Seq2seqChatbots
1.0.0
Ein Wrapper um tensor2tensor zum flexiblen Trainieren, Interagieren und Generieren von Daten für neuronale Chatbots.
Das Wiki enthält meine Notizen und Zusammenfassungen von über 150 aktuellen Veröffentlichungen zum Thema neuronale Dialogmodellierung.
? Führen Sie Ihre eigenen Schulungen durch oder experimentieren Sie mit vorab trainierten Modellen
✅ 4 verschiedene Dialogdatensätze integriert mit tensor2tensor
? Funktioniert nahtlos mit jedem Modell oder Hyperparametersatz in tensor2tensor
Leicht erweiterbare Basisklasse für Dialogprobleme
Führen Sie setup.py aus, das die erforderlichen Pakete installiert und Sie durch das Herunterladen zusätzlicher Daten führt:
python setup.py
Sie können alle trainierten Modelle, die in diesem Dokument verwendet werden, hier herunterladen. Jedes Training enthält zwei Kontrollpunkte, einen für das Minimum des Validierungsverlusts und einen weiteren nach 150 Epochen. Die Daten und die Ordnerstruktur der Schulungen stimmen exakt überein.
python t2t_csaky/main.py --mode=train
Das Modusargument kann eines der folgenden vier sein: {generate_data, train, decode, experiment} . Im Experimentiermodus können Sie festlegen, was in der Experimentierfunktion der Ausführungsdatei geschehen soll. Nachfolgend finden Sie eine ausführliche Erläuterung der Funktionsweise der einzelnen Modi.
Sie können die Flags und Parameter jedes Modus direkt in dieser Datei steuern. Bei jedem Lauf, den Sie initiieren, wird diese Datei in das entsprechende Verzeichnis kopiert, sodass Sie schnell auf die Parameter jedes Laufs zugreifen können. Es gibt einige Flags, die Sie für jeden Modus setzen müssen (das FLAGS -Wörterbuch in der Konfigurationsdatei):
t2t_usr_dir : Pfad zum Verzeichnis, in dem sich mein Code befindet. Sie müssen dies nicht ändern, es sei denn, Sie benennen das Verzeichnis um.
data_dir : Der Pfad zu dem Verzeichnis, in dem Sie die Quell- und Zielpaare sowie andere Daten generieren möchten. Der Datensatz wird eine Ebene höher aus diesem Verzeichnis in einen Ordner „raw_data“ heruntergeladen.
problem : Dies ist der Name eines registrierten Problems, das tensor2tensor benötigt. Einzelheiten finden Sie im Abschnitt „generate_data“ weiter unten. Alle Pfade sollten vom Stammverzeichnis des Repos ausgehen.
In diesem Modus werden die Daten heruntergeladen und vorverarbeitet und Quell- und Zielpaare generiert. Derzeit gibt es 6 registrierte Probleme, die Sie zusätzlich zu den von tensor2tensor bereitgestellten verwenden können:
persona_chat_chatbot : Dieses Problem implementiert den Persona-Chat-Datensatz (ohne die Verwendung von Personas).
daily_dialog_chatbot : Dieses Problem implementiert den DailyDialog-Datensatz (ohne Verwendung von Themen, Dialoghandlungen oder Emotionen).
opensubtitles_chatbot : Dieses Problem kann verwendet werden, um mit dem OpenSubtitles-Datensatz zu arbeiten.
cornell_chatbot_basic : Dieses Problem implementiert den Cornell Movie-Dialog Corpus.
cornell_chatbot_separate_names : Dieses Problem verwendet dasselbe Cornell-Korpus, jedoch werden die Namen der Sprecher und Adressaten jeder Äußerung angehängt, was zu Quelläußerungen wie unten führt.
BIANCA_m0 was für gute Sachen? CAMERON_m0
charakter_chatbot : Dies ist ein allgemeines zeichenbasiertes Problem, das mit jedem Datensatz funktioniert. Bevor Sie dies verwenden, müssen die durch eines der oben genannten Probleme generierten TXT-Dateien im Datenverzeichnis abgelegt werden. Anschließend kann dieses Problem zum Generieren von tensor2tensor-zeichenbasierten Datendateien verwendet werden.
Das Wörterbuch PROBLEM_HPARAMS in der Konfigurationsdatei enthält problemspezifische Parameter, die Sie vor der Datengenerierung festlegen können:
num_train_shards / num_dev_shards : Wenn Sie möchten, dass die generierten Zug- oder Entwicklungsdaten über mehrere Dateien verteilt werden.
vocabulary_size : Größe des Vokabulars, das wir für das Problem verwenden möchten. Wörter außerhalb dieses Vokabulars werden durch das Token ersetzt.
dataset_size : Anzahl der Äußerungspaare, wenn wir nicht den vollständigen Datensatz verwenden möchten (definiert durch 0).
dataset_split : Geben Sie eine Train-Val-Test-Aufteilung für das Problem an.
dataset_version : Dies ist nur für den opensubtitles-Datensatz relevant. Da es mehrere Versionen dieses Datensatzes gibt, können Sie das Jahr des Datensatzes angeben, den Sie herunterladen möchten.
name_vocab_size : Dies ist nur für das Cornell-Problem mit separaten Namen relevant. Sie können die Größe des Vokabulars festlegen, das nur die Personas enthält.
In diesem Modus können Sie ein Modell mit dem angegebenen Problem und den angegebenen Hyperparametern trainieren. Der Code ruft lediglich das Tensor2tensor-Trainingsskript auf, sodass jedes in tensor2tensor enthaltene Modell verwendet werden kann. Daneben gibt es auch ein Unterklassenmodell mit kleinen Modifikationen:
gradient_checkpointed_seq2seq : Kleine Modifikation des lstm-basierten seq2seq-Modells, sodass eigene Hparams vollständig verwendet werden können. Vor der Berechnung des Softmax werden die versteckten LSTM-Einheiten wie hier auf 2048 lineare Einheiten projiziert. Schließlich habe ich versucht, Gradienten-Checkpointing für dieses Modell zu implementieren, aber derzeit wird es entfernt, da es keine guten Ergebnisse liefert.
Es gibt mehrere zusätzliche Flags, die Sie für einen Trainingslauf im FLAGS -Wörterbuch in der Konfigurationsdatei angeben können. Einige davon sind:
train_dir : Name des Verzeichnisses, in dem die Trainingsprüfpunktdateien gespeichert werden.
model : Name des Modells: entweder eines der oben genannten oder ein von tensor2tensor definiertes Modell.
hparams : Geben Sie ein registriertes hparams_set an oder lassen Sie es leer, wenn Sie hparams in der Konfigurationsdatei definieren möchten. Um hparams für ein seq2seq- oder Transformer -Modell anzugeben, können Sie die Wörterbücher SEQ2SEQ_HPARAMS und TRANSFORMER_HPARAMS in der Konfigurationsdatei verwenden (sehen Sie sich diese für weitere Details an).
Mit diesem Modus können Sie die trainierten Modelle dekodieren. Die folgenden Parameter beeinflussen die Dekodierung (im FLAGS -Wörterbuch in der Konfigurationsdatei):
decode_mode : Kann interaktiv sein, sodass Sie über die Befehlszeile mit dem Modell chatten können. Im Dateimodus können Sie eine Datei mit Quelläußerungen angeben, für die Antworten generiert werden sollen, und im Datensatzmodus werden die bereitgestellten Validierungsdaten nach dem Zufallsprinzip abgetastet und Antworten ausgegeben.
decode_dir : Verzeichnis, in dem Sie eine Datei zum Dekodieren bereitstellen können. Die ausgegebenen Antworten werden hier gespeichert.
input_file_name : Name der Datei, die Sie im Dateimodus angeben müssen (im decode_dir abgelegt).
Ausgabedateiname : Name der Datei in decode_dir , in der Ausgabeantworten gespeichert werden.
beam_size : Größe des Strahls, wenn die Strahlsuche verwendet wird.
return_beams : Wenn False, wird nur der obere Balken zurückgegeben, andernfalls wird die Anzahl der Balken in beam_size zurückgegeben.
Die folgenden Ergebnisse stammen aus diesen beiden Arbeiten.
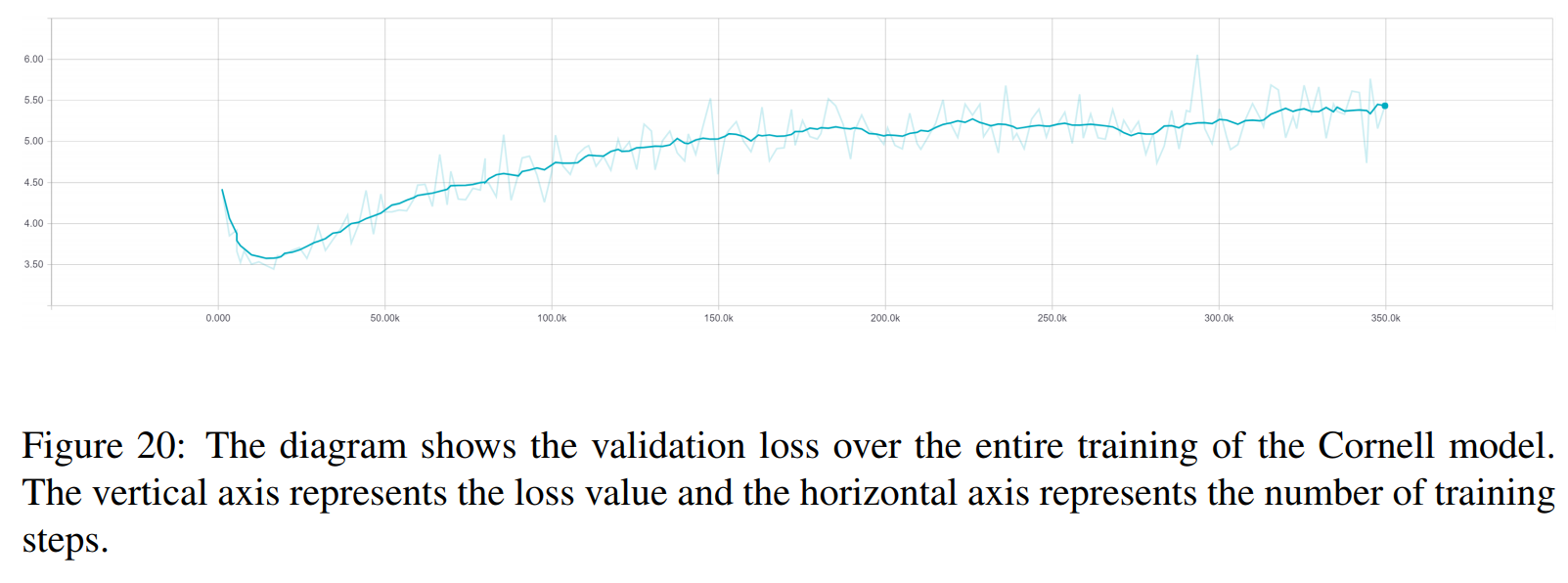

TRF ist das Transformer-Modell, während RT zufällig ausgewählte Antworten aus dem Trainingssatz und GT Ground-Truth-Antworten bedeutet. Eine Erläuterung der Metriken finden Sie im Dokument.
S2S ist ein einfaches seq2seq-Modell mit auf Cornell trainierten LSTMs, andere sind Transformer-Modelle. Opensubtitles F ist auf Opensubtitles vorab trainiert und auf Cornell abgestimmt. 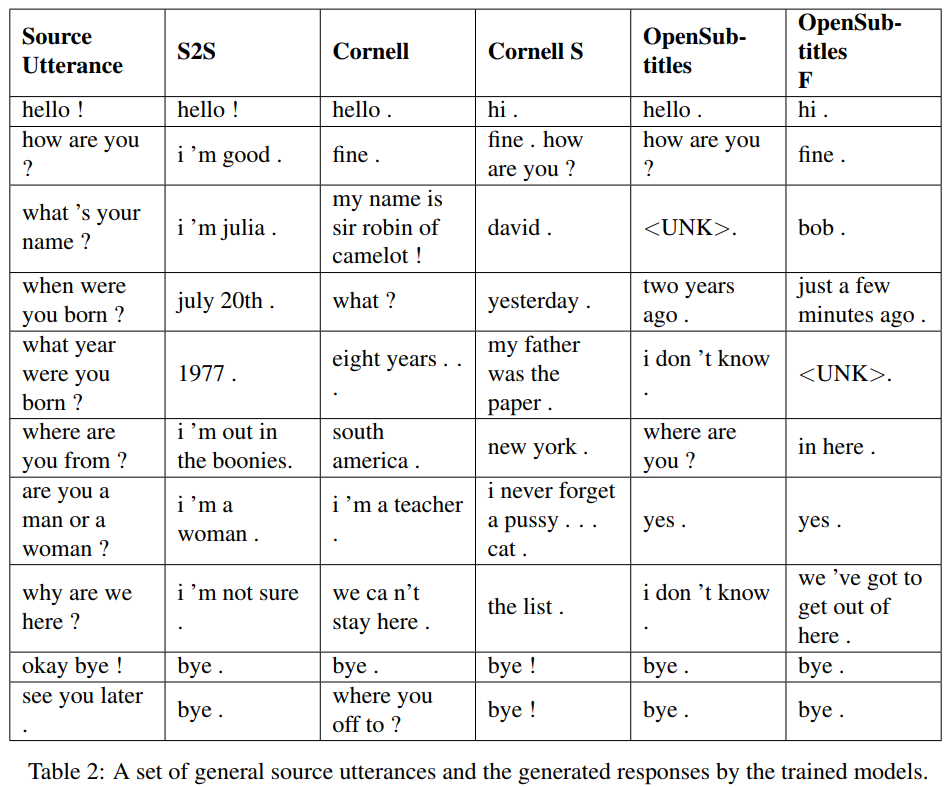
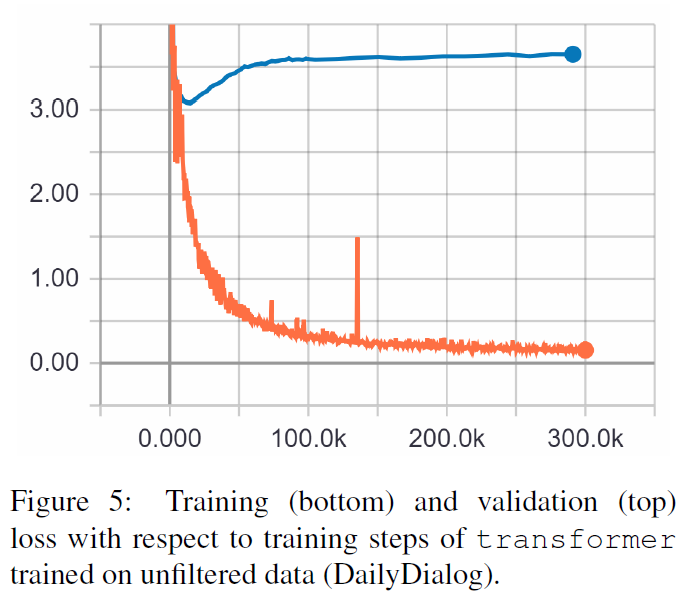

TRF ist das Transformer-Modell, während RT zufällig ausgewählte Antworten aus dem Trainingssatz und GT Ground-Truth-Antworten bedeutet. Eine Erläuterung der Metriken finden Sie im Dokument.
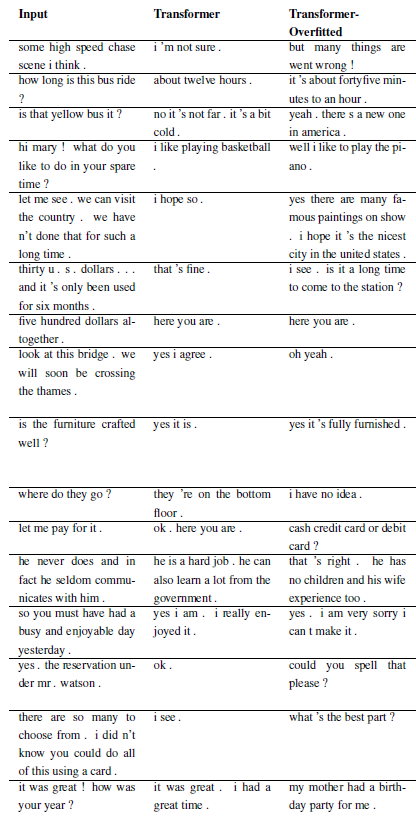
Neue Probleme können durch Unterklassen von WordChatbot oder noch besser durch Unterklassen von CornellChatbotBasic oder OpensubtitleChatbot registriert werden, da diese einige zusätzliche Funktionalitäten implementieren. Normalerweise reicht es aus, die Funktionen preprocess und create_data zu überschreiben. Weitere Informationen finden Sie in der Dokumentation. Ein Beispiel finden Sie unter daily_dialog_chatbot.
Neue Modelle und Hyperparameter können hinzugefügt werden, indem Sie dem tensor2tensor-Tutorial folgen.
Richard Csaky (Wenn Sie Hilfe beim Ausführen des Codes benötigen: [email protected])
Dieses Projekt ist unter der MIT-Lizenz lizenziert – Einzelheiten finden Sie in der LIZENZ-Datei.
Bitte fügen Sie einen Link zu diesem Repo hinzu, wenn Sie es in Ihrer Arbeit verwenden und erwägen Sie, das folgende Dokument zu zitieren:
@InProceedings{Csaky:2017,
title = {Deep Learning Based Chatbot Models},
author = {Csaky, Richard},
year = {2019},
publisher={National Scientific Students' Associations Conference},
url ={https://tdk.bme.hu/VIK/DownloadPaper/asdad},
note={https://tdk.bme.hu/VIK/DownloadPaper/asdad}
} 

