Chinesisch-ChatBot/Chinesischer Chatbot
- Der Autor hat vollständig übertragen
GNN-Diagramm der Richtung des neuronalen Netzwerks Die C++-Entwicklung wird NLP nicht mehr weiterführen und der Projektcode wird nicht mehr gepflegt. Als das Yuanxiang-Projekt abgeschlossen war, gab es nur sehr wenige Online-Ressourcen. Der Autor kam aus einer Laune heraus zum ersten Mal mit NLP und Deep Learning in Berührung und schrieb schließlich dieses Spielzeugmodell. Daher weiß der Autor, dass es für Anfänger nicht einfach ist. Selbst wenn das Projekt nicht mehr gepflegt wird, werden Probleme oder E-Mails ([email protected]) zeitnah beantwortet, um Neulingen im Deep Learning zu helfen. (Die Version von Tensorflow, die ich verwende, ist zu alt. Wenn Sie die neue Version direkt ausführen, werden auf jeden Fall verschiedene Fehler angezeigt. Wenn Sie auf Schwierigkeiten stoßen, machen Sie sich nicht die Mühe, die alte Version der Umgebung zu installieren. Es wird empfohlen, Pytorch zu verwenden um es nach meiner Verarbeitungslogik zu rekonstruieren. Ich bin zu faul zum Schreiben.
- GNN-Aspekt:
- Eine Reihe von Benchmark-Vergleichsmodellen: GNNs-Baseline wurde angepasst und zusammengestellt, um eine schnelle Überprüfung von Ideen zu ermöglichen.
- Der Open-Source-Code meiner Arbeit ACMMM 2023 (CCF-A) ist hier LSTGM.
- Der Open-Source-Code meiner Arbeit ICDM 2023 (CCF-B) wird noch kompiliert. . . GRN
- Fellows sind herzlich eingeladen, etwas hinzuzufügen, zu kommunizieren und zu lernen.
Umgebungskonfiguration
| Programm | Version |
|---|
| Python | 3,68 |
| Tensorfluss | 1.13.1 |
| Keras | 2.2.4 |
| Windows10 | |
| Jupiter | |
Wichtigste Referenzmaterialien
- Abschlussarbeit „NEURALE MASCHINENÜBERSETZUNG DURCH GEMEINSAMES AUSRICHTEN UND ÜBERSETZEN LERNEN ( Zum Herunterladen auf den Titel klicken )“
- Aufmerksamkeitsstrukturdiagramm
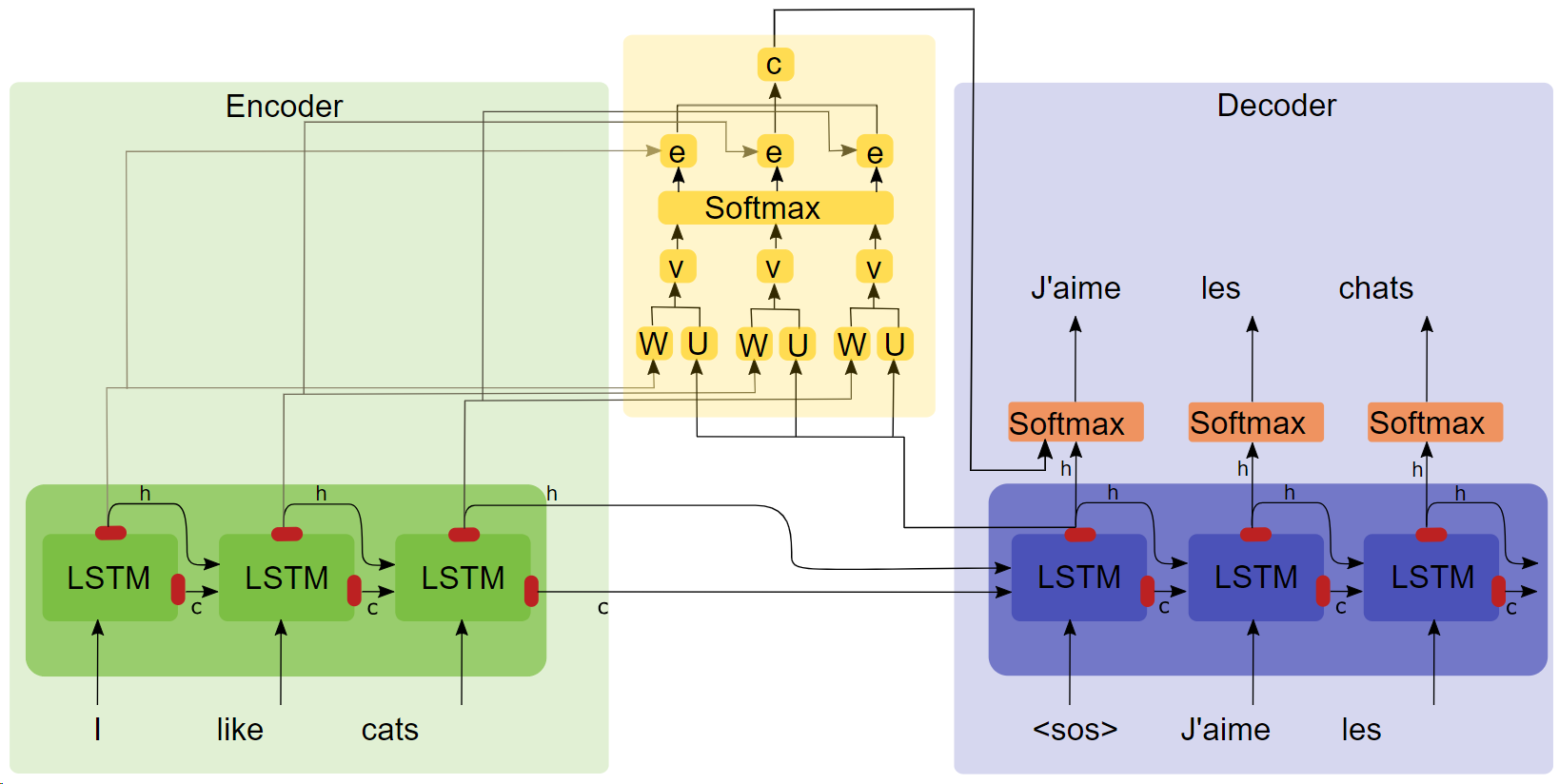
Wichtige Punkte
- LSTM
- seq2seq
- Aufmerksamkeitsexperimente zeigen, dass nach dem Hinzufügen des Aufmerksamkeitsmechanismus die Trainingsgeschwindigkeit schneller, die Konvergenz schneller und der Effekt besser ist.
Korpus und Trainingsumgebung
100.000 Dialoggruppen aus dem Qingyun-Korpus, geschult im Google-Kolabor.
laufen
Methode 1: Vorgang abschließen
- Datenvorverarbeitung
get_data
- Modelltraining
chatbot_train (Dies ist die in Google Colab gemountete Version, der lokale Laufpfad muss leicht geändert werden)
- Modellvorhersage
chatbot_inference_Attention
Methode 2: Laden Sie ein vorhandenes Modell
- Führen Sie
chatbot_inference_Attention aus
-
models/W--184-0.5949-.h5
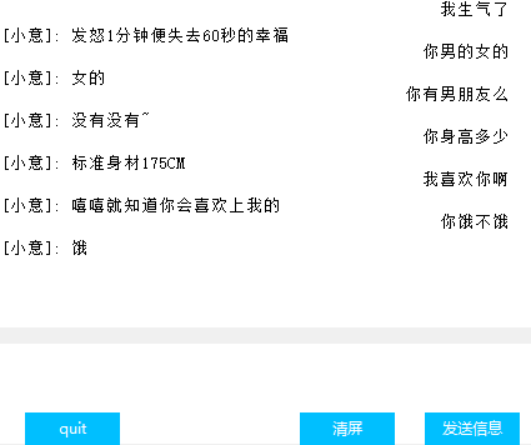
Schnittstelle (Tkinter)
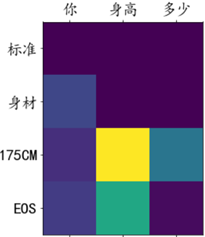
Visualisierung des Aufmerksamkeitsgewichts
andere
- In der Trainingsdatei chat_bot werden die ersten beiden der letzten drei Codeblöcke zum Mounten von Google Cloud Disk verwendet, und der letzte wird verwendet, um diese Verluste zu erhalten und das Zeichnen zu erleichtern. Ich weiß nicht, warum das Tensorbord in der Rückruffunktion verwendet wird funktioniert nicht, also habe ich mir diese Strategie ausgedacht;
- Der vorletzte Codeblock in der Vorhersagedatei verfügt nur über eine Texteingabe, aber keine Schnittstelle. Der letzte Codeblock ist die Schnittstelle. Einer der beiden Blöcke kann je nach Bedarf sofort ausgeführt werden.
- Der Code enthält viele Zwischenausgaben. Ich hoffe, dass dies Ihnen hilft, den Code zu verstehen.
- Es gibt ein Modell, das ich in Modellen trainiert habe. Im Normalbetrieb sollte es kein Problem sein. Sie können es auch selbst trainieren.
- Der Autor verfügt über begrenzte Fähigkeiten und hat keinen Indikator zur Quantifizierung des Dialogeffekts gefunden, sodass der Verlust nur grob den Trainingsfortschritt widerspiegeln kann.


