GenDataAttribution
1.0.0
Projekt | Papier
Sheng-Yu Wang 1 , Alexei A. Efros 2 , Jun-Yan Zhu 1 , Richard Zhang 3 .
Carnegie Mellon University 1 , UC Berkeley 2 , Adobe Research 2
Im ICCV, 2023.
Während große Text-zu-Bild-Modelle in der Lage sind, „neuartige“ Bilder zu synthetisieren, spiegeln diese Bilder zwangsläufig die Trainingsdaten wider. Das Problem der Datenzuordnung in solchen Modellen – welche der Bilder im Trainingssatz sind am meisten für das Erscheinungsbild eines bestimmten generierten Bildes verantwortlich – ist schwierig und dennoch wichtig. Als ersten Schritt zur Lösung dieses Problems bewerten wir die Attribution durch „Anpassungs“-Methoden, die ein vorhandenes groß angelegtes Modell auf ein bestimmtes Musterobjekt oder einen bestimmten Stil abstimmen. Unsere wichtigste Erkenntnis ist, dass wir dadurch effizient synthetische Bilder erstellen können, die durch die Konstruktion des Exemplars rechnerisch beeinflusst werden. Mit unserem neuen Datensatz solcher exemplarisch beeinflussten Bilder sind wir in der Lage, verschiedene Datenattributionsalgorithmen und verschiedene mögliche Merkmalsräume zu evaluieren. Darüber hinaus können wir durch Training an unserem Datensatz Standardmodelle wie DINO, CLIP und ViT auf das Attributionsproblem abstimmen. Obwohl das Verfahren auf kleine Exemplarmengen abgestimmt ist, zeigen wir eine Verallgemeinerung auf größere Mengen. Unter Berücksichtigung der inhärenten Unsicherheit des Problems können wir schließlich weiche Attributionswerte für eine Reihe von Trainingsbildern zuweisen.
conda env create -f environment.yaml
conda activate gen-attr # Download precomputed features of 1M LAION images
bash feats/download_laion_feats.sh
# Download jpeg-ed 1M LAION images for visualization
bash dataset/download_dataset.sh laion_jpeg
# Download pretrained models
bash weights/download_weights.sh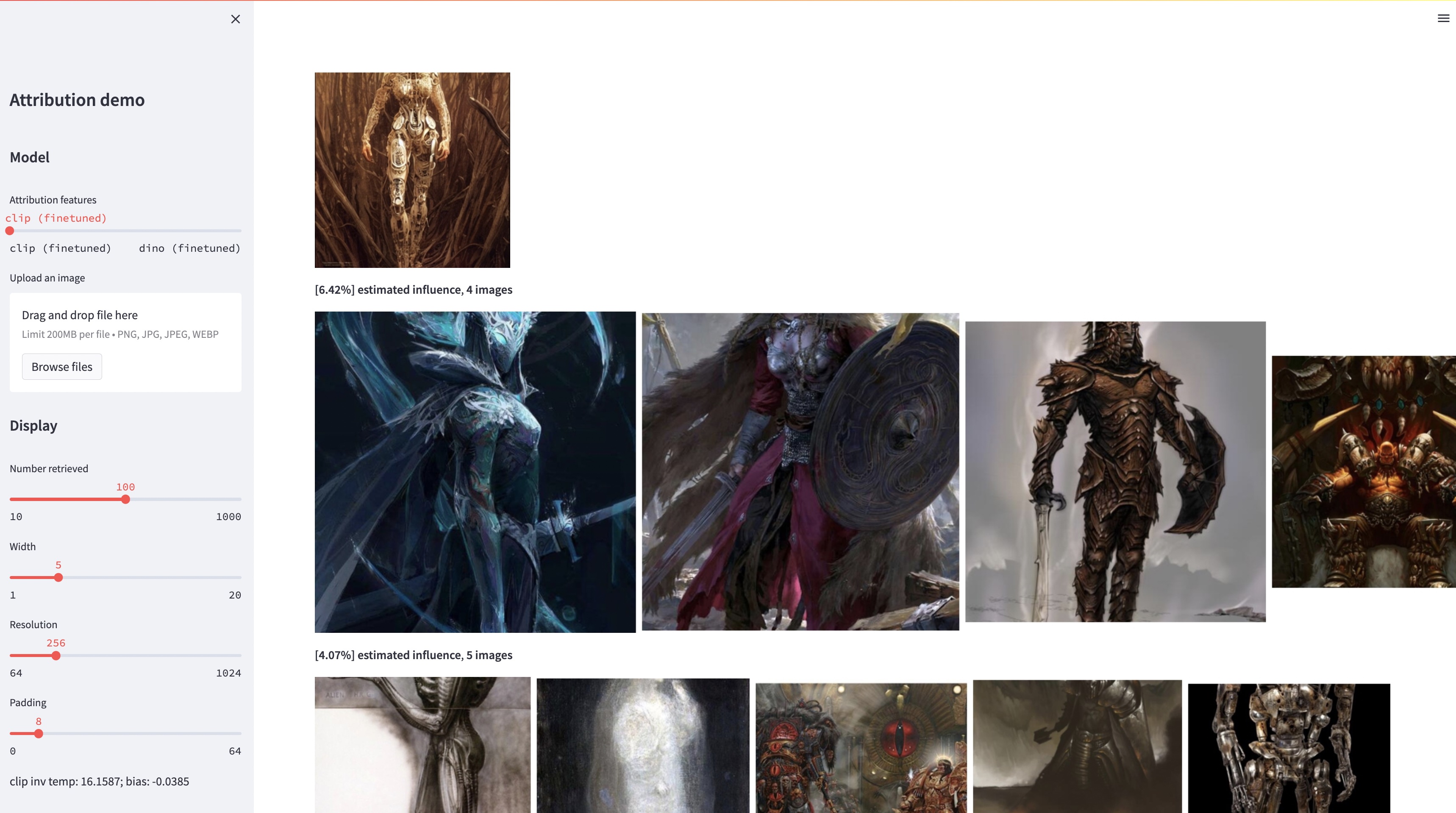
streamlit run streamlit_demo.pyWir geben unser Testset zur Evaluierung frei. So laden Sie den Datensatz herunter:
# Download the exemplar real images
bash dataset/download_dataset.sh exemplar
# Download the testset portion of images synthesized from Custom Diffusion
bash dataset/download_dataset.sh testset
# (Optional, can download precomputed features instead!)
# Download the uncompressed 1M LAION subset in pngs
bash dataset/download_dataset.sh laionDer Datensatz ist wie folgt aufgebaut:
dataset
├── exemplar
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── synth
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── laion_subset
└── json
├──test_artchive.json
├──test_bamfg.json
├──...
Alle Exemplarbilder werden in dataset/exemplar gespeichert, alle synthetisierten Bilder werden in dataset/synth gespeichert und 1 Mio. Laion-Bilder in PNGs werden in dataset/laion_subset gespeichert. Die JSON-Dateien in dataset/json geben die Train-/Val-/Test-Aufteilungen einschließlich verschiedener Testfälle an und dienen als Ground-Truth-Labels. Jeder Eintrag in einer JSON-Datei ist ein einzigartiges, fein abgestimmtes Modell. Ein Eintrag zeichnet auch die für die Feinabstimmung verwendeten Beispielbilder und die vom Modell generierten synthetisierten Bilder auf. Wir haben vier Testfälle: test_artchive.json , test_bamfg.json , test_observed_imagenet.json und test_unobserved_imagenet.json .
Nachdem der Testsatz, vorberechnete LAION-Funktionen und vorab trainierte Gewichte heruntergeladen wurden, können wir die Funktionen aus dem Testsatz vorab berechnen, indem wir extract_feat.py ausführen, und dann die Leistung bewerten, indem wir eval.py ausführen. Nachfolgend finden Sie die Bash-Skripte, mit denen die Auswertung stapelweise ausgeführt wird:
# precompute all features from the testset
bash scripts/preprocess_feats.sh
# run evaluation in batches
bash scripts/run_eval.sh Die Messwerte werden in .pkl Dateien in results gespeichert. Derzeit führt das Skript jeden Befehl nacheinander aus. Bitte ändern Sie es, um die Befehle parallel auszuführen. Der folgende Befehl analysiert die .pkl -Dateien in Tabellen, die als .csv Dateien gespeichert sind:
python results_to_csv.py Update vom 18.12.2023 Um Modelle herunterzuladen, die nur auf objektzentrierten oder stilzentrierten Modellen trainiert wurden, führen Sie bash weights/download_style_object_ablation.sh aus
@inproceedings{wang2023evaluating,
title={Evaluating Data Attribution for Text-to-Image Models},
author={Wang, Sheng-Yu and Efros, Alexei A. and Zhu, Jun-Yan and Zhang, Richard},
booktitle={ICCV},
year={2023}
}
Wir danken Aaron Hertzmann für die Lektüre eines früheren Entwurfs und für sein aufschlussreiches Feedback. Wir danken den Kollegen von Adobe Research, darunter Eli Shechtman, Oliver Wang, Nick Kolkin, Taesung Park, John Collomosse und Sylvain Paris, sowie Alex Li und Yonglong Tian für hilfreiche Diskussionen. Wir danken Nupur Kumari für die Anleitung beim Custom Diffusion-Training, Ruihan Gao für das Korrekturlesen des Entwurfs, Alex Li für Hinweise zum Extrahieren von Stable Diffusion-Funktionen und Dan Ruta für die Hilfe beim BAM-FG-Datensatz. Wir danken Bryan Russell für das Pandemie-Wandern und Brainstorming. Diese Arbeit begann, als SYW ein Adobe-Praktikant war, und wurde teilweise durch eine Adobe-Spende und den JP Morgan Chase Faculty Research Award unterstützt.


