MELD
1.0.0
Wenn Sie sich für IQ-Tests von LLMs interessieren, schauen Sie sich unser neues Werk an: AlgoPuzzleVQA
Wir haben die mit Resnet extrahierten visuellen Funktionen veröffentlicht – https://github.com/declare-lab/MM-Align
Für aktualisierte Baselines besuchen Sie bitte diesen Link: conv-emotion
Zum Herunterladen der Daten verwenden Sie wget: wget http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz
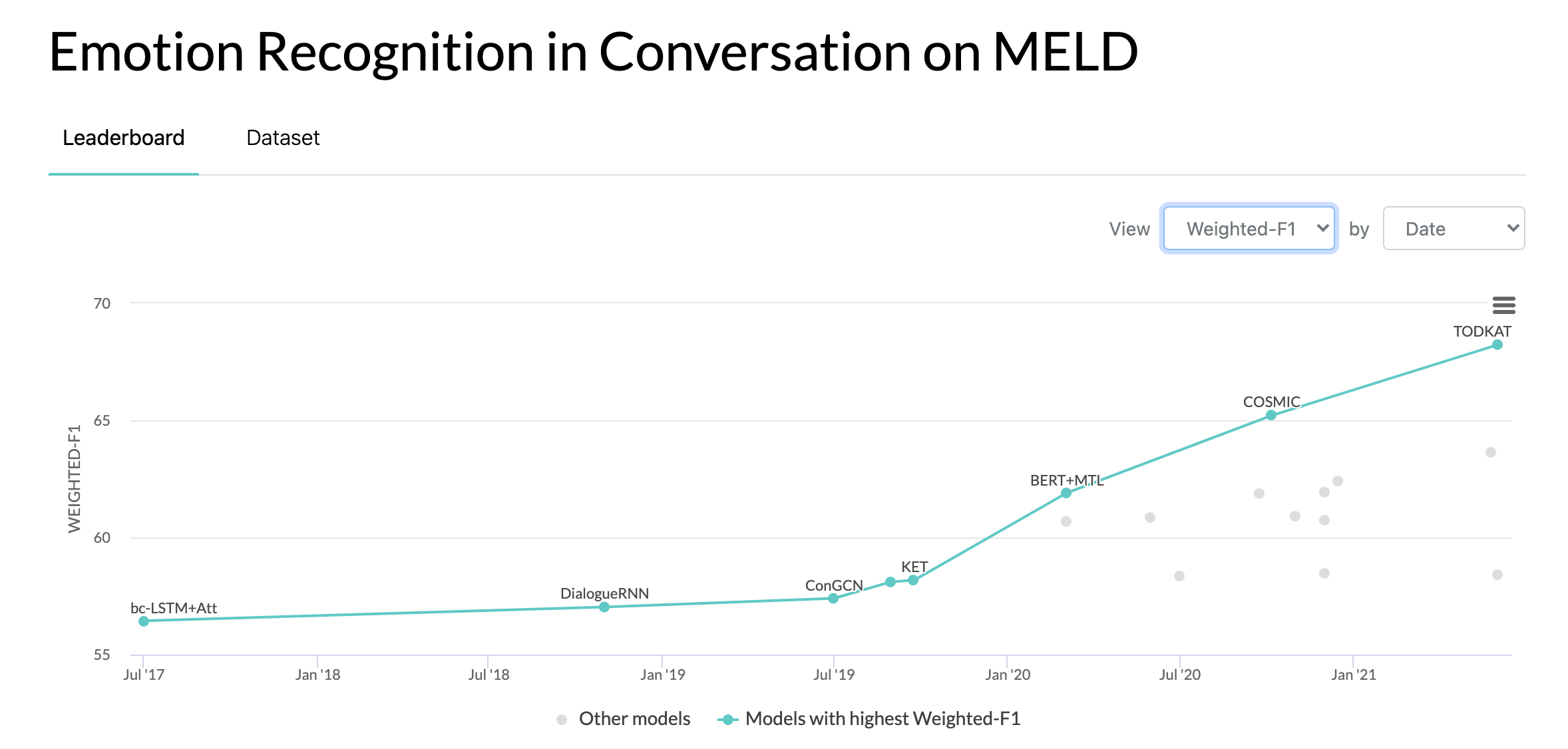
10.10.2020: Neues Papier und SOTA in Emotion Recognition in Conversations zum MELD-Datensatz. Den Code finden Sie im Verzeichnis COSMIC. Lesen Sie den Artikel – COSMIC: COMmonSense-Wissen für die Identifizierung von Emotionen in Gesprächen.
22.05.2019: MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversation wurde als vollständiges Paper auf der ACL 2019 angenommen. Das aktualisierte Paper finden Sie hier – https://arxiv.org/pdf/1810.02508. pdf
22.05.2019: Dyadic MELD wurde veröffentlicht. Es kann zum Testen dyadischer Gesprächsmodelle verwendet werden.
15.11.2018: Das Problem in train.tar.gz wurde behoben.
Zhang, Yazhou, Qiuchi Li, Dawei Song, Peng Zhang und Panpan Wang. „Quanteninspirierte interaktive Netzwerke für die Analyse der Konversationsstimmung.“ IJCAI 2019.
Zhang, Dong, Liangqing Wu, Changlong Sun, Shoushan Li, Qiaoming Zhu und Guodong Zhou. „Modellierung sowohl der kontext- als auch der sprechersensitiven Abhängigkeit zur Emotionserkennung in Gesprächen mit mehreren Sprechern.“ IJCAI 2019.
Ghosal, Deepanway, Navonil Majumder, Soujanya Poria, Niyati Chhaya und Alexander Gelbukh. „DialogueGCN: Ein Graph Convolutional Neural Network zur Emotionserkennung im Gespräch.“ EMNLP 2019.
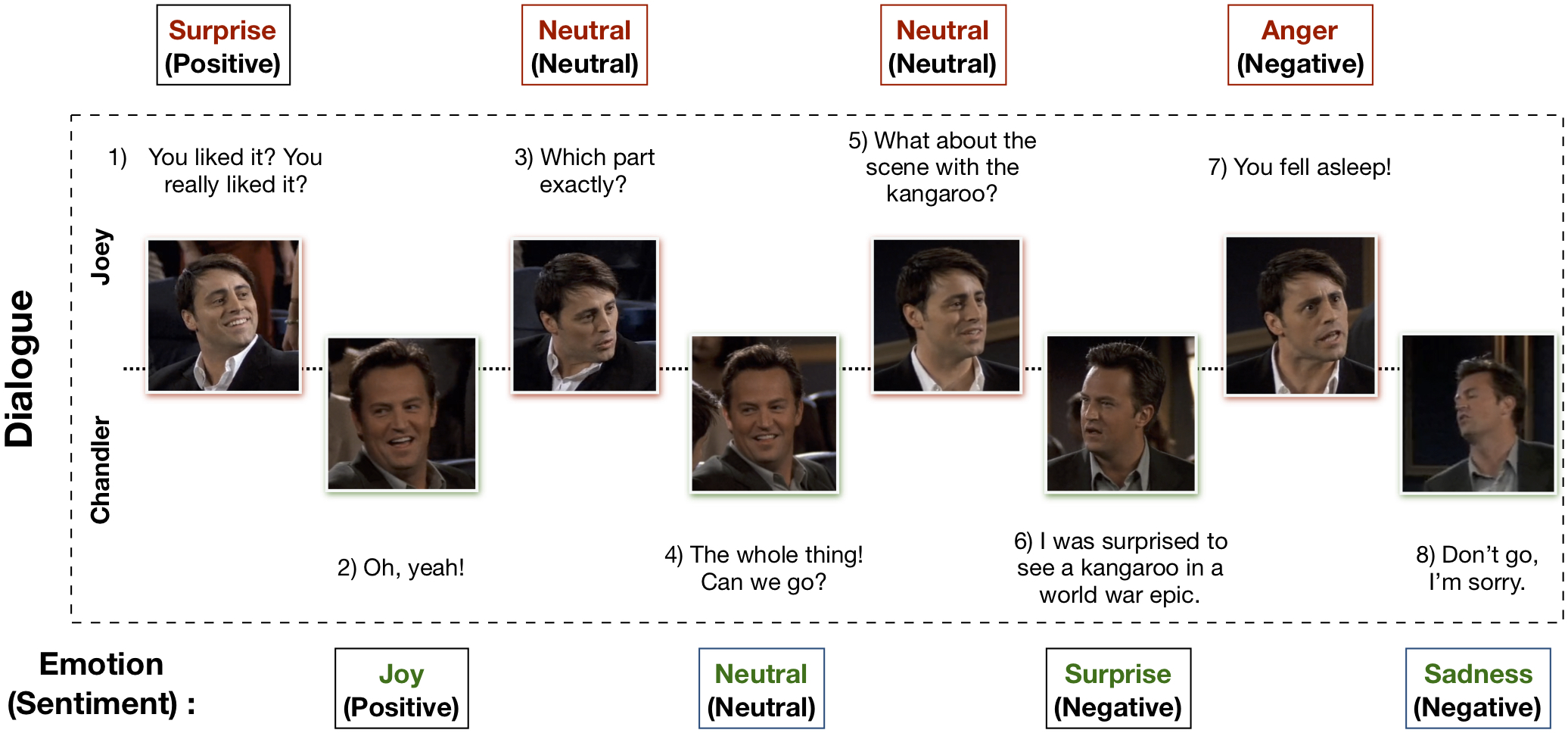
Der multimodale EmotionLines-Datensatz (MELD) wurde durch die Verbesserung und Erweiterung des EmotionLines-Datensatzes erstellt. MELD enthält die gleichen Dialoginstanzen wie EmotionLines, umfasst aber neben Text auch Audio- und visuelle Modalitäten. MELD verfügt über mehr als 1400 Dialoge und 13000 Äußerungen aus Friends-TV-Serien. An den Dialogen beteiligten sich mehrere Redner. Jeder Äußerung in einem Dialog wurde eine dieser sieben Emotionen zugeordnet: Wut, Ekel, Traurigkeit, Freude, Neutralität, Überraschung und Angst. MELD verfügt außerdem über Stimmungsanmerkungen (positiv, negativ und neutral) für jede Äußerung.
| Statistiken | Zug | Entwickler | Prüfen |
|---|---|---|---|
| Anzahl der Modalitäten | {a,v,t} | {a,v,t} | {a,v,t} |
| Anzahl einzigartiger Wörter | 10.643 | 2.384 | 4.361 |
| Durchschn. Äußerungslänge | 8.03 | 7,99 | 8.28 |
| Max. Äußerungslänge | 69 | 37 | 45 |
| Durchschn. Anzahl der Emotionen pro Dialog | 3.30 | 3.35 | 3.24 |
| Anzahl der Dialoge | 1039 | 114 | 280 |
| Anzahl der Äußerungen | 9989 | 1109 | 2610 |
| Anzahl der Lautsprecher | 260 | 47 | 100 |
| # der Emotionsverschiebung | 4003 | 427 | 1003 |
| Durchschn. Dauer einer Äußerung | 3,59s | 3,59s | 3,58s |
Weitere Informationen finden Sie unter https://affective-meld.github.io.
| Zug | Entwickler | Prüfen | |
|---|---|---|---|
| Wut | 1109 | 153 | 345 |
| Ekel | 271 | 22 | 68 |
| Furcht | 268 | 40 | 50 |
| Freude | 1743 | 163 | 402 |
| Neutral | 4710 | 470 | 1256 |
| Traurigkeit | 683 | 111 | 208 |
| Überraschung | 1205 | 150 | 281 |
Die multimodale Datenanalyse nutzt Informationen aus mehreren parallelen Datenkanälen für die Entscheidungsfindung. Mit dem rasanten Wachstum der KI hat die multimodale Emotionserkennung ein großes Forschungsinteresse erlangt, vor allem aufgrund ihrer potenziellen Anwendungen bei vielen anspruchsvollen Aufgaben wie der Dialoggenerierung, der multimodalen Interaktion usw. Ein System zur Erkennung von Gesprächsemotionen kann verwendet werden, um geeignete Antworten zu generieren Analyse der Benutzeremotionen. Obwohl es zahlreiche Arbeiten zur multimodalen Emotionserkennung gibt, konzentrieren sich nur sehr wenige tatsächlich auf das Verständnis von Emotionen in Gesprächen. Ihre Arbeit beschränkt sich jedoch nur auf das Verstehen dyadischer Gespräche und ist daher nicht auf die Emotionserkennung in Mehrparteiengesprächen mit mehr als zwei Teilnehmern skalierbar. EmotionLines kann nur als Ressource zur Emotionserkennung für Text verwendet werden, da es keine Daten aus anderen Modalitäten wie visuellen und akustischen Daten enthält. Gleichzeitig ist zu beachten, dass für die Emotionserkennungsforschung kein multimodaler Mehrparteien-Gesprächsdatensatz verfügbar ist. In dieser Arbeit haben wir den EmotionLines-Datensatz für das multimodale Szenario erweitert, verbessert und weiterentwickelt. Die Emotionserkennung in aufeinanderfolgenden Runden birgt mehrere Herausforderungen und das Kontextverständnis ist eine davon. Der Emotionswechsel und der Emotionsfluss in der Abfolge der Wendungen in einem Dialog machen eine genaue Kontextmodellierung zu einer schwierigen Aufgabe. Da wir in diesem Datensatz Zugriff auf die multimodalen Datenquellen für jeden Dialog haben, gehen wir davon aus, dass dadurch die Kontextmodellierung verbessert und somit die Gesamtleistung der Emotionserkennung verbessert wird. Dieser Datensatz kann auch zur Entwicklung eines multimodalen affektiven Dialogsystems verwendet werden. IEMOCAP und SEMAINE sind multimodale Konversationsdatensätze, die für jede Äußerung eine Emotionsbezeichnung enthalten. Allerdings sind diese Datensätze dyadischer Natur, was die Bedeutung unseres Multimodal-EmotionLines-Datensatzes rechtfertigt. Die anderen öffentlich verfügbaren multimodalen Datensätze zur Emotions- und Stimmungserkennung sind MOSEI, MOSI, MOUD. Allerdings handelt es sich bei keinem dieser Datensätze um Konversationsdaten.
Der erste Schritt besteht darin, den Zeitstempel jeder Äußerung in jedem der im EmotionLines-Datensatz vorhandenen Dialoge zu ermitteln. Um dies zu erreichen, haben wir die Untertiteldateien aller Episoden durchsucht, die den Anfangs- und Endzeitstempel der Äußerungen enthalten. Dieser Prozess ermöglichte es uns, Staffel-ID, Episoden-ID und Zeitstempel jeder Äußerung in der Episode zu erhalten. Beim Erhalten der Zeitstempel legen wir zwei Einschränkungen fest: (a) Zeitstempel der Äußerungen in einem Dialog müssen in aufsteigender Reihenfolge sein, (b) alle Äußerungen in einem Dialog müssen zur gleichen Episode und Szene gehören. Die Einschränkung dieser beiden Bedingungen ergab, dass in EmotionLines einige Dialoge aus mehreren natürlichen Dialogen bestehen. Wir haben diese Fälle aus dem Datensatz herausgefiltert. Aufgrund dieses Fehlerkorrekturschritts haben wir in unserem Fall eine unterschiedliche Anzahl von Dialogen im Vergleich zu den EmotionLines. Nachdem wir den Zeitstempel jeder Äußerung erhalten hatten, extrahierten wir die entsprechenden audiovisuellen Clips aus der Quellepisode. Unabhängig davon haben wir auch den Audioinhalt aus diesen Videoclips herausgenommen. Schließlich enthält der Datensatz visuelle, akustische und textliche Modalitäten für jeden Dialog.
Das Papier zur Erläuterung dieses Datensatzes finden Sie unter https://arxiv.org/pdf/1810.02508.pdf
Bitte besuchen Sie - http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz, um die Rohdaten herunterzuladen. Die Daten werden im MP4-Format gespeichert und sind in den Dateien XXX.tar.gz zu finden. Anmerkungen finden Sie unter https://github.com/declare-lab/MELD/tree/master/data/MELD.
| Spaltenname | Beschreibung |
|---|---|
| Sr. Nr. | Seriennummern der Äußerungen, hauptsächlich zur Referenzierung der Äußerungen bei unterschiedlichen Versionen oder mehreren Kopien mit unterschiedlichen Teilmengen |
| Äußerung | Einzelne Äußerungen aus EmotionLines als String. |
| Lautsprecher | Name des Sprechers, der mit der Äußerung verknüpft ist. |
| Emotion | Die Emotion (neutral, Freude, Traurigkeit, Wut, Überraschung, Angst, Ekel), die der Sprecher in der Äußerung zum Ausdruck bringt. |
| Gefühl | Die Stimmung (positiv, neutral, negativ), die der Sprecher in der Äußerung zum Ausdruck bringt. |
| Dialogue_ID | Der Index des Dialogs beginnend bei 0. |
| Utterance_ID | Der Index der jeweiligen Äußerung im Dialog beginnend bei 0. |
| Jahreszeit | Die Staffel Nr. der Friends-TV-Show, zu der eine bestimmte Äußerung gehört. |
| Folge | Die Folge Nr. der Friends-TV-Show in einer bestimmten Staffel, zu der die Äußerung gehört. |
| Startzeit | Die Startzeit der Äußerung in der angegebenen Episode im Format „hh:mm:ss,ms“. |
| Endzeit | Die Endzeit der Äußerung in der angegebenen Episode im Format „hh:mm:ss,ms“. |
Es gibt 13 Pickle-Dateien mit den Daten und Funktionen, die zum Training der Basismodelle verwendet werden. Im Folgenden finden Sie eine kurze Beschreibung der einzelnen Pickle-Dateien.
import pickle
data , W , vocab , word_idx_map , max_sentence_length , label_index = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_avg_emb , val_text_avg_emb , test_text_avg_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_CNN_emb , val_text_CNN_emb , test_text_CNN_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_emb , val_text_emb , test_text_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_bimodal_emb , val_bimodal_emb , test_bimodal_emb = pickle . load ( open ( filepath , 'rb' ))In „./utils/“ stehen zwei Python-Skripte zur Verfügung:
Für Experimente werden alle Labels als One-Hot-Codierungen dargestellt, deren Indizes wie folgt lauten:
Als Grundlage für die Emotionsklassifizierung wurden die folgenden Klassengewichte verwendet. Die Indizierung ist die gleiche wie oben erwähnt. Klassengewichte: [4,0, 15,0, 15,0, 3,0, 1,0, 6,0, 3,0].
Bitte befolgen Sie diese Schritte, um die Basislinie auszuführen:
./data/pickles/baseline/baseline.py wie folgt aus:python baseline.py -classify [Sentiment|Emotion] -modality [text|audio|bimodal] [-train|-test]python baseline.py -classify Sentiment -modality text -trainpython baseline.py -h um Hilfetext für die Parameter zu erhalten../data/models/ . Bitte zitieren Sie die folgenden Artikel, wenn Sie diesen Datensatz für Ihre Forschung nützlich finden
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, R. Mihalcea. MELD: Ein multimodaler Mehrparteien-Datensatz zur Emotionserkennung in Gesprächen. ACL 2019.
Chen, SY, Hsu, CC, Kuo, CC und Ku, LW EmotionLines: Ein Emotionskorpus von Mehrparteiengesprächen. arXiv-Vorabdruck arXiv:1802.08379 (2018).
Der multimodale EmoryNLP-Emotionserkennungsdatensatz wurde durch die Verbesserung und Erweiterung des EmoryNLP-Emotionserkennungsdatensatzes erstellt. Es enthält die gleichen Dialoginstanzen, die im EmoryNLP-Emotionserkennungsdatensatz verfügbar sind, umfasst aber neben Text auch Audio- und visuelle Modalitäten. Im multimodalen EmoryNLP-Datensatz sind mehr als 800 Dialoge und 9000 Äußerungen aus der TV-Serie „Friends“ enthalten. An den Dialogen beteiligten sich mehrere Redner. Jeder Äußerung in einem Dialog wurde eine dieser sieben Emotionen zugeordnet: Neutral, freudig, friedlich, kraftvoll, ängstlich, verrückt und traurig. Die Anmerkungen sind dem Originaldatensatz entlehnt.
| Statistiken | Zug | Entwickler | Prüfen |
|---|---|---|---|
| Anzahl der Modalitäten | {a,v,t} | {a,v,t} | {a,v,t} |
| Anzahl einzigartiger Wörter | 9.744 | 2.123 | 2.345 |
| Durchschn. Äußerungslänge | 7,86 | 6,97 | 7,79 |
| Max. Äußerungslänge | 78 | 60 | 61 |
| Durchschn. Anzahl der Emotionen pro Szene | 4.10 | 4.00 | 4.40 |
| Anzahl der Dialoge | 659 | 89 | 79 |
| Anzahl der Äußerungen | 7551 | 954 | 984 |
| Anzahl der Lautsprecher | 250 | 46 | 48 |
| # der Emotionsverschiebung | 4596 | 575 | 653 |
| Durchschn. Dauer einer Äußerung | 5,55s | 5,46 Sekunden | 5,27 Sekunden |
| Zug | Entwickler | Prüfen | |
|---|---|---|---|
| Froh | 1677 | 205 | 217 |
| Verrückt | 785 | 97 | 86 |
| Neutral | 2485 | 322 | 288 |
| Friedlich | 638 | 82 | 111 |
| Kraftvoll | 551 | 70 | 96 |
| Traurig | 474 | 51 | 70 |
| Verängstigt | 941 | 127 | 116 |
Videoclips dieses Datensatzes können über diesen Link heruntergeladen werden. Die Anmerkungsdateien finden Sie unter https://github.com/SenticNet/MELD/tree/master/data/emorynlp. Es gibt 3 CSV-Dateien. Jeder Eintrag in der ersten Spalte dieser CSV-Dateien enthält eine Äußerung, deren zugehöriger Videoclip hier zu finden ist. Jede Äußerung und ihr Videoclip werden durch Staffelnummer, Episodennummer, Szenen-ID und Äußerungs-ID indiziert. Beispielsweise impliziert „sea1_ep2_sc6_utt3.mp4“ , dass der Clip der Äußerung mit Staffel Nr. entspricht. 1, Folge Nr. 2, scene_id 6 und utterance_id 3. Eine Szene ist einfach ein Dialog. Diese Indizierung stimmt mit dem Originaldatensatz überein. Die CSV-Dateien und die Videodateien werden entsprechend dem Originaldatensatz in den Zug-, Validierungs- und Testsatz unterteilt. Anmerkungen wurden direkt aus dem ursprünglichen EmoryNLP-Datensatz entlehnt (Zahiri et al. (2018)).
| Spaltenname | Beschreibung |
|---|---|
| Äußerung | Einzelne Äußerungen von EmoryNLP als String. |
| Lautsprecher | Name des Sprechers, der mit der Äußerung verknüpft ist. |
| Emotion | Die Emotion (neutral, freudig, friedlich, kraftvoll, ängstlich, verrückt und traurig), die der Sprecher in der Äußerung zum Ausdruck bringt. |
| Szenen-ID | Der Index des Dialogs beginnend bei 0. |
| Utterance_ID | Der Index der jeweiligen Äußerung im Dialog beginnend bei 0. |
| Jahreszeit | Die Staffel Nr. der TV-Show „Friends“, zu der eine bestimmte Äußerung gehört. |
| Folge | Die Folge Nr. der Friends-TV-Show in einer bestimmten Staffel, zu der die Äußerung gehört. |
| Startzeit | Die Startzeit der Äußerung in der angegebenen Episode im Format „hh:mm:ss,ms“. |
| Endzeit | Die Endzeit der Äußerung in der angegebenen Episode im Format „hh:mm:ss,ms“. |
Hinweis : Bei einigen Äußerungen konnten wir aufgrund einiger Inkonsistenzen in den Untertiteln die Start- und Endzeit nicht ermitteln. Solche Äußerungen wurden im Datensatz weggelassen. Wir empfehlen den Benutzern jedoch, die entsprechenden Äußerungen aus dem Originaldatensatz zu finden und Videoclips dafür zu erstellen.
Bitte zitieren Sie die folgenden Artikel, wenn Sie diesen Datensatz für Ihre Forschung nützlich finden
S. Zahiri und JD Choi. Emotionserkennung in Transkripten von Fernsehsendungen mit sequenzbasierten Faltungs-Neuronalen Netzen. Im AAAI-Workshop zur affektiven Inhaltsanalyse, AFFCON'18, 2018.
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, R. Mihalcea. MELD: Ein multimodaler Mehrparteien-Datensatz zur Emotionserkennung im Gespräch. ACL 2019.


