DeepMorphy
1.0.0
DeepMorphy ist ein auf einem neuronalen Netzwerk basierender morphologischer Analysator für die russische Sprache.
DeepMorphy ist ein morphologischer Analysator für die russische Sprache. Verfügbar als .Net Standard 2.0-Bibliothek. Dürfen:
Die Terminologie in DeepMorphy ist teilweise dem morphologischen Analysator pymorphy2 entlehnt.
Grammem (englisches Grammem) – die Bedeutung einer der grammatikalischen Kategorien eines Wortes (z. B. Vergangenheitsform, Singular, männlich).
Eine grammatikalische Kategorie ist eine Menge sich gegenseitig ausschließender Grammatiken, die ein gemeinsames Merkmal charakterisieren (z. B. Geschlecht, Zeitform, Kasus usw.). Eine Liste aller in DeepMorphy unterstützten Kategorien und Grammatiken finden Sie hier.
Tag (englischer Tag) – eine Reihe von Grammen, die ein bestimmtes Wort charakterisieren (zum Beispiel ein Tag für das Wort Hedgehog – Substantiv, Singular, Nominativ, Maskulinum).
Lemma (englisch lemma) ist die Normalform eines Wortes.
Lemmatisierung (dt. Lemmatisierung) – ein Wort in seine normale Form bringen.
Ein Lexem ist eine Menge aller Formen eines Wortes.
Das Kernelement von DeepMorphy ist das neuronale Netzwerk. Für die meisten Wörter werden die morphologische Analyse und die Lemmatisierung vom Netzwerk durchgeführt. Einige Arten von Wörtern werden von Präprozessoren verarbeitet.
Es gibt 3 Präprozessoren:
Das Netzwerk wurde auf dem Tensorflow-Framework aufgebaut und trainiert. Als Datensatz dient das Opencorpora-Wörterbuch. Integriert in .Net über TensorFlowSharp.
Der Berechnungsgraph für die Wortanalyse in DeepMorphy besteht aus 11 „Subnetzen“:
Das Problem der Änderung der Wortform wird durch ein 1 seq2seq Netzwerk gelöst.
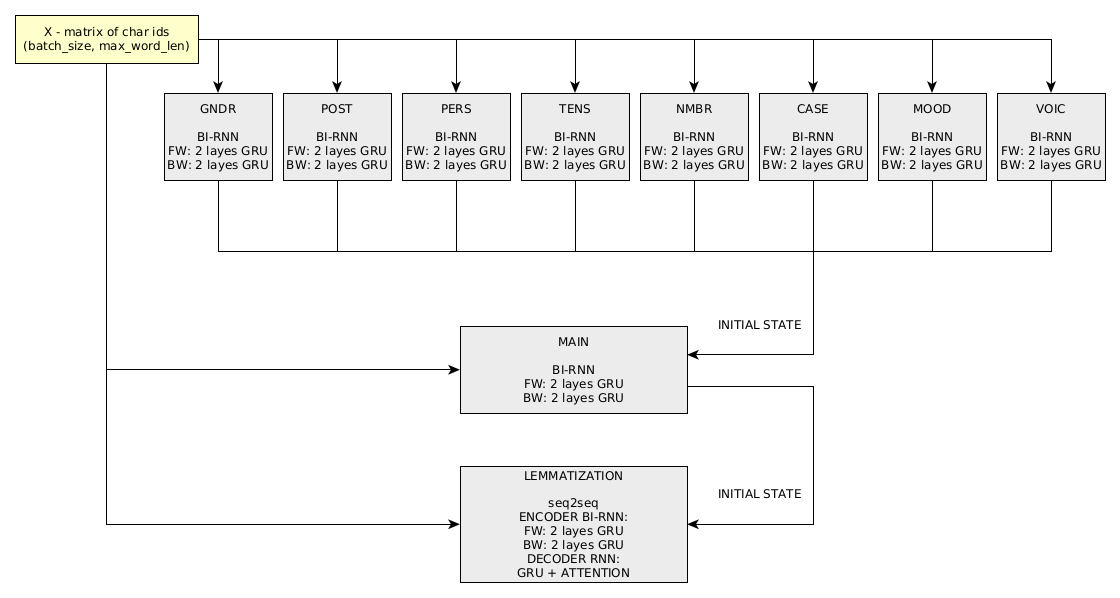
Das Training erfolgt nacheinander, zunächst werden die Netzwerke nach Kategorie trainiert (die Reihenfolge spielt keine Rolle). Als nächstes werden die Hauptklassifizierung nach Tags, die Lemmatisierung und ein Netzwerk zur Änderung der Wortform trainiert. Das Training wurde auf 3 Titan
DeepMorphy für .NET ist eine .Net Standard 2.0-Bibliothek. Die einzigen Abhängigkeiten sind die TensorflowSharp-Bibliothek (das neuronale Netzwerk wird über sie gestartet).
Die Bibliothek wird in Nuget veröffentlicht und lässt sich daher am einfachsten installieren.
Wenn es einen Paketmanager gibt:
Install-Package DeepMorphy
Wenn das Projekt PackageReference unterstützt:
<PackageReference Include="DeepMorphy"/>
Wenn jemand aus Quellen bauen möchte, dann sind die C#-Quellen hier. Für die Entwicklung wird Rider verwendet (alles sollte problemlos im Studio zusammengebaut werden).
Alle Aktionen werden über das MorphAnalyzer-Klassenobjekt ausgeführt:
var morph = new MorphAnalyzer ( ) ;Idealerweise ist es besser, es als Singleton zu verwenden; beim Erstellen eines Objekts wird einige Zeit damit verbracht, Wörterbücher und das Netzwerk zu laden. Gewindesicher. Beim Erstellen können Sie dem Konstruktor folgende Parameter übergeben:
Zum Parsen wird die Parse-Methode verwendet (sie nimmt ein IEnumerable mit Wörtern zur Analyse als Eingabe und gibt ein IEnumerable mit dem Ergebnis der Analyse zurück).
var results = morph . Parse ( new string [ ]
{
"королёвские" ,
"тысячу" ,
"миллионных" ,
"красотка" ,
"1-ый"
} ) . ToArray ( ) ;
var morphInfo = results [ 0 ] ;Die Liste der unterstützten grammatikalischen Kategorien, Gramma und ihrer Schlüssel finden Sie hier. Wenn Sie die wahrscheinlichste Kombination von Grammemen (Tags) herausfinden müssen, müssen Sie die BestTag-Eigenschaft des MorphInfo-Objekts verwenden.
// выводим лучшую комбинацию граммем для слова
Console . WriteLine ( morphInfo . BestTag ) ;Anhand des Wortes selbst ist es nicht immer möglich, die Bedeutung seiner grammatikalischen Kategorien eindeutig zu bestimmen (siehe Homonyme), daher ermöglicht DeepMorphy Ihnen, die Top-Tags für ein bestimmtes Wort anzuzeigen (Tags-Eigenschaft).
// выводим все теги для слова + их вероятность
foreach ( var tag in morphInfo . Tags )
Console . WriteLine ( $ " { tag } : { tag . Power } " ) ;Gibt es eine Kombination von Grammen in einem der Tags:
// есть ли в каком-нибудь из тегов прилагательные единственного числа
morphInfo . HasCombination ( "прил" , "ед" ) ;Gibt es eine Kombination von Grammen im wahrscheinlichsten Tag:
// ясляется ли лучший тег прилагательным единственного числа
morphInfo . BestTag . Has ( "прил" , "ед" ) ;Abrufen bestimmter Grammatikkategorien aus dem besten Tag:
// выводит часть речи лучшего тега и число
Console . WriteLine ( morphInfo . BestTag [ "чр" ] ) ;
Console . WriteLine ( morphInfo . BestTag [ "число" ] ) ;Tags werden verwendet, wenn Sie Informationen zu mehreren grammatikalischen Kategorien gleichzeitig benötigen (z. B. Wortart und Numerus). Wenn Sie nur an einer Kategorie interessiert sind, können Sie die Wahrscheinlichkeitsschnittstelle für grammatikalische Kategorien des MorphInfo-Objekts verwenden.
// выводит самую вероятную часть речи
Console . WriteLine ( morphInfo [ "чр" ] . BestGramKey ) ;Sie können die Wahrscheinlichkeitsverteilung auch nach grammatikalischer Kategorie abrufen:
// выводит распределение вероятностей для падежа
foreach ( var gram in morphInfo [ "падеж" ] . Grams )
{
Console . WriteLine ( $ " { gram . Key } : { gram . Power } " ) ;
}Wenn Sie zusammen mit der morphologischen Analyse Lemmata von Wörtern erhalten müssen, muss der Analysator wie folgt erstellt werden:
var morph = new MorphAnalyzer ( withLemmatization : true ) ;Lemmas können aus Wort-Tags gewonnen werden:
Console . WriteLine ( morphInfo . BestTag . Lemma ) ;Überprüfen, ob ein gegebenes Wort ein Lemma hat:
morphInfo . HasLemma ( "королевский" ) ;Die CanBeSameLexeme-Methode kann verwendet werden, um Wörter eines einzelnen Lexems zu finden:
// выводим все слова, которые могут быть формой слова королевский
var words = new string [ ]
{
"королевский" ,
"королевские" ,
"корабли" ,
"пересказывают" ,
"королевского"
} ;
var results = morph . Parse ( words ) . ToArray ( ) ;
var mainWord = results [ 0 ] ;
foreach ( var morphInfo in results )
{
if ( mainWord . CanBeSameLexeme ( morphInfo ) )
Console . WriteLine ( morphInfo . Text ) ;
}Wenn Sie nur eine Lemmatisierung ohne morphologische Analyse benötigen, müssen Sie die Lemmatize-Methode verwenden:
var tasks = new [ ]
{
new LemTask ( "синяя" , morph . TagHelper . CreateTag ( "прил" , gndr : "жен" , nmbr : "ед" , @case : "им" ) ) ,
new LemTask ( "гуляя" , morph . TagHelper . CreateTag ( "деепр" , tens : "наст" ) )
} ;
var lemmas = morph . Lemmatize ( tasks ) . ToArray ( ) ;
foreach ( var lemma in lemmas )
Console . WriteLine ( lemma ) ;DeepMorphy kann die Form eines Wortes innerhalb eines Lexems ändern; die Liste der unterstützten Flexionen finden Sie hier. Wörterbuchwörter können nur innerhalb der Formen geändert werden, die im Wörterbuch verfügbar sind. Um die Form von Wörtern zu ändern, wird die Inflect-Methode verwendet. Sie verwendet als Eingabe eine Aufzählung von InflectTask-Objekten (enthält das Quellwort, das Tag des Quellworts und das Tag, in das das Wort eingefügt werden soll). Die Ausgabe ist eine Aufzählung mit den erforderlichen Formularen (wenn das Formular nicht verarbeitet werden konnte, dann null).
var tasks = new [ ]
{
new InflectTask ( "синяя" ,
morph . TagHelper . CreateTag ( "прил" , gndr : "жен" , nmbr : "ед" , @case : "им" ) ,
morph . TagHelper . CreateTag ( "прил" , gndr : "муж" , nmbr : "ед" , @case : "им" ) ) ,
new InflectTask ( "гулять" ,
morph . TagHelper . CreateTag ( "инф_гл" ) ,
morph . TagHelper . CreateTag ( "деепр" , tens : "наст" ) )
} ;
var results = morph . Inflect ( tasks ) ;
foreach ( var result in results )
Console . WriteLine ( result ) ;Es ist auch möglich, alle seine Formen für ein Wort mithilfe der Lexeme-Methode abzurufen (für Wörterbuchwörter gibt es alles aus dem Wörterbuch zurück, für andere alle Formen aus unterstützten Flexionen).
var word = "лемматизировать" ;
var tag = m . TagHelper . CreateTag ( "инф_гл" ) ;
var results = m . Lexeme ( word , tag ) . ToArray ( ) ;Eines der Merkmale des Algorithmus besteht darin, dass das Netzwerk beim Ändern der Form oder beim Generieren eines Lexems eine nicht existierende (hypothetische) Form des Wortes „erfinden“ kann, eine Form, die in der Sprache nicht verwendet wird. Unten finden Sie beispielsweise das Wort „I’ll run“, obwohl es in der Sprache derzeit nicht besonders häufig verwendet wird.
var tasks = new [ ]
{
new InflectTask ( "победить" ,
m . TagHelper . CreateTag ( "инф_гл" ) ,
m . TagHelper . CreateTag ( "гл" , nmbr : "ед" , tens : "буд" , pers : "1л" , mood : "изъяв" ) )
} ;
Console . WriteLine ( m . Inflect ( tasks ) . First ( ) ) ; 


