Okapi
1.0.0
Okapi
Auf Anweisungen abgestimmte große Sprachmodelle in mehreren Sprachen mit verstärkendem Lernen aus menschlichem Feedback
Dies ist das Repo für das Okapi-Framework, das Ressourcen und Modelle für die Instruktionsoptimierung für große Sprachmodelle (LLMs) mit Reinforcement Learning from Human Feedback (RLHF) in mehreren Sprachen vorstellt. Unser Framework unterstützt 26 Sprachen, darunter 8 Sprachen mit hohen Ressourcen, 11 Sprachen mit mittleren Ressourcen und 7 Sprachen mit geringen Ressourcen.
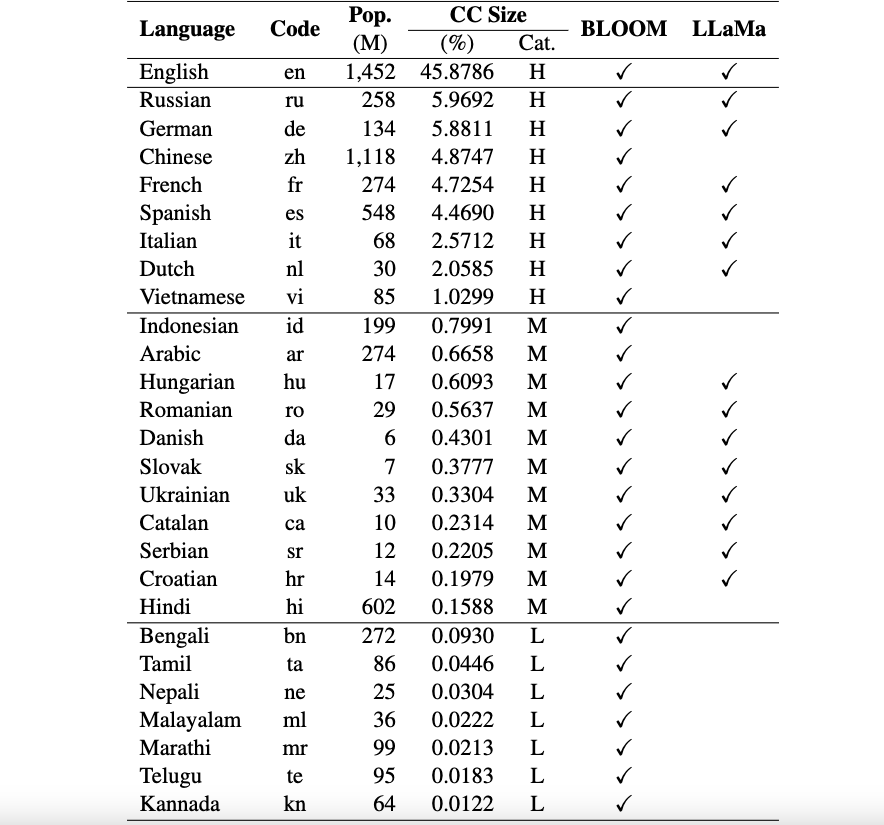
Okapi-Ressourcen : Wir stellen Ressourcen zur Durchführung der Instruktionsoptimierung mit RLHF für 26 Sprachen bereit, einschließlich ChatGPT-Eingabeaufforderungen, mehrsprachige Instruktionsdatensätze und mehrsprachige Antwortranking-Daten.
Okapi-Modelle : Wir bieten RLHF-basierte, anweisungsoptimierte LLMs für 26 Sprachen im Okapi-Datensatz. Unsere Modelle umfassen sowohl BLOOM-basierte als auch LLaMa-basierte Versionen. Wir stellen auch Skripte zur Interaktion mit unseren Modellen und zur Feinabstimmung von LLMs mit unseren Ressourcen bereit.
Mehrsprachige Evaluierungs-Benchmark-Datensätze : Wir stellen drei Benchmark-Datensätze zur Evaluierung mehrsprachiger großer Sprachmodelle (LLMs) für 26 Sprachen bereit. Auf die vollständigen Datensätze und Auswertungsskripte können Sie hier zugreifen.
Nutzungs- und Lizenzhinweise : Okapi ist nur für Forschungszwecke bestimmt und lizenziert. Bei den Datensätzen handelt es sich um CC BY NC 4.0 (die nur eine nichtkommerzielle Nutzung erlauben) und Modelle, die mit dem Datensatz trainiert wurden, sollten nicht außerhalb von Forschungszwecken verwendet werden.
Unser Fachpapier mit Evaluierungsergebnissen finden Sie hier.
Wir führen einen umfassenden Datenerfassungsprozess durch, um die notwendigen Daten für unser mehrsprachiges Framework Okapi in vier Hauptschritten vorzubereiten:
Um den gesamten Datensatz herunterzuladen, können Sie das folgende Skript verwenden:
bash scripts/download.shWenn Sie die Daten nur für eine bestimmte Sprache benötigen, können Sie den Sprachcode als Argument für das Skript angeben:
bash scripts/download.sh [LANG]
# For example, to download the dataset for Vietnamese: bash scripts/download.sh viNach dem Download finden Sie unsere freigegebenen Daten im Datensatzverzeichnis . Es beinhaltet:
multilingual-alpaca-52k : Die übersetzten Daten für 52K-Englischanleitungen in Alpaka in 26 Sprachen.
multilingual-ranking-data-42k : Die mehrsprachigen Antwortrankingdaten für 26 Sprachen. Für jede Sprache stellen wir 42.000 Anweisungen bereit; Jeder von ihnen hat 4 bewertete Antworten. Mit diesen Daten können Belohnungsmodelle für 26 Sprachen trainiert werden.
multilingual-rl-tuning-64k : Die mehrsprachigen Befehlsdaten für RLHF. Wir bieten 62.000 Anweisungen für jede der 26 Sprachen.
Mithilfe unserer Okapi-Datensätze und der RLHF-basierten Instruktionsoptimierungstechnik führen wir mehrsprachige, fein abgestimmte LLMs für 26 Sprachen ein, die auf den 7B-Versionen von LLaMA und BLOOM basieren. Die Modelle können hier von HuggingFace bezogen werden.
Okapi unterstützt interaktive Chats mit den mehrsprachigen, auf Anweisungen abgestimmten LLMs in 26 Sprachen. Befolgen Sie die folgenden Schritte für die Chats:
git clone https://github.com/nlp-uoregon/Okapi.git
cd Okapi
pip install -r requirements.txt
from chat import pipeline
model_path = 'uonlp/okapi-vi-bloom'
p = pipeline ( model_path , gpu = True )
instruction = 'Dịch câu sau sang Tiếng Việt' # Translate the following sentence into Vietnamese
prompt_input = 'The City of Eugene - a great city for the arts and outdoors. '
response = p . generate ( instruction = instruction , prompt_input = prompt_input )
print ( response )Wir stellen auch Skripte zur Feinabstimmung von LLMs mit unseren Befehlsdaten mithilfe von RLHF bereit, die drei Hauptschritte abdecken: überwachte Feinabstimmung, Belohnungsmodellierung und Feinabstimmung mit RLHF. Führen Sie die folgenden Schritte aus, um LLMs zu optimieren:
conda create -n okapi python=3.9
conda activate okapi
pip install -r requirements.txtbash scripts/supervised_finetuning.sh [LANG]bash scripts/reward_modeling.sh [LANG]bash scripts/rl_training.sh [LANG]Wenn Sie die Daten, das Modell oder den Code in diesem Repository verwenden, geben Sie bitte Folgendes an:
@article { dac2023okapi ,
title = { Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback } ,
author = { Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu } ,
journal = { arXiv e-prints } ,
pages = { arXiv--2307 } ,
year = { 2023 }
}

