amazon bedrock rag
1.0.0
Bei der Retrieval-Augmented Generation (RAG) handelt es sich um den Prozess der Optimierung der Ausgabe eines großen Sprachmodells, sodass auf eine maßgebliche Wissensdatenbank außerhalb der Trainingsdatenquellen verwiesen wird, bevor eine Antwort generiert wird. Large Language Models (LLMs) werden auf riesigen Datenmengen trainiert und nutzen Milliarden von Parametern, um Originalausgaben für Aufgaben wie das Beantworten von Fragen, das Übersetzen von Sprachen und das Vervollständigen von Sätzen zu generieren. RAG erweitert die bereits leistungsstarken Funktionen von LLMs auf bestimmte Domänen oder die interne Wissensdatenbank einer Organisation, ohne dass das Modell neu trainiert werden muss. Es handelt sich um einen kostengünstigen Ansatz zur Verbesserung der LLM-Ergebnisse, sodass diese in verschiedenen Kontexten relevant, genau und nützlich bleiben. Erfahren Sie hier mehr über RAG.
Amazon Bedrock ist ein vollständig verwalteter Dienst, der über eine einzige API eine Auswahl leistungsstarker Foundation-Modelle (FMs) von führenden KI-Unternehmen wie AI21 Labs, Anthropic, Cohere, Meta, Stability AI und Amazon sowie eine breite Palette von bietet Funktionen, die Sie zum Erstellen generativer KI-Anwendungen mit Sicherheit, Datenschutz und verantwortungsvoller KI benötigen. Mit Amazon Bedrock können Sie ganz einfach mit Top-FMs für Ihren Anwendungsfall experimentieren und diese bewerten, sie mithilfe von Techniken wie Feinabstimmung und RAG privat an Ihre Daten anpassen und Agenten erstellen, die Aufgaben mithilfe Ihrer Unternehmenssysteme und Datenquellen ausführen. Da Amazon Bedrock serverlos ist, müssen Sie keine Infrastruktur verwalten und können mithilfe der AWS-Services, mit denen Sie bereits vertraut sind, generative KI-Funktionen sicher in Ihre Anwendungen integrieren und bereitstellen.
Knowledge Bases für Amazon Bedrock ist eine vollständig verwaltete Funktion, die Ihnen hilft, den gesamten RAG-Workflow von der Aufnahme bis zum Abruf und der sofortigen Erweiterung zu implementieren, ohne benutzerdefinierte Integrationen für Datenquellen erstellen und Datenflüsse verwalten zu müssen. Die Sitzungskontextverwaltung ist integriert, sodass Ihre App problemlos Gespräche mit mehreren Runden unterstützen kann.
Im Rahmen der Erstellung einer Wissensdatenbank konfigurieren Sie eine Datenquelle und einen Vektorspeicher Ihrer Wahl. Mit einem Datenquellen-Connector können Sie Ihre proprietären Daten mit einer Wissensdatenbank verbinden. Sobald Sie einen Datenquellen-Connector konfiguriert haben, können Sie Ihre Daten mit Ihrer Wissensdatenbank synchronisieren oder auf dem neuesten Stand halten und Ihre Daten für Abfragen verfügbar machen. Amazon Bedrock teilt Ihre Dokumente oder Inhalte zunächst in überschaubare Blöcke auf, um einen effizienten Datenabruf zu ermöglichen. Die Blöcke werden dann in Einbettungen umgewandelt und in einen Vektorindex (Vektordarstellung der Daten) geschrieben, wobei eine Zuordnung zum Originaldokument beibehalten wird. Die Vektoreinbettungen ermöglichen einen mathematischen Vergleich der Texte auf Ähnlichkeit.
Dieses Projekt wird mit zwei Datenquellen implementiert; eine Datenquelle für in Amazon S3 gespeicherte Dokumente und eine weitere Datenquelle für auf einer Website veröffentlichte Inhalte. Zur Vektorspeicherung wird in Amazon OpenSearch Serverless eine Vektorsuchsammlung erstellt.
Q&A-Chatbot 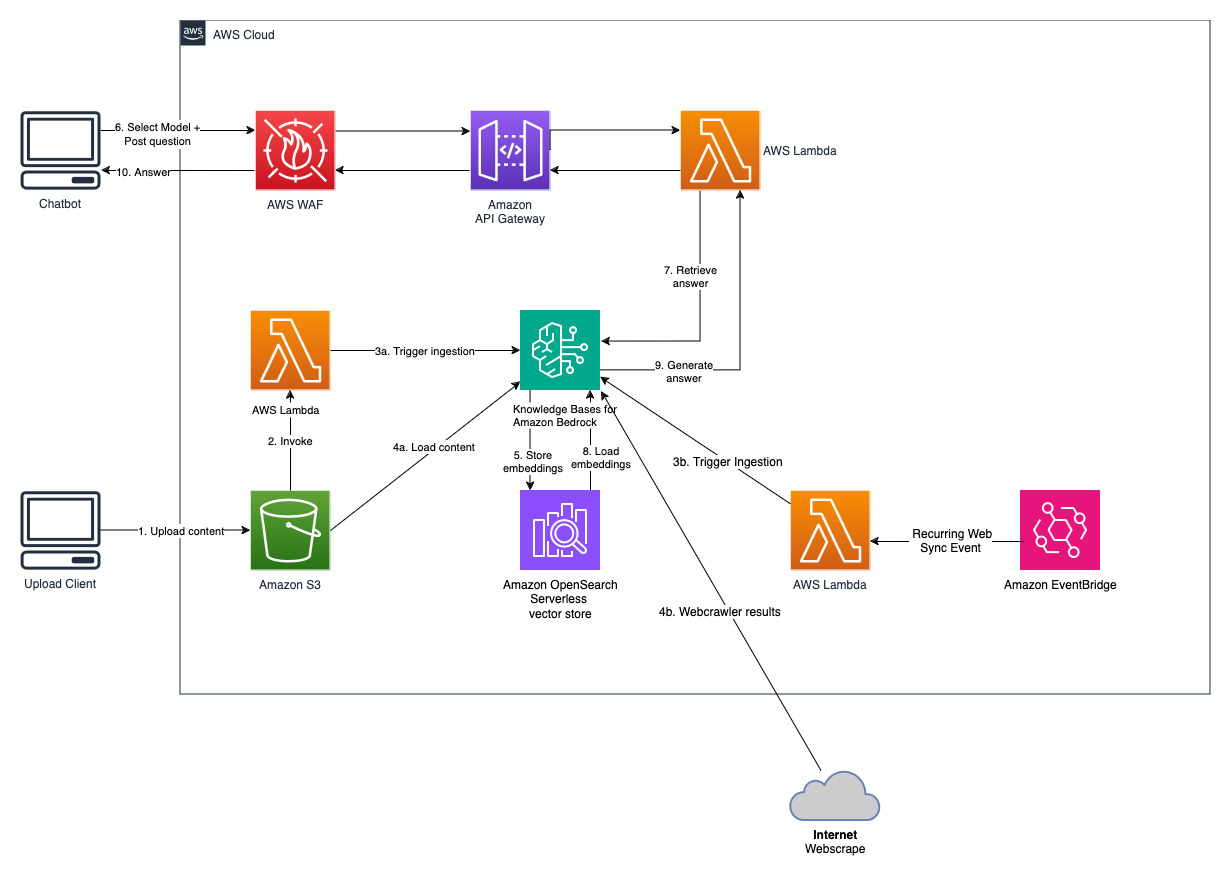
Fügen Sie neue Websites für die Webdatenquelle hinzu 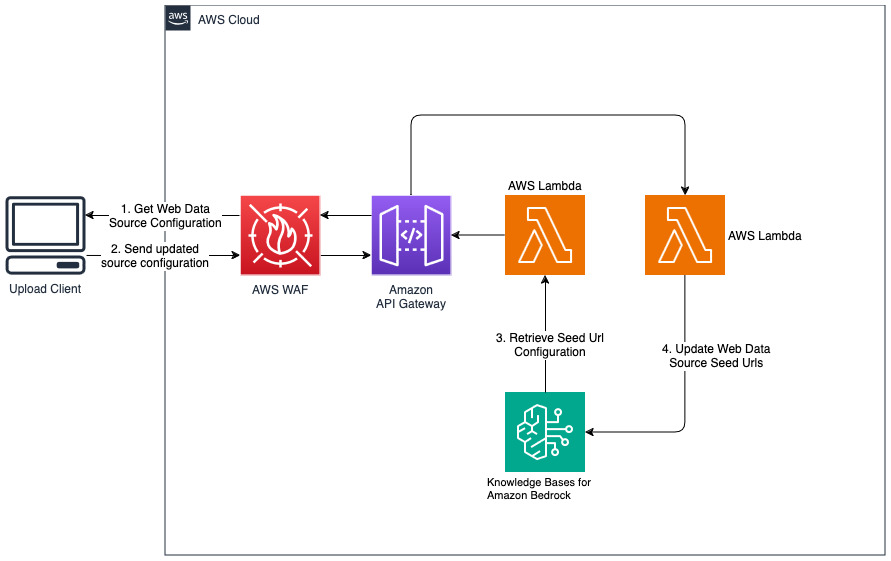
cdk deploy --context allowedip="xxx.xxx.xxx.xxx/32"
Geben Sie als Teil der Kontextvariablen „allowedip“ eine Client-IP-Adresse an, die im CIDR-Format auf das API-Gateway zugreifen darf.
Wenn die Bereitstellung abgeschlossen ist,
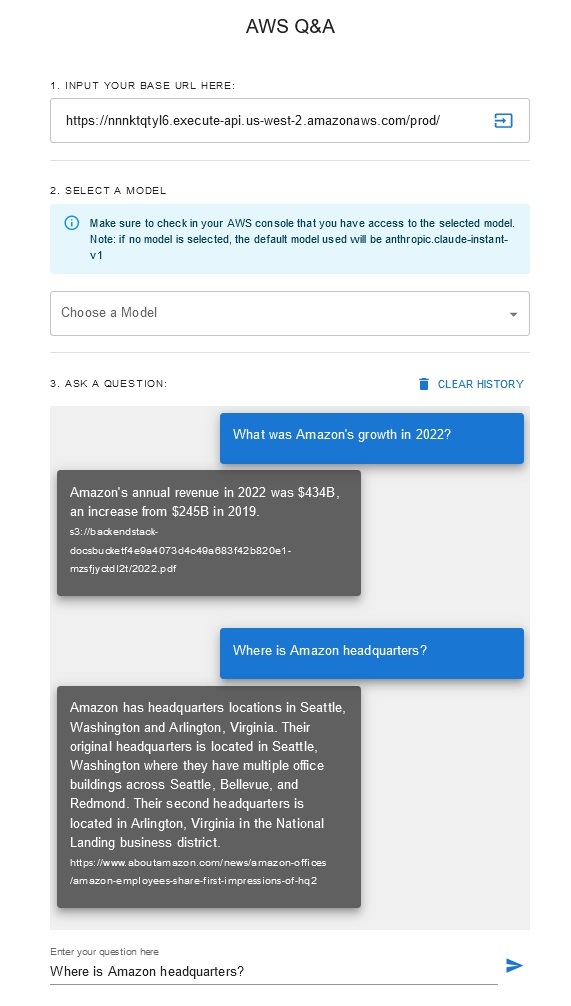
Mit dieser Lösung können Benutzer auswählen, welches grundlegende Modell sie während der Abruf- und Generierungsphase verwenden möchten. Das Standardmodell ist Anthropic Claude Instant . Für das Wissensdatenbank-Einbettungsmodell verwendet diese Lösung das Textmodell Amazon Titan Embeddings G1 . Stellen Sie sicher, dass Sie Zugriff auf diese Stiftungsmodelle haben.
Besorgen Sie sich einen aktuellen, öffentlich zugänglichen Jahresbericht von Amazon und kopieren Sie ihn in den zuvor notierten S3-Bucket-Namen. Für einen schnellen Test können Sie den Geschäftsbericht 2022 von Amazon über die AWS S3-Konsole kopieren. Der Inhalt aus dem S3-Bucket wird automatisch mit der Wissensdatenbank synchronisiert, da die Lösungsbereitstellung nach neuen Inhalten im S3-Bucket sucht und einen Aufnahmeworkflow auslöst.
Die bereitgestellte Lösung initialisiert die Webdatenquelle namens „WebCrawlerDataSource“ mit der URL https://www.aboutamazon.com/news/amazon-offices . Sie müssen diese Web Crawler-Datenquelle manuell mit der Wissensdatenbank der AWS-Konsole synchronisieren, um den Website-Inhalt zu durchsuchen, da die Website-Aufnahme für einen späteren Zeitpunkt geplant ist. Wählen Sie diese Datenquelle aus der Knowledge based on Amazon Bedrock-Konsole aus und starten Sie einen „Sync“-Vorgang. Weitere Informationen finden Sie unter Synchronisieren Ihrer Datenquelle mit Ihrer Amazon Bedrock-Wissensdatenbank. Beachten Sie, dass der Website-Inhalt dem Q&A-Chatbot erst nach Abschluss der Synchronisierung zur Verfügung steht. Bitte verwenden Sie diese Anleitung, wenn Sie Websites als Datenquelle einrichten.
Verwenden Sie „cdk destroy“, um den Stapel von Cloud-Ressourcen zu löschen, der in dieser Lösungsbereitstellung erstellt wurde.


