turing
v0.3.8
Viglet Turing ES (https://openviglet.github.io/turing/) ist eine Open-Source-Lösung (https://github.com/openturing), deren Hauptfunktionen Semantische Navigation und Chat-Bot sind. Zur Anreicherung der Daten können Sie aus mehreren NLPs wählen. Alle Inhalte werden in Solr als Suchmaschine indiziert.
Technische Dokumentation zu Turing ES ist unter https://openviglet.github.io/docs/turing/ verfügbar.
Um Turing ES auszuführen, führen Sie einfach die folgenden Zeilen aus:
# Turing Appmvn -Dmaven.repo.local=D:repo spring-boot:run -pl turing-app -Dskip.npm# Neue Turing ES-Benutzeroberfläche mit Angular 18 und Primer CSS.cd turing-ui## Loginng dienen willkommen## Consoleng dient der Konsole## Suche dient dem SN## Chatbotng dient der Konverse
Sie können Turing ES mit MariaDB, Solr und Nginx starten.
Docker-Komponieren
Verwaltungskonsole: http://localhost:2700. (admin/admin)
Beispiel für semantische Navigation: http://localhost:2700/sn/Sample.
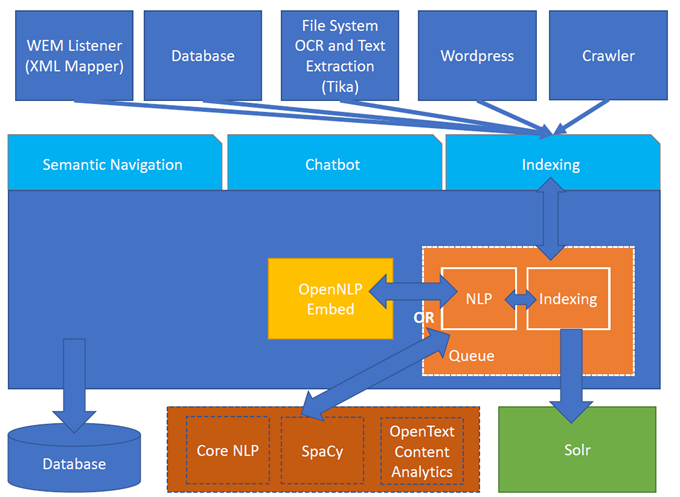
Abbildung 1. Turing ES-Architektur
Turing unterstützt die folgenden Anbieter:
Apache OpenNLP ist ein auf maschinellem Lernen basierendes Toolkit für die Verarbeitung natürlichsprachlicher Texte.
Website: https://opennlp.apache.org/
Es wandelt Daten in Erkenntnisse für eine bessere Entscheidungsfindung und ein besseres Informationsmanagement um und setzt gleichzeitig Ressourcen und Zeit frei.
Website: https://www.opentext.com/
CoreNLP ist Ihr One-Stop-Shop für die Verarbeitung natürlicher Sprache in Java! CoreNLP ermöglicht es Benutzern, sprachliche Anmerkungen für Text abzuleiten, einschließlich Token- und Satzgrenzen, Wortarten, benannte Entitäten, numerische und Zeitwerte, Abhängigkeits- und Wahlkreisanalysen, Koreferenz, Stimmung, Zitatzuschreibungen und Beziehungen. CoreNLP unterstützt derzeit 6 Sprachen: Arabisch, Chinesisch, Englisch, Französisch, Deutsch und Spanisch.
Website: https://stanfordnlp.github.io/CoreNLP/,
Es handelt sich um eine kostenlose Open-Source-Bibliothek für die Verarbeitung natürlicher Sprache in Python. Es bietet NER, POS-Tagging, Abhängigkeitsanalyse, Wortvektoren und mehr.
Website: https://spacy.io
Polyglot ist eine Pipeline in natürlicher Sprache, die umfangreiche mehrsprachige Anwendungen unterstützt.
Website: https://polyglot.readthedocs.io
Es kann PDFs und Dokumente lesen und in einfachen Text konvertieren und verwendet außerdem OCR, um Text in Bildern zu erkennen und Bilder in Dokumente umzuwandeln.
Semantische Navigation verwendet Connectors, um den Inhalt aus vielen Quellen zu indizieren.
Plugin für Apache Nutch zur Indizierung von Inhalten mithilfe eines Crawlers.
Erfahren Sie mehr unter https://docs.viglet.com/turing/connectors/#nutch
Befehlszeile, die das gleiche Konzept wie sqoop (https://sqoop.apache.org/) verwendet, um komplexe Abfragen zu erstellen und Attribute zuzuordnen, die auf der Grundlage des Ergebnisses indiziert werden.
Erfahren Sie mehr unter https://docs.viglet.com/turing/connectors/#database
Befehlszeile zum Indizieren von Dateien, Extrahieren von Text aus Dateien wie Word, Excel, PDF, einschließlich Bildern, durch OCR.
Erfahren Sie mehr unter https://docs.viglet.com/turing/connectors/#file-system
OpenText WEM Listener zum Veröffentlichen von Inhalten auf Viglet Turing.
Erfahren Sie mehr unter https://docs.viglet.com/turing/connectors/#wem
WordPress-Plugin, mit dem Sie Beiträge indizieren können.
Erfahren Sie mehr unter https://docs.viglet.com/turing/connectors/#wordpress
Mit NLP ist es möglich, Entitäten zu erkennen wie:
Menschen
Orte
Organisationen
Geld
Zeit
Prozentsatz
Definieren Sie Attribute, die als Filter für Ihre Navigation verwendet werden, und konsolidieren Sie so den Gesamtinhalt in Ihrer Anzeige
Durch in den Inhalten definierte Attribute ist es möglich, deren Anzeige anhand des Benutzerprofils einzuschränken.
Die Java-API (https://github.com/openturing/turing-java-sdk) erleichtert die Verwendung und den Zugriff auf Viglet Turing ES, ohne dass Verbrauchersuchinhalte mit komplexen Abfragen erforderlich sind.
Kommunizieren Sie mit Ihrem Kunden und erarbeiten Sie komplexe Absichten, holen Sie Berichte ein und entwickeln Sie Ihre Interaktion schrittweise weiter.
Seine Bestandteile:
Verwaltet Gespräche mit Ihren Endbenutzern. Es handelt sich um ein Modul zur Verarbeitung natürlicher Sprache, das die Nuancen der menschlichen Sprache versteht
Eine Absicht kategorisiert die Absicht eines Endbenutzers, eine Gesprächsschicht zu übernehmen. Für jeden Agenten definieren Sie mehrere Absichten, wobei Ihre kombinierten Absichten ein komplettes Gespräch abwickeln können.
Das Aktionsfeld ist ein einfaches praktisches Feld, das bei der Ausführung der Logik im Dienst hilft.
Jeder Absichtsparameter verfügt über einen Typ, einen sogenannten Entitätstyp, der genau vorgibt, wie die Daten in einem Endbenutzerausdruck extrahiert werden.
Definiert und korrigiert Absichten.
Zeigt den Gesprächsverlauf und die Berichte an.
Turing ES erkennt Entitäten von OpenText Blazon-Dokumenten mithilfe von OCR und NLP und generiert Blazon-XML, um die Entitäten im Dokument anzuzeigen.
Turing ES besteht aus vielen Komponenten: Suchmaschine, NLP, Converse (Chatbot), semantische Navigation
Beim Zugriff auf Turing ES wird eine Anmeldeseite angezeigt. Standardmäßig lautet der Benutzername/das Passwort admin / admin
Abbildung 2. Anmeldeseite
Die Suchmaschine wird von Turing verwendet, um Daten von Converse (Chat-Bot) und semantischen Navigationsseiten zu speichern und abzurufen.
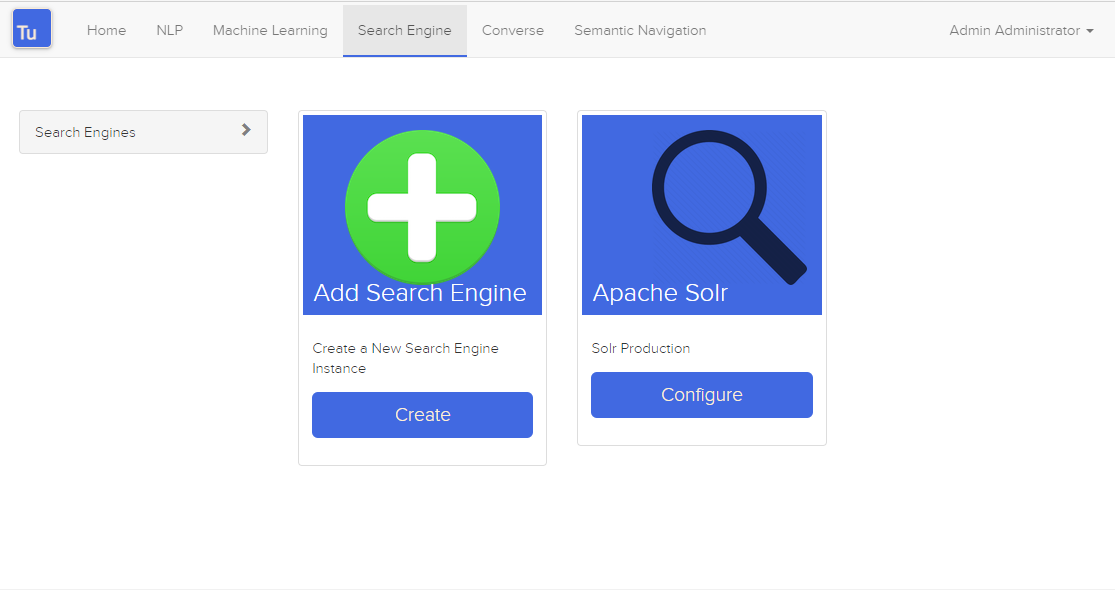
Abbildung 3. Suchmaschinenseite
Es ist möglich, eine Suchmaschine mit folgenden Attributen zu erstellen oder zu bearbeiten:
| Attribut | Beschreibung |
|---|---|
Name | Name der Suchmaschine |
Beschreibung | Beschreibung der Suchmaschine |
Verkäufer | Wählen Sie den Anbieter der Suchmaschine aus. Derzeit wird nur Solr unterstützt. |
Gastgeber | Hostname, auf dem der Suchmaschinendienst installiert ist |
Hafen | Port des Suchmaschinendienstes |
Sprache | Sprache des Suchmaschinendienstes. |
Ermöglicht | Wenn die Suchmaschine aktiviert ist. |
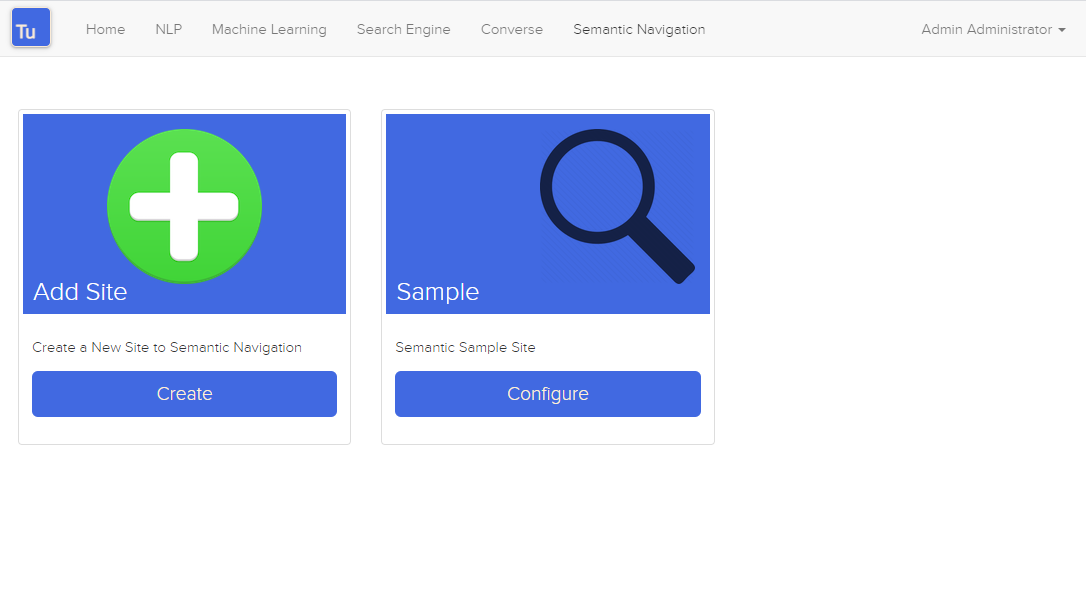
Abbildung 4. Semantische Navigationsseite
Das Detail der semantischen Navigationsseite enthält die folgenden Attribute:
| Attribut | Beschreibung |
|---|---|
Name | Name der semantischen Navigationsseite. |
Beschreibung | Beschreibung der semantischen Navigationsseite. |
Suchmaschine | Wählen Sie die Suchmaschine aus, die im Abschnitt „Suchmaschine“ erstellt wurde. Die Semantic Navigation Site verwendet diese Suchmaschine zum Speichern und Abrufen von Daten. |
NLP | Wählen Sie das NLP aus, das im NLP-Bereich erstellt wurde. Die Semantic Navigation Site verwendet dieses NLP, um Entitäten während der Indizierung zu erkennen. |
Thesaurus | Wenn Sie Thesaurus verwenden. |
Sprache | Sprache der semantischen Navigationsseite. |
Kern | Name des Kerns der Suchmaschine, in dem die Daten gespeichert und abgerufen werden. |
Die Registerkarte „Felder“ enthält eine Tabelle mit den folgenden Spalten: „Semantic Navigation Site Fields Columns“.
| Spaltenname | Beschreibung |
|---|---|
Typ | Art des Feldes. Es kann sein: - NER (Named Entity Recognition), verwendet von NLP. - Von Solr verwendete Suchmaschine. |
Feld | Name des Feldes. |
Ermöglicht | Ob das Feld aktiviert ist oder nicht. |
MLT | Wenn dieses Feld in MLT verwendet wird. |
Facetten | Um dieses Feld wie eine Facette (Filter) zu verwenden |
Hervorhebung | In diesem Feld werden hervorgehobene Zeilen angezeigt. |
NLP | Wenn dieses Feld von NLP verarbeitet wird, um Entitäten (NER) wie Personen, Organisation und Ort zu erkennen. |
Wenn Sie in das Feld klicken, erscheint eine neue Seite mit Felddetails mit den folgenden Attributen:
| Attribut | Beschreibung |
|---|---|
Name | Name des Feldes |
Beschreibung | Beschreibung des Feldes |
Typ | Art des Feldes. Es kann sein: |
Mehrfach bewertet | If ist ein Array |
Facettenname | Name der Facettenbezeichnung (Filter) auf der Suchseite. |
Facette | Um dieses Feld wie eine Facette (Filter) zu verwenden |
Hervorhebung | In diesem Feld werden hervorgehobene Zeilen angezeigt. |
MLT | Wenn dieses Feld in MLT verwendet wird. |
Ermöglicht | Wenn das Feld aktiviert ist. |
Erforderlich | Wenn das Feld erforderlich ist. |
Standardwert | Falls der Inhalt ohne dieses Feld indiziert wird, ist dies der Standardwert. |
NLP | Wenn dieses Feld von NLP verarbeitet wird, um Entitäten (NER) wie Personen, Organisation und Ort zu erkennen. |
Enthält die folgenden Attribute:
| Abschnitt | Attribut | Beschreibung |
|---|---|---|
Aussehen | Anzahl der Elemente pro Seite | Anzahl der Elemente, die in der Suche angezeigt werden. |
Facette | Facette aktiviert? | Wenn dies der Fall ist, werden Facetten (Filter) bei der Suche angezeigt. |
Anzahl der Elemente pro Facette | Anzahl der Elemente, die in jeder Facette (Filter) angezeigt werden. | |
Hervorhebung | Hervorhebung aktiviert? | Legen Sie fest, ob hervorgehobene Zeilen angezeigt werden sollen. |
Vor-Tag | HTML-Tag, das zu Beginn des Semesters verwendet wird. Beispiel: <Markierung> | |
Beitrags-Tag | HTML-Tag, das am Ende des Semesters verwendet wird. Zum Beispiel: </mark> | |
MLT | Mehr davon aktiviert? | Legen Sie fest, ob MLT angezeigt werden soll |
Standardfelder | Titel | Feld, das als Titel verwendet wird, der in Solr schema.xml definiert ist |
Text | Feld, das als Titel verwendet wird, der in Solr schema.xml definiert ist | |
Beschreibung | Feld, das als Beschreibung verwendet wird und in Solr schema.xml definiert ist | |
Datum | Feld, das als Datum verwendet wird, das in Solr schema.xml definiert ist | |
Bild | Feld, das als Bild-URL verwendet wird, die in Solr schema.xml definiert ist | |
URL | Feld, das als URL verwendet wird, die in Solr schema.xml definiert ist |
Klicken Sie in Turing ES Console > Semantic Navigation > <SITE_NAME> auf die Schaltfläche Configure und dann auf die Schaltfläche Search Page .
Es öffnet sich eine Suchseite, die das folgende Muster verwendet:
GET http://localhost:2700/sn/<SITE_NAME>
Diese Seite fordert die Turing Rest API über AJAX an. Um beispielsweise alle Ergebnisse der Semantic Navigation Site im JSON-Format zurückzugeben:
GET http://localhost:2700/api/sn/<SITE_NAME>/search?p=1&q=*&sort=relevance
| Attribut | Erforderlich / Optional | Beschreibung | Beispiel |
|---|---|---|---|
Q | Erforderlich | Suchanfrage. | q=foo |
P | Erforderlich | Seitenzahl, erste Seite ist 1. | p=1 |
Sortieren | Erforderlich | Sortierwerte: | sort=Relevanz |
fq[] | Optional | Abfragefeld. Filtern Sie nach Feld und verwenden Sie dabei das folgende Muster: FIELD : VALUE . | fq[]=title:bar |
tr[] | Optional | Targeting-Regel. Suche einschränken basierend auf: FELD : WERT . | tr[]=Abteilung:foobar |
Reihen | Optional | Anzahl der Zeilen, die die Abfrage zurückgibt. | Zeilen=10 |
Im Intranet der Versicherungsgesellschaft werden OpenText WEM und OpenText Portal integriert mit dem Dynamic Portal Module verwendet. In Viglet Turing ES wurde eine konsolidierte Suche unter Verwendung der Konnektoren WEM, Datenbank mit Dateisystem erstellt. Auf diese Weise war es möglich, alle Inhalte und Dateien des Such-Intranets mit Targeting-Regeln anzuzeigen, die nur die Anzeige von Inhalten ermöglichten, für die der Benutzer eine Berechtigung hat. Das OpenText-Portal greift auf die Java-API von Viglet Turing ES zu, sodass keine komplexen Abfragen erstellt werden mussten, um die Ergebnisse zurückzugeben.
Es wurde eine Reihe von API Rest erstellt, um Partnern alle Inhalte von Regierungsunternehmen zur Verfügung zu stellen. Alle diese Inhalte befinden sich in OpenText WEM und der WEM-Connector wurde verwendet, um die Inhalte auf Viglet Turing ES zu indizieren. Mit dem Rest-API-Satz wurde eine Spring Boot-Anwendung erstellt, die Turing ES-Inhalte über die Viglet Turing ES Java API nutzt.
Die Website der brasilianischen Universität wurde mit Viglet Shio CMS (https://viglet.com/shio) entwickelt und alle Inhalte werden automatisch in Viglet Turing ES indiziert. Diese Konfiguration wurde in der Inhaltsmodellierung vorgenommen und die Entwicklung der Suchvorlage erfolgte im Viglet Shio CMS.


