Dialog
1.0.0
Dialog ist ein japanisches Chatbot-Projekt.
Die in diesem Projekt verwendete Architektur ist das EncoderDecoder-Modell mit BERT-Encoder und Transformer-Decoder.
Artikel auf Japanisch verfasst.
Sie können Trainings- und Bewertungsskripte auf Google Colab ausführen, ohne eine Umgebung erstellen zu müssen.
Bitte klicken Sie auf folgenden Link.
Beachten Sie, dass der Download-Befehl im Schulungsnotizbuch am Ende des Hinweises beschrieben wird, aber noch nicht getestet wurde. Wenn Sie also ein Trainingsnotizbuch verwenden und keine Trainingsgewichtsdatei herunterladen können, laden Sie es bitte manuell herunter.
Blog auf Japanisch geschrieben
@ycat3 hat ein Text-to-Speech-Beispiel erstellt, indem dieses Projekt zur Satzgenerierung und Parallel Wavenet zur Sprachsynthese verwendet wurden. Der Quellcode wird nicht geteilt, aber Sie können ihn reproduzieren, wenn Sie Parallel Wavenet nutzen. In diesem Blog gibt es einige Hörbeispiele, also probieren Sie es bitte mal aus.
Ich würde gerne eine App erstellen, die es uns ermöglicht, mithilfe von Sprachsynthese und Spracherkennung mit KI per Sprache zu sprechen, wenn ich viel Freizeit habe, aber jetzt kann ich das aufgrund der Prüfungsvorbereitung nicht tun ...
2Epochen
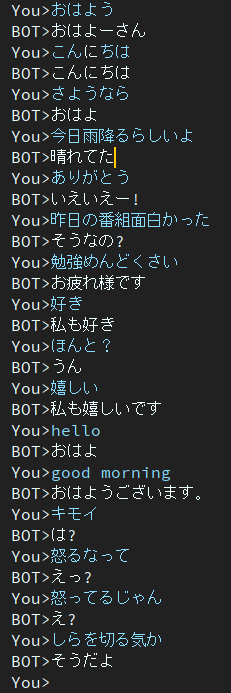
Dieses Modell weist immer noch das Problem der dumpfen Reaktion auf.
Um dieses Problem zu lösen, recherchiere ich gerade.
Dann fand ich heraus, dass das Papier dieses Problem angeht.
Eine weitere diversitätsfördernde Zielfunktion für die Erzeugung neuronaler Dialoge
Die Autoren gehören dem Nara Institute of Science and Technology, auch bekannt als NAIST, an.
Sie schlagen die neue Zielfunktion der Erzeugung neuronaler Dialoge vor.
Ich hoffe, dass diese Methode mir helfen kann, dieses Problem zu lösen.
in Google Drive.
Benötigte Pakete sind
Sollten aufgrund der Pakete Fehler auftreten, installieren Sie bitte fehlende Pakete.
Beispiel, wenn Sie Conda verwenden.
# create new environment
$ conda create -n dialog python=3.7
# activate new environment
$ activate dialog
# install pytorch
$ conda install pytorch torchvision cudatoolkit={YOUR_VERSION} -c pytorch
# install rest of depending package except for MeCab
$ pip install transformers tqdm neologdn emoji
# #### Already installed MeCab #####
# ## Ubuntu ###
$ pip install mecab-python3
# ## Windows ###
# check that "path/to/MeCab/bin" are added to system envrionment variable
$ pip install mecab-python-windows
# #### Not Installed MeCab #####
# install Mecab in accordance with your OS.
# method described in below is one of the way,
# so you can use your way if you'll be able to use transformers.BertJapaneseTokenizer.
# ## Ubuntu ###
# if you've not installed MeCab, please execute following comannds.
$ apt install aptitude
$ aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
$ pip install mecab-python3
# ## Windows ###
# Install MeCab from https://github.com/ikegami-yukino/mecab/releases/tag/v0.996
# and add "path/to/Mecab/bin" to system environment variable.
# then run the following command.
$ pip install mecab-python-windows # in config.py, line 24
# default value is './data'
data_dir = 'path/to/dir_contains_training_data'Wenn Sie bereit sind, mit dem Training zu beginnen, führen Sie das Hauptskript aus.
$ python main.py # in config.py, line 24
# default value is './data'
data_dir = 'path/to/dir_contains_pretrained'$ python run_eval.pyWenn Sie weitere Konversationsdaten erhalten möchten, verwenden Sie bitte get_tweet.py
Beachten Sie, dass Sie Consumer_key und Access_token ändern müssen, um dieses Skript verwenden zu können.
Führen Sie dann die folgenden Befehle aus.
# usage
$ python get_tweet.py " query " " Num of continuous utterances "
# Example
# This command works until occurs errors
# and makes a file named "tweet_data_私は_5.txt" in "./data"
$ python get_tweet.py 私は 5Wenn Sie den Beispielbefehl ausführen, beginnt das Skript damit, fünf aufeinanderfolgende Sätze zu sammeln, wenn der letzte Satz „私は“ enthält.
Wenn Sie jedoch 3 oder mehr Zahlen auf „kontinuierliche Äußerungen“ festlegen, erstellt make_training_data.py automatisch ein Paar von Äußerungen.
Führen Sie dann den folgenden Befehl aus.
$ python make_training_data.pyDieses Skript erstellt Trainingsdaten mit „./data/tweet_data_*.txt“, genau wie der Name.
Encoder: BERT
Decoder: Decoder von Vanilla Transformer
Verlust: CrossEntropy
Optimierer: AdamW
Tokenizer: BertJapaneseTokenizer
Wenn Sie weitere Informationen zur Architektur von BERT oder Transformer wünschen, lesen Sie bitte den folgenden Artikel.


