focused empathy
1.0.0
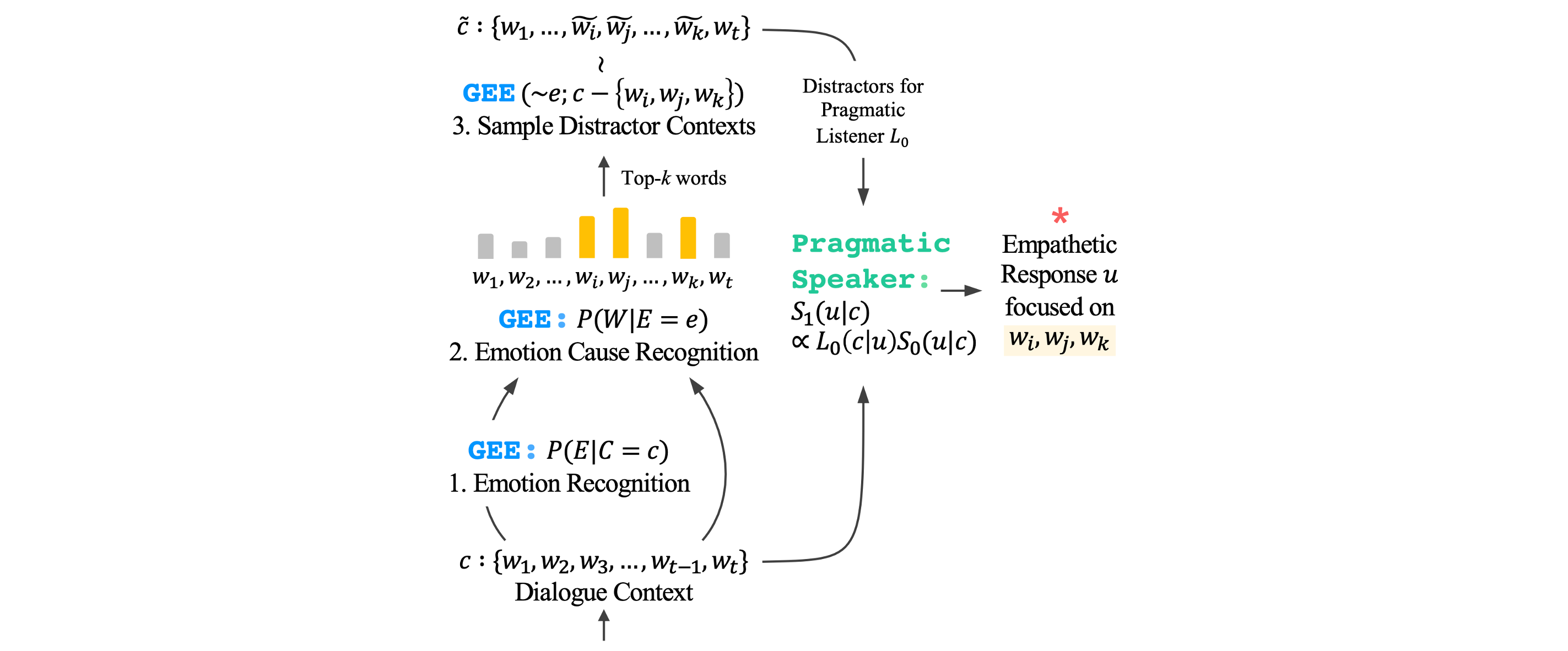
Offizielle PyTorch-Implementierung und EmoCause-Evaluierungsset unseres EMNLP 2021-Papiers?
Hyunwoo Kim, Byeongchang Kim und Gunhee Kim. Perspektivenübernahme und Pragmatik zur Generierung empathischer Reaktionen, die sich auf Emotionsursachen konzentrieren. EMNLP , 2021 [Papier]
Wenn Sie die Materialien in diesem Repository im Rahmen einer veröffentlichten Forschung verwenden, bitten wir Sie, das folgende Papier zu zitieren:
@inproceedings { Kim:2021:empathy ,
title = { Perspective-taking and Pragmatics for Generating Empathetic Responses Focused on Emotion Causes } ,
author = { Kim, Hyunwoo and Kim, Byeongchang and Kim, Gunhee } ,
booktitle = { EMNLP } ,
year = 2021
}Unser Code basiert auf dem ParlAI-Framework. Wir empfehlen Ihnen, wie folgt eine Conda-Umgebung zu erstellen
conda env create -f environment.ymlund aktivieren Sie es mit
conda activate focused-empathy
python -m spacy download enEmoCause ist ein Datensatz mit annotierten Emotionen, die Wörter in emotionalen Situationen aus dem gültigen und Testsatz von EmpatheticDialogues auslösen. Das Ziel besteht darin, Wörter, die Emotionen verursachen, in Sätzen zu erkennen, indem nur auf Emotionsetiketten auf Satzebene trainiert wird, ohne Etiketten auf Wortebene ( d. h. schwach überwachte Erkennung von Emotionsursachen ). EmoCause basiert auf der Tatsache, dass Menschen die Ursache von Emotionen durch überwachtes Lernen auf Wortebene nicht erkennen. Daher stellen wir kein Trainingsset zur Verfügung.

Sie können das EmoCause- Evaluierungsset [hier] herunterladen.
Beachten Sie, dass der Datensatz automatisch heruntergeladen wird, wenn Sie den folgenden Experimentbefehl ausführen.
| #Emotion | Etikettentyp | #Label/Äußerung | #Äußerung | |
|---|---|---|---|---|
| EmoCause | 32 | Wort | 2.3 | 4,6K |
{
"original_situation": the original situations in the EmpatheticDialogues,
"tokenized_situation": tokenized situation utterances using spacy,
"emotion": emotion labels,
"conv_id": id for each corresponding conversation in EmpatheticDialogues,
"annotation": list of tuples: (emotion cause word, index),
"labels": list of strings containing the emotion cause words
}
Alle entsprechenden Modelle werden automatisch heruntergeladen, wenn die folgenden Befehle ausgeführt werden.
Wir bieten auch Links zum Herunterladen von Handbüchern: [GEE] [Finetuned Blender]
Sie können unseren vorgeschlagenen Generative Emotion Estimator (GEE) im EmoCause-Bewertungsset bewerten.
python eval_emocause.py --model agents.gee_agent:GeeCauseInferenceAgent --fp16 FalseSie können unseren Ansatz zur Generierung fokussierter einfühlsamer Antworten auf der Grundlage eines fein abgestimmten Blenders bewerten (Sie kennen Blender nicht? Sehen Sie hier nach!).
python eval_empatheticdialogues.py --model agents.empathetic_gee_blender:EmpatheticBlenderAgent --model_file data/models/finetuned_blender90m/model --fp16 False --empathy-score False Durch Hinzufügen des Flags --alpha 0 wird der Blender ohne Pragmatik ausgeführt. Sie können auch den Zufallsdistraktor (Plain S1) ausprobieren, indem Sie --distractor-type random hinzufügen.
Um auch die Interpretations- und Explorationswerte zu messen, setzen Sie den --empathy-score auf True . Die auf EmpatheticDialogues optimierten RoBERTa-Modelle werden automatisch heruntergeladen. Weitere Informationen zu Empathie-Scores finden Sie im Original-Repo.
Wir danken den anonymen Gutachtern für ihre hilfreichen Kommentare zu dieser Arbeit.
Diese Forschung wurde vom Samsung Research Funding Center von Samsung Electronics unter der Projektnummer SRFCIT210101 unterstützt. Die Rechenressourcen- und Humanstudie werden vom Brain Research Program der National Research Foundation of Korea (NRF) (2017M3C7A1047860) unterstützt.
Bitte kontaktieren Sie Hyunwoo Kim unter hyunw.kim unter vl dot snu dot ac dot kr.
Dieses Repository ist MIT-lizenziert. Einzelheiten finden Sie in der LICENSE-Datei.


