ist ein generativ-basierter Socialbot, der Russian DialoGPT von DeepPavlov verwendet, um die meisten Antworten zu generieren. Es enthält außerdem Intent-Catcher- und Responder-Komponenten, um spezielle Benutzerwünsche abzudecken. Link zur Distribution.
Mini-Version von DeepPavlov Dream Socialbot unter Verwendung von auf Eingabeaufforderungen basierenden generativen Modellen. Hierbei handelt es sich um einen generativ basierten Socialbot, der große Sprachmodelle verwendet, um die meisten Antworten zu generieren. Sie können Ihre eigenen Eingabeaufforderungen (JSON-Dateien) in common/prompts hochladen, Eingabeaufforderungsnamen zu PROMPTS_TO_CONSIDER hinzufügen (durch Kommas getrennt), und die bereitgestellten Informationen werden bei der LLM-basierten Antwortgenerierung als Eingabeaufforderung verwendet. Link zur Distribution.
docker -Version ab 20;docker-compose v1.29.2; git clone https://github.com/deeppavlov/dream.git
Wenn Sie beim Ausführen von Docker-Compose die Fehlermeldung „Berechtigung verweigert“ erhalten, stellen Sie sicher, dass Sie Ihren Docker-Benutzer richtig konfigurieren.
docker-compose -f docker-compose.yml -f assistant_dists/deepy_base/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_adv/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_faq/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_gobot_base/docker-compose.override.yml up --build
Der einfachste Weg, Dream auszuprobieren, besteht darin, es über einen Proxy bereitzustellen. Alle Anfragen werden an die DeepPavlov-API umgeleitet, sodass Sie keine lokalen Ressourcen verwenden müssen. Einzelheiten finden Sie unter Proxy-Nutzung.
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/proxy.yml up --build
Bitte beachten Sie, dass DeepPavlov Dream-Komponenten viele Ressourcen benötigen. Den geschätzten Bedarf finden Sie im Abschnitt „Komponenten“.
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml up --build
Wir haben auch eine Konfiguration mit GPU-Zuteilungen für Umgebungen mit mehreren GPUs eingefügt:
AGENT_PORT=4242 docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/test.yml up
Wenn Sie einen bestimmten Docker-Container ohne Neuerstellung neu starten müssen (stellen Sie sicher, dass die Zuordnung in assistant_dists/dream/dev.yml korrekt ist):
AGENT_PORT=4242 docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml restart container-name
docker-compose -f docker-compose.yml -f assistant_dists/dream_persona_prompted/docker-compose.override.yml -f assistant_dists/dream_persona_prompted/dev.yml -f assistant_dists/dream_persona_prompted/proxy.yml up --build
Wir haben auch eine Konfiguration mit GPU-Zuweisungen für Umgebungen mit mehreren GPUs hinzugefügt.
DeepPavlov Agent bietet mehrere Optionen für die Interaktion: eine Befehlszeilenschnittstelle, eine HTTP-API und einen Telegram-Bot
Führen Sie in einem separaten Terminal-Tab Folgendes aus:
docker-compose exec agent python -m deeppavlov_agent.run agent.channel=cmd agent.pipeline_config=assistant_dists/dream/pipeline_conf.json
Geben Sie Ihren Benutzernamen ein und chatten Sie mit Dream!
Sobald Sie den Bot gestartet haben, wird die Agent-API von DeepPavlov auf http://localhost:4242 ausgeführt. Weitere Informationen zur API finden Sie in den DeepPavlov Agent Docs.
Eine einfache Chat-Oberfläche wird unter http://localhost:4242/chat verfügbar sein.
Derzeit wird der Telegram-Bot anstelle der HTTP-API bereitgestellt. Bearbeiten Sie command agent docker-compose.override.yml -Konfiguration:
agent:
command: sh -c 'bin/wait && python -m deeppavlov_agent.run agent.channel=telegram agent.telegram_token=<TELEGRAM_BOT_TOKEN> agent.pipeline_config=assistant_dists/dream/pipeline_conf.json'
HINWEIS: Behandeln Sie Ihr Telegram-Token als Geheimnis und übergeben Sie es nicht an öffentliche Repositories!
Dream verwendet mehrere Docker-Compose-Konfigurationsdateien:
./docker-compose.yml ist die Kernkonfiguration, die Container für DeepPavlov Agent und Mongo-Datenbank enthält;
./assistant_dists/*/docker-compose.override.yml listet alle Komponenten für die Verteilung auf;
./assistant_dists/dream/dev.yml enthält Volume-Bindungen für ein einfacheres Dream-Debugging;
./assistant_dists/dream/proxy.yml ist eine Liste von Proxy-Containern.
Wenn Ihre Bereitstellungsressourcen begrenzt sind, können Sie Container durch ihre von DeepPavlov gehosteten Proxy-Kopien ersetzen. Überschreiben Sie dazu diese Containerdefinitionen in proxy.yml , z. B.:
convers-evaluator-annotator:
command: ["nginx", "-g", "daemon off;"]
build:
context: dp/proxy/
dockerfile: Dockerfile
environment:
- PROXY_PASS=proxy.deeppavlov.ai:8004
- SERVICE_PORT=8004
und fügen Sie diese Konfiguration in Ihren Bereitstellungsbefehl ein:
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/proxy.yml up --build
proxy.yml enthält standardmäßig alle verfügbaren Proxy-Definitionen.
Traumarchitektur wird im folgenden Bild dargestellt: 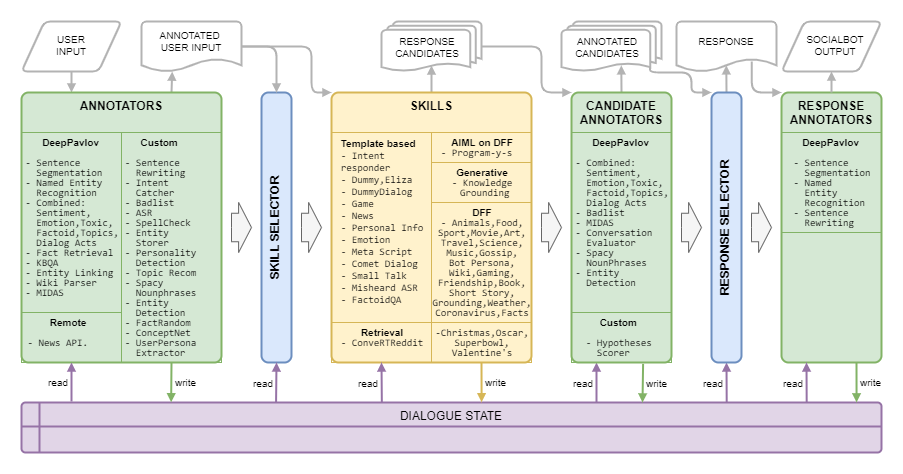
| Name | Anforderungen | Beschreibung |
|---|---|---|
| Regelbasierter Selektor | Algorithmus, der eine Liste von Fähigkeiten auswählt, um Kandidatenantworten auf den aktuellen Kontext basierend auf Themen, Entitäten, Emotionen, Toxizität, Dialoghandlungen und Dialogverlauf zu generieren | |
| Antwortauswahl | 50 MB RAM | Algorithmus, der eine endgültige Antwort aus der gegebenen Liste der Kandidatenantworten auswählt |
| Name | Anforderungen | Beschreibung |
|---|---|---|
| ASR | 40 MB RAM | berechnet die allgemeine ASR-Konfidenz für eine bestimmte Äußerung und bewertet sie entweder als sehr niedrig , niedrig , mittel oder hoch (für Amazon-Markup). |
| Auf der Badliste stehende Wörter | 150 MB RAM | erkennt Wörter und Phrasen aus der Badlist |
| Kombinierte Klassifizierung | 1,5 GB RAM, 3,5 GB GPU | BERT-basiertes Modell einschließlich Themenklassifizierung, Klassifizierung von Dialogakten, Stimmung, Toxizität, Emotion und Faktenklassifizierung |
| Kombinierte Klassifizierung Leichtgewicht | 1,6 GB RAM | Das gleiche Modell wie die kombinierte Klassifizierung, benötigt jedoch dank des leichteren Rückgrats 42 % weniger Zeit |
| COMeT Atomic | 2 GB RAM, 1,1 GB GPU | Commonsense-Vorhersagemodelle COMeT Atomic |
| COMeT ConceptNet | 2 GB RAM, 1,1 GB GPU | Commonsense-Vorhersagemodelle COMeT ConceptNet |
| Convers Evaluator Annotator | 1 GB RAM, 4,5 GB GPU | wird anhand der Alexa-Preisdaten aus früheren Wettbewerben trainiert und sagt voraus, ob die Antwort des Kandidaten interessant, verständlich, themenbezogen, ansprechend oder fehlerhaft ist |
| Emotionsklassifizierung | 2,5 GB RAM | Annotator zur Emotionsklassifizierung |
| Entitätserkennung | 1,5 GB RAM, 3,2 GB GPU | extrahiert Entitäten und ihre Typen aus Äußerungen |
| Entitätsverknüpfung | 2,5 GB RAM, 1,3 GB GPU | findet Wikidata-Entitäts-IDs für die mit der Entitätserkennung erkannten Entitäten |
| Entitätsspeicher | 220 MB RAM | eine regelbasierte Komponente, die Entitäten aus den Äußerungen des Benutzers und des Socialbots speichert, wenn Meinungsäußerungen mit Mustern oder dem MIDAS-Klassifikator erkannt werden, und diese zusammen mit der erkannten Einstellung zum Dialogstatus speichert |
| Tatsache zufällig | 50 MB RAM | gibt zufällige Fakten für die angegebene Entität zurück (für Entitäten aus Benutzeräußerungen) |
| Faktenbeschaffung | 7,4 GB RAM, 1,2 GB GPU | extrahiert Fakten aus Wikipedia und wikiHow |
| Absichtsfänger | 1,7 GB RAM, 2,4 GB GPU | klassifiziert Benutzeräußerungen in eine Reihe vordefinierter Absichten, die anhand einer Reihe von Phrasen und regulären Ausdrücken trainiert werden |
| KBQA | 2 GB RAM, 1,4 GB GPU | Beantwortet die sachlichen Fragen des Benutzers basierend auf Wikidata KB |
| MIDAS-Klassifizierung | 1,1 GB RAM, 4,5 GB GPU | BERT-basiertes Modell, das auf einer Teilmenge semantischer Klassen des MIDAS-Datensatzes trainiert wurde |
| MIDAS-Prädiktor | 30 MB RAM | BERT-basiertes Modell, das auf einer Teilmenge semantischer Klassen des MIDAS-Datensatzes trainiert wurde |
| NER | 2,2 GB RAM, 5 GB GPU | Extrahiert Personennamen, Namen von Orten und Organisationen aus Text ohne Großschreibung |
| News-API-Annotator | 80 MB RAM | Extrahiert die neuesten Nachrichten zu Entitäten oder Themen mithilfe der GNews-API. DeepPavlov Dream-Bereitstellungen nutzen unseren eigenen API-Schlüssel. |
| Persönlichkeitsfänger | 30 MB RAM | Die Fähigkeit besteht darin, die Persönlichkeitsbeschreibung des Systems über die Chat-Schnittstelle zu ändern. Sie funktioniert als Systembefehl und die Antwort ist eine systemähnliche Nachricht |
| Eingabeaufforderungsauswahl | 50 MB RAM | Annotator verwendet Satzranker, um Eingabeaufforderungen zu ordnen und N_SENTENCES_TO_RETURN relevanteste Eingabeaufforderungen auszuwählen (basierend auf den in Eingabeaufforderungen bereitgestellten Fragen). |
| Eigentumsextraktion | 6,3 GiB RAM | Extrahiert Benutzerattribute aus Äußerungen |
| Rake-Schlüsselwörter | 40 MB RAM | extrahiert mithilfe des RAKE-Algorithmus Schlüsselwörter aus Äußerungen |
| Relativer Persona-Extraktor | 50 MB RAM | Annotator verwendet Sentence Ranker, um Persona-Sätze zu ordnen und N_SENTENCES_TO_RETURN die relevantesten Sätze auszuwählen |
| Sentrewrite | 200 MB RAM | schreibt die Äußerungen des Benutzers um, indem Pronomen durch spezifische Namen ersetzt werden, die nachgeschalteten Komponenten nützlichere Informationen liefern |
| Sentseg | 1 GB RAM | ermöglicht es uns, lange und komplexe Benutzeräußerungen zu verarbeiten, indem wir sie in Sätze aufteilen und die Zeichensetzung wiederherstellen |
| Spacy Nounphrases | 180 MB RAM | extrahiert Nominalphrasen mit Spacy und filtert generische heraus |
| Sprachfunktionsklassifikator | 1,1 GB RAM, 4,5 GB GPU | ein hierarchischer Algorithmus basierend auf mehreren linearen Modellen und einem regelbasierten Ansatz zur Vorhersage von Sprachfunktionen, beschrieben von Eggins und Slade |
| Sprachfunktionsprädiktor | 1,1 GB RAM, 4,5 GB GPU | liefert Wahrscheinlichkeiten von Sprachfunktionen, die einer vom Speech Function Classifier vorhergesagten Sprachfunktion folgen können |
| Vorverarbeitung der Rechtschreibung | 50 MB RAM | Musterbasierte Komponente, um verschiedene umgangssprachliche Ausdrücke in einen formelleren Gesprächsstil umzuschreiben |
| Themenempfehlung | 40 MB RAM | Bietet ein Thema für weitere Gespräche unter Verwendung der Informationen zu den besprochenen Themen und den Präferenzen des Benutzers. Die aktuelle Version basiert auf Reddit-Persönlichkeiten (siehe Traumbericht für Alexa-Preis 4). |
| Einstufung als giftig | 3,5 GB RAM, 3 GB GPU | Toxisches Klassifizierungsmodell von Transformers, angegeben als PRETRAINED_MODEL_NAME_OR_PATH |
| Benutzer-Persona-Extraktor | 40 MB RAM | Bestimmt anhand einiger Schlüsselwörter, zu welcher Alterskategorie der Benutzer gehört |
| Wiki-Parser | 100 MB RAM | extrahiert Wikidata-Triplets für die mit Entity Linking erkannten Entitäten |
| Wiki-Fakten | 1,7 GB RAM | Modell, das verwandte Fakten aus Wikipedia- und WikiHow-Seiten extrahiert |
| Name | Anforderungen | Beschreibung |
|---|---|---|
| DialoGPT | 1,2 GB RAM, 2,1 GB GPU | Generativer Dienst basierend auf dem generativen Modell von Transformers. Das Modell wird im Docker-Compose-Argument PRETRAINED_MODEL_NAME_OR_PATH festgelegt (z. B. microsoft/DialoGPT-small mit 0,2–0,5 Sek. auf der GPU). |
| DialoGPT Persona-basiert | 1,2 GB RAM, 2,1 GB GPU | Generativer Dienst basierend auf dem generativen Modell von Transformers. Das Modell wurde anhand des PersonaChat-Datensatzes vorab trainiert, um eine Antwort zu generieren, die von mehreren Sätzen der Persona des Socialbots abhängig ist |
| Bildunterschrift | 4 GB RAM, 5,4 GB GPU | Erstellt eine Textdarstellung eines empfangenen Bildes |
| Füllung | 1 GB RAM, 1,2 GB GPU | (ausgeschaltet, aber der Code ist verfügbar) generativer Dienst basierend auf dem Infilling-Modell, der für die gegebene Äußerung eine Äußerung zurückgibt, bei der _ aus dem Originaltext durch generierte Token ersetzt wird |
| Wissensvermittlung | 2 GB RAM, 2,1 GB GPU | Generativer Dienst basierend auf der BlenderBot-Architektur, der eine Antwort auf den Kontext unter Berücksichtigung eines zusätzlichen Textabsatzes bereitstellt |
| Maskierter LM | 1,1 GB RAM, 1 GB GPU | (ausgeschaltet, aber der Code ist verfügbar) |
| Seq2seq Persona-basiert | 1,5 GB RAM, 1,5 GB GPU | Generativer Dienst basierend auf dem seq2seq-Modell von Transformers. Das Modell wurde auf dem PersonaChat-Datensatz vorab trainiert, um eine Antwort zu generieren, die von mehreren Sätzen der Persona des Socialbots abhängig ist |
| Satzrangierer | 1,2 GB RAM, 2,1 GB GPU | Ranking-Modell, angegeben als PRETRAINED_MODEL_NAME_OR_PATH , das für ein Satzpaar einen Float-Score der Korrespondenz zurückgibt |
| StoryGPT | 2,6 GB RAM, 2,15 GB GPU | Generativer Dienst basierend auf fein abgestimmtem GPT-2, der für den gegebenen Satz von Schlüsselwörtern eine Kurzgeschichte mit den Schlüsselwörtern zurückgibt |
| GPT-3.5 | 100 MB RAM | Generativer Dienst basierend auf dem OpenAI-API-Dienst, das Modell wird im Docker-Compose-Argument PRETRAINED_MODEL_NAME_OR_PATH festgelegt (insbesondere wird in diesem Dienst text-davinci-003 verwendet). |
| ChatGPT | 100 MB RAM | Generativer Dienst basierend auf dem OpenAI-API-Dienst, das Modell wird im Docker-Compose-Argument PRETRAINED_MODEL_NAME_OR_PATH festgelegt (insbesondere wird in diesem Dienst gpt-3.5-turbo verwendet). |
| Prompt StoryGPT | 3 GB RAM, 4 GB GPU | Generativer Dienst basierend auf fein abgestimmtem GPT-2, der für das durch ein Substantiv dargestellte gegebene Thema eine Kurzgeschichte zu einem gegebenen Thema zurückgibt |
| GPT-J 6B | 1,5 GB RAM, 24,2 GB GPU | Generativer Dienst basierend auf dem generativen Transformers-Modell. Das Modell wird im Docker-Compose-Argument PRETRAINED_MODEL_NAME_OR_PATH festgelegt (insbesondere wird in diesem Dienst das GPT-J-Modell verwendet). |
| BLOOMZ 7B | 2,5 GB RAM, 29 GB GPU | Generativer Dienst basierend auf dem generativen Transformers-Modell. Das Modell wird im Docker-Compose-Argument PRETRAINED_MODEL_NAME_OR_PATH festgelegt (insbesondere wird in diesem Dienst das BLOOMZ-7b1-Modell verwendet). |
| GPT-JT 6B | 2,5 GB RAM, 25,1 GB GPU | Generativer Dienst basierend auf dem generativen Transformers-Modell. Das Modell wird im Docker-Compose-Argument PRETRAINED_MODEL_NAME_OR_PATH festgelegt (insbesondere wird in diesem Dienst das GPT-JT-Modell verwendet). |
| Name | Anforderungen | Beschreibung |
|---|---|---|
| Alexa Handler | 30 MB RAM | Handler für mehrere spezifische Alexa-Befehle |
| Weihnachtskompetenz | 30 MB RAM | unterstützt FAQ, Fakten und Skripte für Weihnachten |
| Komet-Dialogfähigkeit | 300 MB RAM | verwendet das COMeT ConceptNet-Modell, um eine Meinung auszudrücken, eine Frage zu stellen oder einen Kommentar zu den im Dialog erwähnten Benutzeraktionen abzugeben |
| Konvertieren Sie Reddit | 1,2 GB RAM | verwendet einen ConveRT-Encoder, um effiziente Darstellungen für Sätze zu erstellen |
| Dummy-Fähigkeit | ein Teil des Agentencontainers | eine Fallback-Fähigkeit mit mehreren ungiftigen Kandidatenantworten |
| Dummy-Skill-Dialog | 600 MB RAM | gibt die nächste Runde aus dem Topical-Chat-Datensatz zurück, wenn die Antwort des Benutzers auf den Dummy-Skill der entsprechenden Antwort in den Quelldaten ähnelt |
| Eliza | 30 MB RAM | Chatbot (https://github.com/wadetb/eliza) |
| Emotionsfähigkeit | 40 MB RAM | Gibt Vorlagenantworten auf Emotionen zurück, die von der Emotionsklassifizierung aus dem Combined Classification-Annotator erkannt wurden |
| Faktoide Qualitätssicherung | 170 MB RAM | beantwortet sachliche Fragen |
| Spielkooperative Fähigkeit | 100 MB RAM | Bietet dem Benutzer ein Gespräch über Computerspiele: die Charts der besten Spiele des vergangenen Jahres, des vergangenen Monats und der letzten Woche |
| Wartungsfertigkeit für Erntemaschinen | 30 MB RAM | Fertigkeit für die Wartung von Erntemaschinen |
| Gobot-Fertigkeit für Erntemaschinenwartung | 30 MB RAM | Wartung von Erntemaschinen. Zielorientierte Kompetenz |
| Fähigkeit zur Wissensvermittlung | 100 MB RAM | generiert eine Antwort basierend auf dem Dialogverlauf und dem bereitgestellten Wissen zum aktuellen Gesprächsthema |
| Meta-Script-Fähigkeit | 150 MB RAM | bietet einen mehrstufigen Dialog über menschliche Aktivitäten. Der Skill nutzt das COMeT-Atommodell, um vernünftige Beschreibungen und Fragen zu verschiedenen Aspekten zu generieren |
| ASR falsch verstanden | 40 MB RAM | verwendet die Anmerkungen des ASR-Prozessors, um dem Benutzer Feedback zu geben, wenn die ASR-Konfidenz zu niedrig ist |
| News-API-Fähigkeit | 60 MB RAM | präsentiert die am besten bewerteten neuesten Nachrichten zu Entitäten oder Themen mithilfe der GNews-API |
| Oscar-Fähigkeit | 30 MB RAM | unterstützt FAQ, Fakten und Skripte für Oscar |
| Persönliche Info-Fähigkeit | 40 MB RAM | fragt den Namen, den Geburtsort und den Standort des Benutzers ab und speichert diese |
| DFF-Programm Y-Fähigkeit | 800 MB RAM | [Neue DFF-Version] Chatbot-Programm Y (https://github.com/keiffster/program-y) angepasst für Dream Socialbot |
| DFF-Programm Y Gefährliche Fähigkeit | 100 MB RAM | [Neue DFF-Version] Chatbot-Programm Y (https://github.com/keiffster/program-y), angepasst für Dream Socialbot, enthält Antworten auf gefährliche Situationen in einem Dialog |
| DFF-Programm und breite Kompetenz | 110 MB RAM | [Neue DFF-Version] Chatbot-Programm Y (https://github.com/keiffster/program-y), angepasst für Dream Socialbot, das nur sehr allgemeine Vorlagen enthält (mit geringerer Zuverlässigkeit) |
| Smalltalk-Fähigkeit | 35 MB RAM | stellt anhand der handgeschriebenen Skripte Fragen zu 25 Themen, darunter unter anderem Liebe, Sport, Arbeit, Haustiere usw. |
| SuperBowl-Fähigkeit | 30 MB RAM | unterstützt FAQ, Fakten und Skripte für SuperBowl |
| Text-Qualitätssicherung | 1,8 GB RAM, 2,8 GB GPU | Der Dienst findet die Antwort auf eine faktische Frage im Text. |
| Valentinstag-Fähigkeit | 30 MB RAM | unterstützt FAQ, Fakten und Skripte zum Valentinstag |
| Wikidata-Wählfähigkeit | 100 MB RAM | generiert eine Äußerung mithilfe von Wikidata-Tripletts. Nicht eingeschaltet, verbesserungswürdig |
| DFF-Tiere-Fertigkeit | 200 MB RAM | wird mit DFF erstellt und verfügt über drei Gesprächszweige über Tiere: Haustiere des Benutzers, Haustiere des Socialbots und wilde Tiere |
| DFF-Kunstfertigkeit | 100 MB RAM | DFF-basierte Fähigkeit, Kunst zu diskutieren |
| DFF-Buchkompetenz | 400 MB RAM | [Neue DFF-Version] erkennt Buchtitel und Autoren, die in der Äußerung des Benutzers erwähnt werden, mit Hilfe von Wiki-Parser und Entity-Linking und empfiehlt Bücher durch Nutzung von Informationen aus der GoodReads-Datenbank |
| DFF-Bot-Persona-Fähigkeit | 150 MB RAM | Ziel ist es, Benutzerfavoriten und die 20 beliebtesten Dinge mit Kurzgeschichten zu diskutieren, in denen die Meinung des Socialbots dazu zum Ausdruck gebracht wird |
| DFF-Coronavirus-Fähigkeit | 110 MB RAM | [Neue DFF-Version] ruft Daten über die Anzahl der Coronavirus-Fälle und Todesfälle an verschiedenen Orten ab, die vom John Hopkins University Center for System Science and Engineering stammen |
| DFF-Lebensmittelkompetenz | 150 MB RAM | Entwickelt mit DFF, um Gespräche über Essen anzuregen |
| DFF-Freundschaftsfähigkeit | 100 MB RAM | [Neue DFF-Version] DFF-basierter Skill, um den Benutzer am Anfang des Dialogs zu begrüßen und ihn an einen Skript-Skill weiterzuleiten |
| DFF Funfact-Fähigkeit | 100 MB RAM | [Neue DFF-Version] Erzählt dem Benutzer unterhaltsame Fakten |
| DFF-Gaming-Fähigkeit | 80 MB RAM | Bietet eine Diskussion über Videospiele. „Gaming Skill“ ist für allgemeinere Gespräche über Videospiele gedacht |
| DFF-Klatsch-Fähigkeit | 95 MB RAM | DFF-basierte Fähigkeit, andere Menschen mit Neuigkeiten über sie zu besprechen |
| DFF-Bildkompetenz | 100 MB RAM | [Neue DFF-Version] Skriptbasierte Fähigkeit, die basierend auf den gesendeten Bildunterschriften (aus Anmerkungen) mit bestimmten Antworten reagiert, wenn Lebensmittel, Tiere oder Personen erkannt werden, und ansonsten mit Standardantworten |
| DFF-Vorlagenfähigkeit | 50 MB RAM | [Neue DFF-Version] DFF-basierter Skill, der ein Beispiel für die DFF-Nutzung bietet |
| DFF-Vorlagengesteuerter Skill | 50 MB RAM | [Neue DFF-Version] DFF-basierter Skill, der Antworten bereitstellt, die vom Sprachmodell basierend auf angegebenen Eingabeaufforderungen und dem Dialogkontext generiert werden. Das zu verwendende Modell wird in GENERATIVE_SERVICE_URL angegeben. Sie können beispielsweise den Transformer LM GPTJ-Dienst verwenden. |
| DFF-Erdungsfähigkeit | 90 MB RAM | [Neue DFF-Version] DFF-basierte Fähigkeit, das Gesprächsthema zu beantworten, Bestätigung zu generieren und universelle Antworten auf einige Dialoghandlungen von MIDAS zu generieren |
| DFF-Intent-Responder | 100 MB RAM | [Neue DFF-Version] bietet vorlagenbasierte Antworten für einige der vom Intent Catcher-Annotator erkannten Absichten |
| DFF-Filmkompetenz | 1,1 GB RAM | wird mit DFF implementiert und kümmert sich um die Konversationen rund um Filme |
| DFF-Musikkompetenz | 70 MB RAM | DFF-basierte Fähigkeit, über Musik zu diskutieren |
| DFF-Wissenschaftsfähigkeit | 90 MB RAM | DFF-basierte Fähigkeit, Wissenschaft zu diskutieren |
| DFF-Kurzgeschichtenfähigkeit | 90 MB RAM | [Neue DFF-Version] erzählt Benutzer-Kurzgeschichten aus drei Kategorien: (1) Gute-Nacht-Geschichten wie Fabeln und Moralgeschichten, (2) Horrorgeschichten und (3) lustige Geschichten |
| DFF-Sportkompetenz | 70 MB RAM | DFF-basierte Fähigkeit, über Sport zu diskutieren |
| DFF-Reisefähigkeit | 70 MB RAM | DFF-basierte Fähigkeit, über Reisen zu sprechen |
| DFF-Wetterfähigkeit | 1,4 GB RAM | [Neue DFF-Version] nutzt den OpenWeatherMap-Dienst, um die Vorhersage für den Standort des Benutzers abzurufen |
| DFF-Wiki-Fähigkeit | 150 MB RAM | Wird zum Erstellen von Szenarien mit der Extraktion von Entitäten, dem Füllen von Slots, dem Einfügen von Fakten und Bestätigungen verwendet |
| Name | Anforderungen | Beschreibung |
|---|---|---|
| KI-FAQ-Fähigkeit | 150 MB RAM | [Neue DFF-Version] Alles, was Sie über moderne KI wissen wollten, aber nicht zu fragen wagten! Dieser FAQ-Assistent chattet mit Ihnen und erklärt die einfachsten Themen aus der heutigen Technologiewelt. |
| Fähigkeiten als Modestylist | 150 MB RAM | [Neue DFF-Version] Bleiben Sie zu jeder Jahreszeit geschützt mit dem da Costa Industries Clothes Assistant! Erleben Sie ultimativen Komfort und Schutz, egal bei welchem Wetter. Bleiben Sie im Winter warm und... |
| Traumpersona-Fähigkeit | 150 MB RAM | [Neue DFF-Version] Auf Eingabeaufforderungen basierende Fähigkeit, die einen bestimmten generativen Dienst nutzt, um Antworten basierend auf der angegebenen Eingabeaufforderung zu generieren |
| Marketingfähigkeiten | 150 MB RAM | [Neue DFF-Version] Verbinden Sie sich mit Ihrem Publikum wie nie zuvor mit dem Marketing AI Assistant! Erreichen Sie neue Erfolgshöhen, indem Sie die Kraft der Empathie nutzen. Verabschieden Sie sich.. |
| Märchenhafte Fähigkeit | 150 MB RAM | [Neue DFF-Version] Dieser Assistent erzählt Ihnen oder Ihren Kindern ein kurzes, aber spannendes Märchen. Wählen Sie die Charaktere und das Thema und überlassen Sie den Rest der Fantasie der KI. |
| Ernährungsfähigkeit | 150 MB RAM | [Neue DFF-Version] Entdecken Sie das Geheimnis gesunder Ernährung mit unserem KI-Assistenten! Finden Sie ganz einfach nahrhafte Lebensmitteloptionen für Sie und Ihre Lieben. Verabschieden Sie sich vom Essensstress und begrüßen Sie die Köstlichkeiten... |
| Life-Coaching-Fähigkeit | 150 MB RAM | [Neue DFF-Version] Schöpfen Sie Ihr volles Potenzial mit dem patentierten KI-Assistenten von Rhodes & Co aus! Erreichen Sie Höchstleistungen bei der Arbeit und zu Hause. Bringen Sie sich mühelos in Topform und begeistern Sie andere damit. |
Kuratov Y. et al. Technischer DREAM-Bericht zum Alexa-Preis 2019 // Proceedings zum Alexa-Preis. – 2020.
Baymurzina D. et al. Technischer DREAM-Bericht zum Alexa-Preis 4 // Proceedings zum Alexa-Preis. – 2021.
DeepPavlov Dream ist unter Apache 2.0 lizenziert.
Program-y (siehe dream/skills/dff_program_y_skill , dream/skills/dff_program_y_wide_skill , dream/skills/dff_program_y_dangerous_skill ) ist unter Apache 2.0 lizenziert. Eliza (siehe dream/skills/eliza ) ist unter der MIT-Lizenz lizenziert.
Um eine Zertifizierungs- xlsx -Datei mit Bot-Antworten zu erstellen, können Sie das Skript xlsx_responder.py verwenden, indem Sie es ausführen
docker-compose -f docker-compose.yml -f dev.yml exec -T -u $( id -u ) agent python3
utils/xlsx_responder.py --url http://0.0.0.0:4242
--input ' tests/dream/test_questions.xlsx '
--output ' tests/dream/output/test_questions_output.xlsx '
--cache tests/dream/output/test_questions_output_ $( date --iso-8601=seconds ) .json Stellen Sie sicher, dass alle Dienste bereitgestellt sind. --input – xlsx Datei mit Zertifizierungsfragen, --output – xlsx Datei mit Bot-Antworten, --cache – json , die ein detailliertes Markup enthält und für einen Cache verwendet wird.


