clearml fractional gpu
1.0.0
? Leave a star to support the project! ?
Die gemeinsame Nutzung von High-End-GPUs oder sogar Prosumer- und Consumer-GPUs zwischen mehreren Benutzern ist die kostengünstigste Möglichkeit, die KI-Entwicklung zu beschleunigen. Leider galt bisher die einzige existierende Lösung für MIG/Slicing-High-End-GPUs (A100+) und erforderte Kubernetes.
? Willkommen bei der Container-basierten fraktionierten GPU für jede Nvidia-Karte! ?
Wir präsentieren vorgefertigte Container, die CUDA 11.x und CUDA 12.x mit vorgefertigter Festplattenspeicherbeschränkung unterstützen! Dies bedeutet, dass mehrere Container auf derselben GPU gestartet werden können, wodurch sichergestellt wird, dass ein Benutzer nicht den gesamten Host-GPU-Speicher zuweisen kann! (Keine gierigen Prozesse mehr, die den gesamten GPU-Speicher beanspruchen! Endlich haben wir eine Option zur harten Speicherbegrenzung auf Treiberebene).
ClearML bietet mehrere Optionen zur Optimierung der GPU-Ressourcennutzung durch Partitionierung von GPUs:
Mit diesen Optionen ermöglicht ClearML die Ausführung von KI-Workloads mit optimierter Hardwareauslastung und Workload-Leistung. Dieses Repository deckt Container-basierte Teil-GPUs ab. Weitere Informationen zu den Teil-GPU-Angeboten von ClearML finden Sie in der ClearML-Dokumentation.
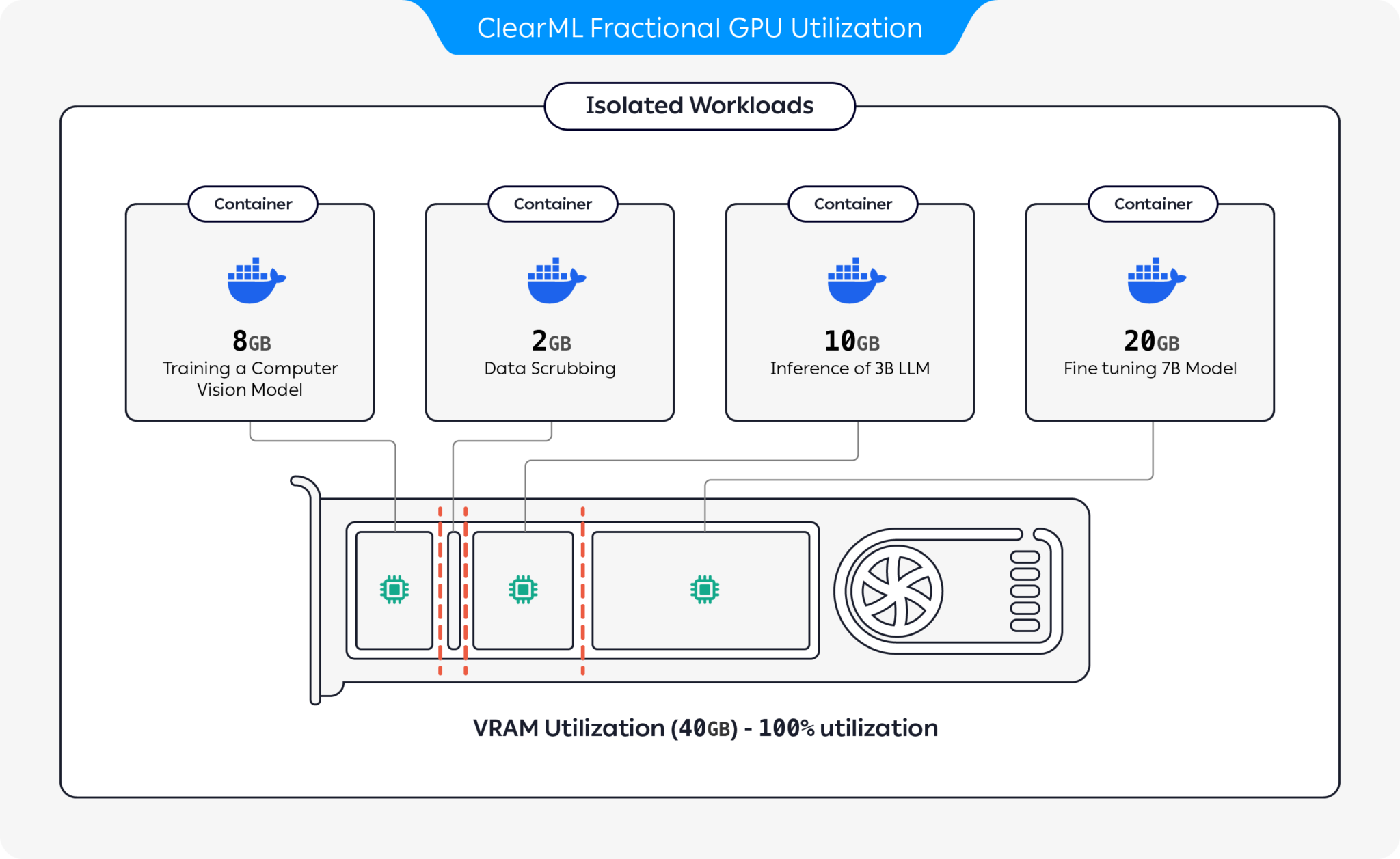
Wählen Sie den für Sie geeigneten Container aus und starten Sie ihn:
docker run -it --gpus 0 --ipc=host --pid=host clearml/fractional-gpu:u22-cu12.3-8gb bashFühren Sie Folgendes im Container aus, um zu überprüfen, ob das Bruchteil-GPU-Speicherlimit ordnungsgemäß funktioniert:
nvidia-smiHier ist eine Beispielausgabe der A100-GPU:
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 A100-PCIE-40GB Off | 00000000:01:00.0 Off | N/A |
| 32% 33C P0 66W / 250W | 0MiB / 8128MiB | 3% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
| Speicherlimit | CUDA Ver | Ubuntu Ver | Docker-Image |
|---|---|---|---|
| 12 GiB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-12gb |
| 12 GiB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-12gb |
| 12 GiB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-12gb |
| 12 GiB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-12gb |
| 8 GiB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-8gb |
| 8 GiB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-8gb |
| 8 GiB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-8gb |
| 8 GiB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-8gb |
| 4 GiB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-4gb |
| 4 GiB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-4gb |
| 4 GiB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-4gb |
| 4 GiB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-4gb |
| 2 GiB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-2gb |
| 2 GiB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-2gb |
| 2 GiB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-2gb |
| 2 GiB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-2gb |
Wichtig
Sie müssen den Container mit --pid=host ausführen!
Notiz
--pid=host ist erforderlich, damit der Treiber beim Begrenzen der Speicher-/Auslastungsnutzung zwischen den Prozessen des Containers und anderen Hostprozessen unterscheiden kann
Tipp
ClearML-Agent-Benutzer fügen [--pid=host] zum Abschnitt agent.extra_docker_arguments in Ihrer Konfigurationsdatei hinzu
Erstellen Sie Ihre eigenen Container und erben Sie die Originalcontainer.
Ein paar Beispiele finden Sie hier.
Fraktionierte GPU-Container können sowohl für Bare-Metal-Ausführungen als auch für Kubernetes-PODs verwendet werden. Ja! Durch die Verwendung eines der fraktionierten GPU-Container können Sie den Speicherverbrauch Ihres Jobs/Pods begrenzen und GPUs problemlos gemeinsam nutzen, ohne befürchten zu müssen, dass sie sich gegenseitig zum Speicherabsturz bringen!
Hier ist eine einfache Kubernetes-POD-Vorlage:
apiVersion : v1
kind : Pod
metadata :
name : train-pod
labels :
app : trainme
spec :
hostPID : true
containers :
- name : train-container
image : clearml/fractional-gpu:u22-cu12.3-8gb
command : ['python3', '-c', 'print(f"Free GPU Memory: (free, global) {torch.cuda.mem_get_info()}")'] Wichtig
Sie müssen den Pod mit hostPID: true !
Notiz
hostPID: true ist erforderlich, damit der Treiber beim Begrenzen der Speicher-/Auslastungsnutzung zwischen den Prozessen des Pods und anderen Hostprozessen unterscheiden kann
Die Container unterstützen Nvidia-Treiber <= 545.xx Wir werden weiterhin neue Treiber aktualisieren und unterstützen, sobald diese veröffentlicht werden
Unterstützte GPUs : RTX-Serie 10, 20, 30, 40, A-Serie und Data-Center P100, A100, A10/A40, L40/s, H100
Einschränkungen : Windows-Hostmaschinen werden derzeit nicht unterstützt. Wenn dies für Sie wichtig ist, hinterlassen Sie eine Anfrage im Abschnitt „Probleme“.
F : Wird beim Ausführen nvidia-smi im Container der GPU-Verbrauch lokaler Prozesse gemeldet?
A : Ja, nvidia-smi kommuniziert direkt mit den Low-Level-Treibern und meldet sowohl den genauen Container-GPU-Speicher als auch die lokale Speicherbeschränkung des Containers.
Beachten Sie, dass es sich bei der GPU-Auslastung um die globale (dh hostseitige) GPU-Auslastung und nicht um die spezifische GPU-Auslastung des lokalen Containers handelt.
F : Wie stelle ich sicher, dass mein Python/Pytorch/Tensorflow tatsächlich speicherbegrenzt ist?
A : Für PyTorch können Sie Folgendes ausführen:
import torch
print ( f'Free GPU Memory: (free, global) { torch . cuda . mem_get_info () } ' )Numba-Beispiel:
from numba import cuda
print ( f'Free GPU Memory: { cuda . current_context (). get_memory_info () } ' ) F : Kann die Beschränkung von einem Benutzer aufgehoben werden?
A : Wir sind sicher, dass ein böswilliger Benutzer einen Weg finden wird. Es war nie unsere Absicht, uns vor böswilligen Benutzern zu schützen.
Wenn ein böswilliger Benutzer Zugriff auf Ihre Computer hat, sind Teil-GPUs nicht Ihr größtes Problem?
F : Wie kann ich die Speicherbeschränkung programmgesteuert erkennen?
A : Sie können die Betriebssystemumgebungsvariable GPU_MEM_LIMIT_GB überprüfen.
Beachten Sie, dass durch eine Änderung die Einschränkung weder aufgehoben noch verringert wird.
F : Ist die Ausführung des Containers mit --pid=host sicher?
A : Es sollte sowohl sicher als auch sicher sein. Der größte Nachteil aus Sicherheitsgründen besteht darin, dass ein Containerprozess jede Befehlszeile sehen kann, die auf dem Hostsystem ausgeführt wird. Wenn eine Prozessbefehlszeile ein „Geheimnis“ enthält, kann dies zu einem potenziellen Datenleck führen. Beachten Sie, dass die Weitergabe von „Geheimnissen“ in der Befehlszeile nicht ratsam ist und wir dies daher nicht als Sicherheitsrisiko betrachten. Wenn Sicherheit jedoch von entscheidender Bedeutung ist, macht die Enterprise-Edition (siehe unten) die Ausführung mit pid-host überflüssig und ist somit vollständig sicher.
F : Können Sie den Container ohne --pid=host ausführen?
A : Das kannst du! Sie müssen jedoch die Enterprise-Version des Containers „clearml-fractional-gpu“ verwenden (ansonsten gilt das Speicherlimit systemweit und nicht für den gesamten Container). Wenn diese Funktion für Sie wichtig ist, wenden Sie sich bitte an den Vertrieb und Support von ClearML.
Die Lizenz zur Nutzung von ClearML wird ausschließlich zu Forschungs- oder Entwicklungszwecken gewährt. ClearML kann für pädagogische, persönliche oder interne kommerzielle Zwecke verwendet werden.
Eine erweiterte kommerzielle Lizenz zur Nutzung innerhalb eines Produkts oder einer Dienstleistung ist als Teil der ClearML Scale- oder Enterprise-Lösung verfügbar.
ClearML bietet Unternehmens- und kommerzielle Lizenzen mit vielen zusätzlichen Funktionen zusätzlich zu Teil-GPUs, darunter Orchestrierung, Prioritätswarteschlangen, Kontingentverwaltung, Compute-Cluster-Dashboard, Datensatzverwaltung und Experimentverwaltung sowie Sicherheit und Support auf Unternehmensniveau. Erfahren Sie mehr über ClearML Orchestration oder sprechen Sie direkt mit uns im ClearML-Vertrieb.
Erzähl es allen! #ClearMLFractionalGPU
Treten Sie unserem Slack-Kanal bei
Teilen Sie uns mit, wenn etwas nicht funktioniert, und helfen Sie uns, das Problem auf der Seite „Probleme“ zu beheben
Dieses Produkt wird Ihnen vom ClearML-Team mit ❤️ präsentiert


