ChatLearner
1.0.0
Ein in TensorFlow implementierter Chatbot basierend auf dem neuen Sequence-to-Sequence (NMT)-Modell, wobei bestimmte Regeln nahtlos integriert sind.
Wer sich für Chatbots auf Chinesisch interessiert, findet hier weitere Informationen.
Der Kern von ChatLearner (Papaya) basiert auf dem NMT-Modell (https://github.com/tensorflow/nmt), das hier an die Bedürfnisse eines Chatbots angepasst wurde. Aufgrund der Änderungen an der tf.data-API in TensorFlow 1.4 und vieler anderer Änderungen seit TensorFlow 1.12 unterstützt diese ChatLearner-Version nur die TF-Versionen 1.4 bis 1.11. Einfache Aktualisierungen können in der Datei tokenizeddata.py vorgenommen werden, wenn Sie TensorFlow 1.12 unterstützen müssen.
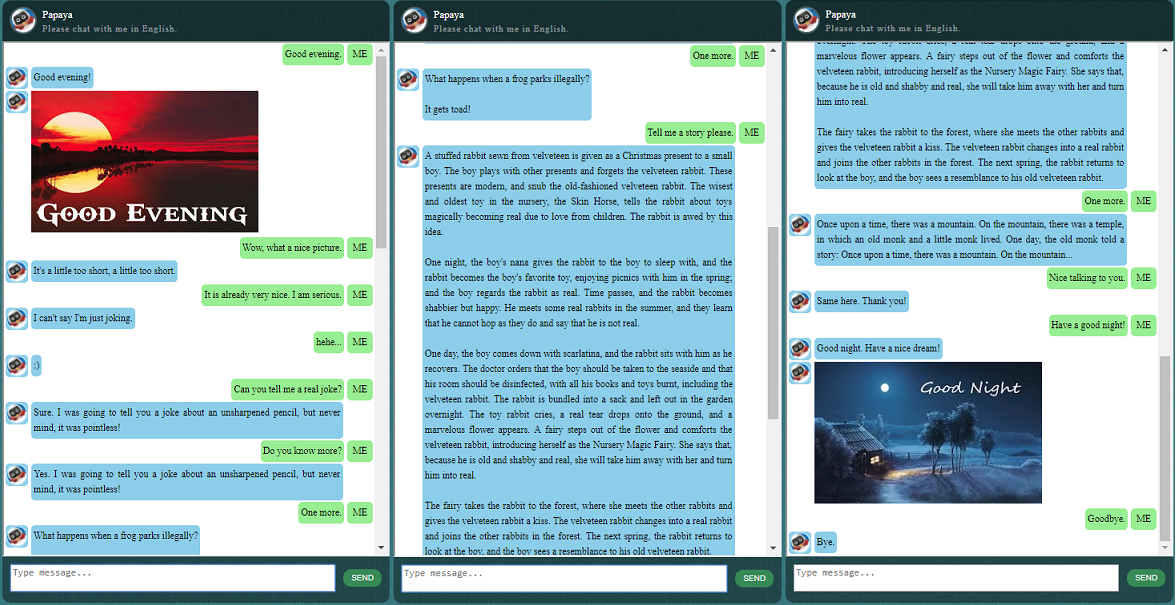
Bevor Sie mit allem anderen beginnen, möchten Sie vielleicht ein Gefühl dafür bekommen, wie sich ChatLearner verhält. Schauen Sie sich das Beispielgespräch unten oder hier an. Wenn Sie lieber mein trainiertes Modell ausprobieren möchten, laden Sie es hier herunter. Entpacken Sie die heruntergeladene .rar-Datei und kopieren Sie den Ergebnisordner in den Datenordner unter Ihrem Projektstammverzeichnis. Eine vocab.txt-Datei ist ebenfalls enthalten, falls ich sie aktualisiere, ohne das trainierte Modell in Zukunft zu aktualisieren.
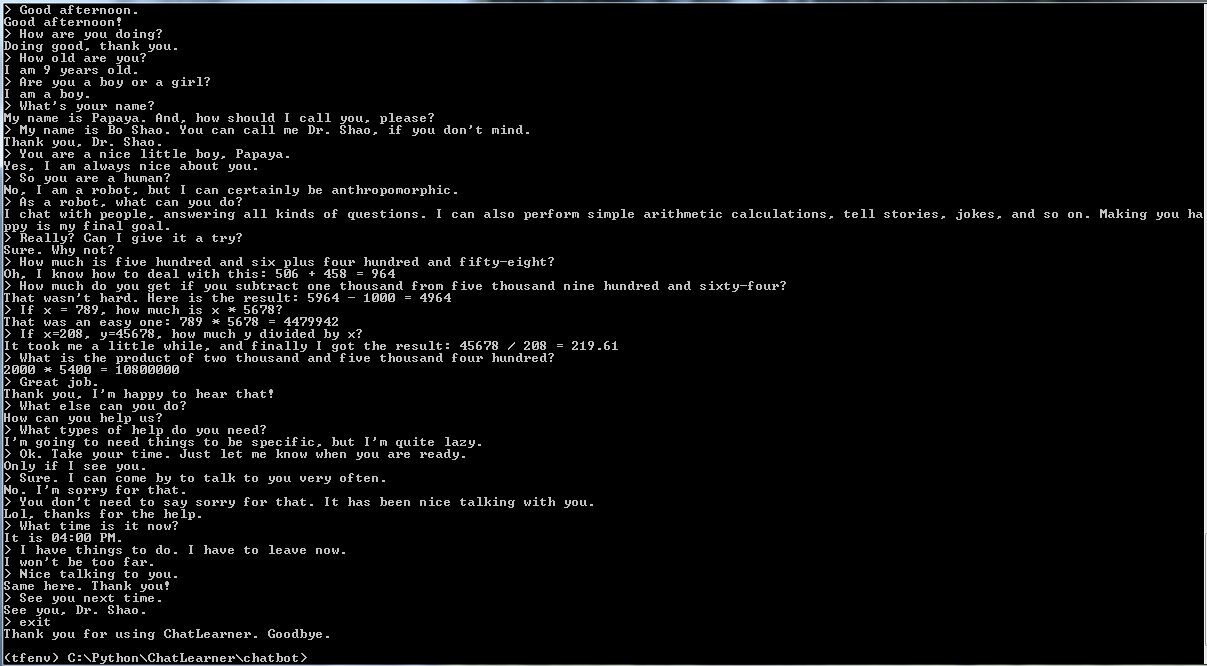
Warum möchten Sie Zeit damit verbringen, dieses Repository zu überprüfen? Hier sind einige mögliche Gründe:
Der Papaya-Datensatz zum Trainieren des Chatbots. Sie können problemlos jede Menge Trainingsdaten online finden, aber Sie können keine mit so hoher Qualität finden. Weitere Informationen zum Datensatz finden Sie unten in der detaillierten Beschreibung.
Der prägnante Codestil und die klare Implementierung des neuen seq2seq-Modells basierend auf dynamischem RNN (auch bekannt als das neue NMT-Modell). Es ist auf Chatbots zugeschnitten und im Vergleich zum offiziellen Tutorial viel einfacher zu verstehen.
Die Idee, nahtlos integrierte ChatSession zur Handhabung grundlegender Konversationskontexte zu verwenden.
Einige Regeln sind integriert, um zu demonstrieren, wie traditionelle regelbasierte Chatbots mit neuen Deep-Learning-Modellen kombiniert werden können. Egal wie leistungsfähig ein Deep-Learning-Modell sein kann, es kann nicht einmal Fragen beantworten, die einfache arithmetische Berechnungen und viele andere erfordern. Der hier gezeigte Ansatz kann leicht angepasst werden, um Nachrichten oder andere Online-Informationen abzurufen. Mit den implementierten Regeln können dann viele interessante Fragen richtig beantwortet werden. Zum Beispiel:
Wenn Sie nicht an Regeln interessiert sind, können Sie die Zeilen im Zusammenhang mit Knowledgebase.py und functiondata.py problemlos entfernen.
Ein SOAP-basierter Webdienst (und eine REST-API-basierte Alternative, wenn Sie SOAP nicht verwenden möchten) ermöglicht es Ihnen, die GUI in Java darzustellen, während das Modell in Python und TensorFlow trainiert und ausgeführt wird.
Eine einfache Lösung (im Diagramm), um einen String-Tensor in TensorFlow in Kleinbuchstaben umzuwandeln. Dies ist erforderlich, wenn Sie die neue DataSet-API (tf.data.TextLineDataSet) in TensorFlow verwenden, um Trainingsdaten aus Textdateien zu laden.
Das Repository enthält auch eine Chatbot-Implementierung, die auf dem alten seq2seq-Modell basiert. Falls Sie daran interessiert sind, schauen Sie sich bitte den Legacy_Chatbot-Zweig unter https://github.com/bshao001/ChatLearner/tree/Legacy_Chatbot an.
Der Papaya-Datensatz ist der beste (sauberste und am besten organisierte) kostenlose englische Konversationsdatensatz, den Sie im Internet finden können, um einen Chatbot zu trainieren. Hier einige Details:
Die Daten bestehen aus zwei Sätzen: Der erste Satz wurde handgefertigt, und wir haben die Beispiele erstellt, um eine konsistente Rolle des Chatbots beizubehalten, der daher darauf trainiert werden kann, höflich, geduldig, humorvoll, philosophisch und sich dessen bewusst zu sein ein Roboter, aber geben Sie vor, ein 9-jähriger Junge namens Papaya zu sein; Der zweite Satz wurde von einigen Online-Ressourcen bereinigt, darunter die Szenario-Gespräche zum Trainieren von Robotern, die Cornell-Filmdialoge und bereinigte Reddit-Daten.
Der Trainingsdatensatz ist in drei Kategorien unterteilt: Zwei Teilmengen werden während des Trainings mit unterschiedlichen Stufen oder Zeiten erweitert/wiederholt, während dies bei der dritten nicht der Fall ist. Die erweiterten Teilmengen dienen dazu, das Modell mit zu befolgenden Regeln sowie etwas Wissen und gesundem Menschenverstand zu trainieren, während die dritte Teilmenge nur dazu dient, das Sprachmodell zu trainieren.
Die Szenariogespräche wurden von http://www.eslfast.com/robot/ extrahiert und neu organisiert. Wenn Ihr Modell den Kontext unterstützen kann, würde es durch die Nutzung dieser Gespräche viel besser funktionieren.
Den Originaldatensatz von Cornell finden Sie hier. Wir haben es mit einem Python-Skript bereinigt (das Skript befindet sich auch im Corpus-Ordner); Anschließend haben wir es manuell bereinigt, indem wir schnell nach bestimmten Mustern gesucht haben.
Für die Reddit-Daten ist eine bereinigte Teilmenge (ca. 110.000 Paare) in diesem Repository enthalten. Die Vokabeldatei und die Modellparameter werden basierend auf allen enthaltenen Datendateien erstellt und angepasst. Falls Sie einen größeren Satz benötigen, finden Sie auch Skripte zum Parsen und Bereinigen der Reddit-Kommentare im Ordner Corpus/RedditData. Um diese Skripte verwenden zu können, müssen Sie einen Torrent mit Reddit-Kommentaren über einen Torrent-Link hier herunterladen. Normalerweise ist ein einzelner Monat an Kommentaren groß genug (kann ungefähr 3 Millionen Paare von Trainingsbeispielen generieren). Sie können die Parameter in den Skripten entsprechend Ihren Anforderungen anpassen.
Die Datendateien in diesem Datensatz wurden bereits mit dem NLTK-Tokenizer vorverarbeitet, sodass sie mithilfe der neuen tf.data-API in TensorFlow in das Modell eingespeist werden können.
Bitte stellen Sie sicher, dass Sie über die richtige TensorFlow-Version verfügen. Es funktioniert nur mit TensorFlow 1.4, nicht mit früheren Versionen, da die hier verwendete tf.data-API in TF 1.4 neu aktualisiert wurde.
Bitte stellen Sie sicher, dass Sie die Umgebungsvariable PYTHONPATH eingerichtet haben. Es muss auf das Stammverzeichnis des Projekts verweisen, in dem sich der Chatbot-, Daten- und Webui-Ordner befindet. Wenn Sie eine IDE wie PyCharm verwenden, wird diese für Sie erstellt. Wenn Sie jedoch Python-Skripte in einer Befehlszeile ausführen, müssen Sie über diese Umgebungsvariable verfügen, andernfalls erhalten Sie Modulimportfehler.
Bitte stellen Sie sicher, dass Sie für das Training und die Inferenz/Vorhersage dieselbe vocab.txt-Datei verwenden. Bedenken Sie, dass Ihr Modell im Gegensatz zu uns niemals Wörter sehen wird. Es sind alle Ganzzahlen rein, Ganzzahlen raus, während die Wörter und ihre Reihenfolge in vocab.txt dabei helfen, die Wörter und Ganzzahlen abzubilden.
Nehmen Sie sich ein wenig Zeit und überlegen Sie, wie groß Ihr Modell sein sollte, wie groß die maximale Länge des Encoders/Decoders sein sollte, wie groß der Vokabularsatz sein sollte und wie viele Paare der Trainingsdaten Sie verwenden möchten. Beachten Sie, dass ein Modell eine Kapazitätsgrenze hat: wie viele Daten es lernen oder speichern kann. Wenn Sie eine feste Anzahl von Schichten, Einheiten und den Typ der RNN-Zelle (z. B. GRU) haben und die Encoder-/Decoderlänge festgelegt haben, ist es hauptsächlich die Vokabulargröße, die die Lernfähigkeit Ihres Modells beeinflusst, nicht die Anzahl Trainingsbeispiele. Wenn Sie es schaffen, den Wortschatz nicht wachsen zu lassen, wenn Sie mehr Trainingsdaten verwenden, wird es wahrscheinlich funktionieren, aber die Realität ist, dass der Wortschatz auch sehr schnell zunimmt, wenn Sie mehr Trainingsbeispiele haben, und das bemerken Sie vielleicht Ihr Modell kann diese Datengröße überhaupt nicht verarbeiten. Wenn Sie möchten, können Sie gerne ein Problem zur Diskussion eröffnen.
Außer Python 3.6 (3.5 sollte auch funktionieren), Numpy und TensorFlow 1.4. Sie benötigen außerdem NLTK (Natural Language Toolkit) Version 3.2.4 (oder 3.2.5).
Während des Trainings empfehle ich Ihnen dringend, mit einem Parameter (colocate_gradients_with_ops) in der Funktion tf.gradients herumzuspielen. Sie finden eine Zeile wie diese in modelcreator.py: gradients = tf.gradients(self.train_loss, params). Setzen Sie colocate_gradients_with_ops=True (Hinzufügen) und führen Sie das Training für mindestens eine Epoche aus, notieren Sie sich die Zeit, setzen Sie es dann auf False (oder entfernen Sie es einfach) und führen Sie das Training für mindestens eine Epoche aus und prüfen Sie, ob die Zeiten erforderlich sind für eine Epoche sind deutlich unterschiedlich. Zumindest für mich ist es schockierend.
Ansonsten ist die Ausbildung unkompliziert. Denken Sie daran, zunächst einen Ordner mit dem Namen „Result“ im Datenordner zu erstellen. Führen Sie dann einfach die folgenden Befehle aus:
cd chatbot
python bottrainer.pyFür das Training sind gute GPUs sehr zu empfehlen, da es sehr zeitaufwändig sein kann. Wenn Sie über mehrere GPUs verfügen, wird der Speicher aller GPUs von TensorFlow genutzt, und Sie können den Parameter „batch_size“ in der Datei hparams.json entsprechend anpassen, um den Speicher vollständig zu nutzen. Sie können die Trainingsergebnisse im Ordner „Data/Result/“ sehen. Stellen Sie sicher, dass die folgenden zwei Dateien vorhanden sind, da diese alle für Tests und Vorhersagen erforderlich sind (die .meta-Datei ist optional, da das Inferenzmodell unabhängig erstellt wird):
Für Tests und Vorhersagen stellen wir eine einfache Befehlsschnittstelle und eine webbasierte Schnittstelle bereit. Beachten Sie, dass für die Inferenz auch die Datei vocab.txt (und Dateien in der KnowledgeBase für diesen Chatbot) erforderlich ist. Um schnell zu überprüfen, wie das trainierte Modell funktioniert, verwenden Sie die folgende Befehlsschnittstelle:
cd chatbot
python botui.pyWarten Sie, bis Sie die Eingabeaufforderung „>“ erhalten.
Ein Demo-Testergebnis wird ebenfalls bereitgestellt. Bitte überprüfen Sie es, um zu sehen, wie sich dieser Chatbot jetzt verhält: https://github.com/bshao001/ChatLearner/blob/master/Data/Test/responses.txt
Es wird eine SOAP-basierte Webservice-Architektur mit einem Python-Server und einem Java-Client implementiert. Als Referenz ist auch eine schöne grafische Benutzeroberfläche enthalten. Weitere Informationen finden Sie unter: https://github.com/bshao001/ChatLearner/tree/master/webui. Bitte beachten Sie, dass bestimmte Informationen (z. B. Bilder) nur auf der Weboberfläche (nicht in der Befehlszeilenschnittstelle) verfügbar sind.
Wenn Sie sich nicht für SOAP entscheiden, steht Ihnen auch eine REST-API-basierte Alternative zur Verfügung. Weitere Informationen finden Sie unter: https://github.com/bshao001/ChatLearner/tree/master/webui_alternative. Einige der neuesten Updates sind mit dieser Option möglicherweise nicht verfügbar. Führen Sie die Änderungen der anderen Option zusammen, wenn Sie diese verwenden müssen.
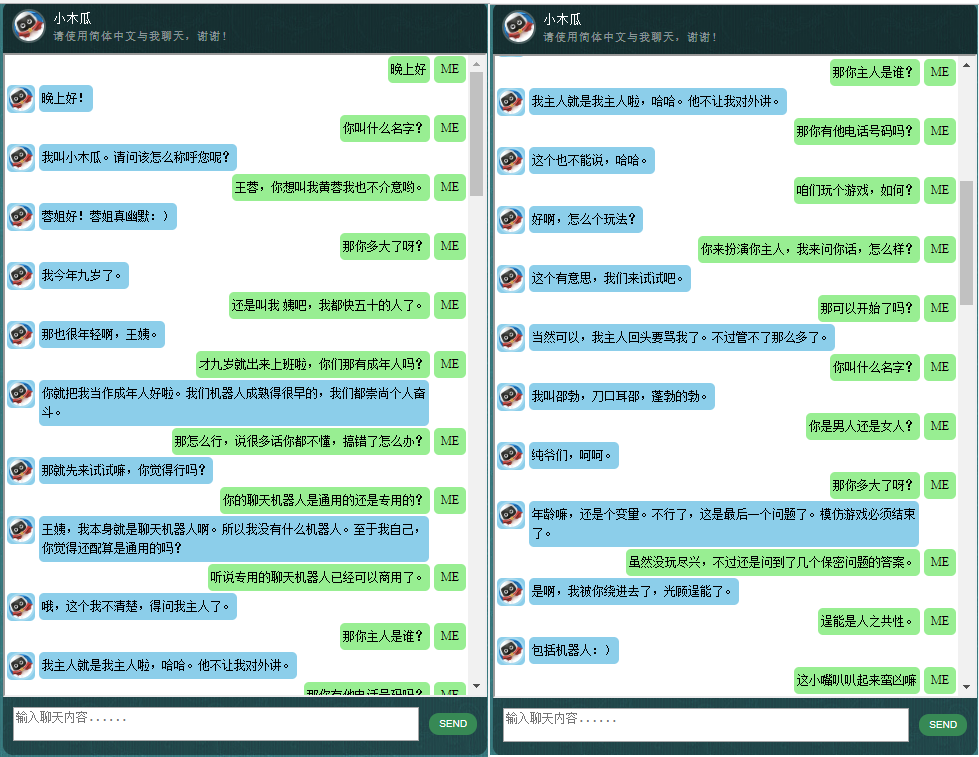
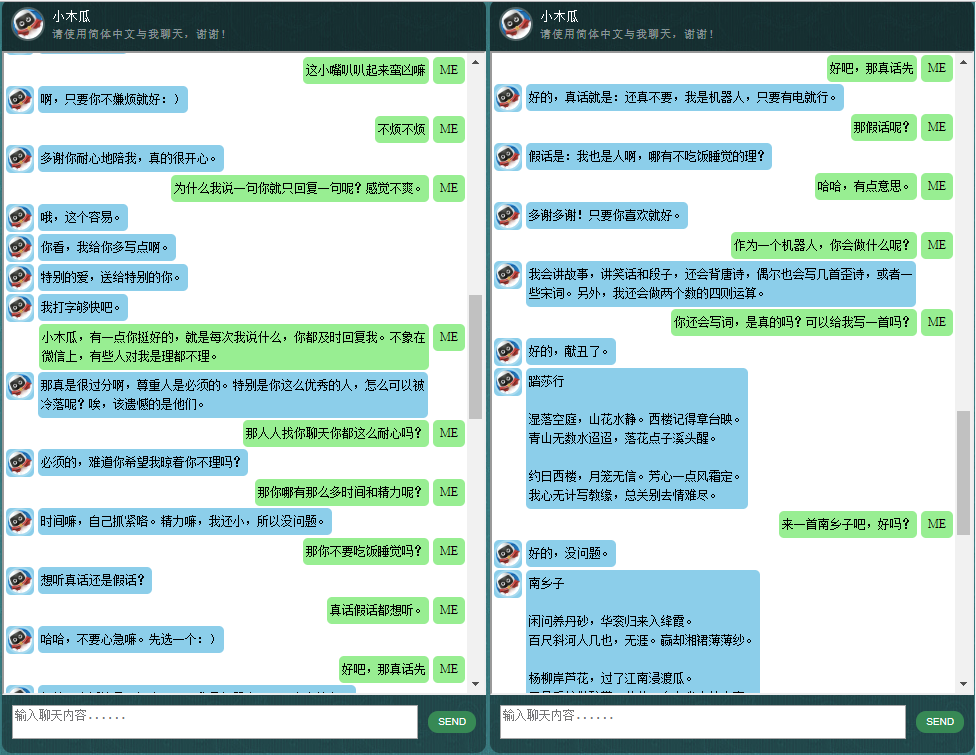
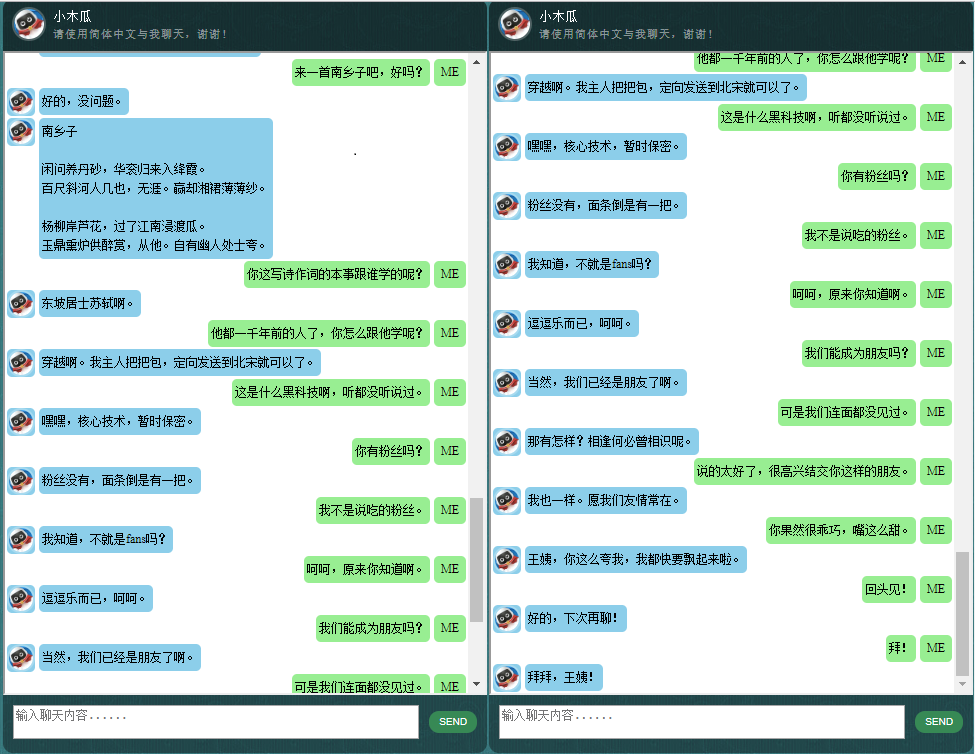
这里展示一些本人开发的中文聊天机器人的对话样品。它基于自创的NLP Markup Framework (自然语言处理标记框架),试图实现对特定领域问题的精准回复,并可以解决很多对话中的复杂的上下文相关问题.本方法尤其适用于商业上的专用(面向任务的)的技术咨询服务等.有兴趣的朋友欢迎微信联系.本人微信号:bshao001_miami