inverted_index
1.0.0
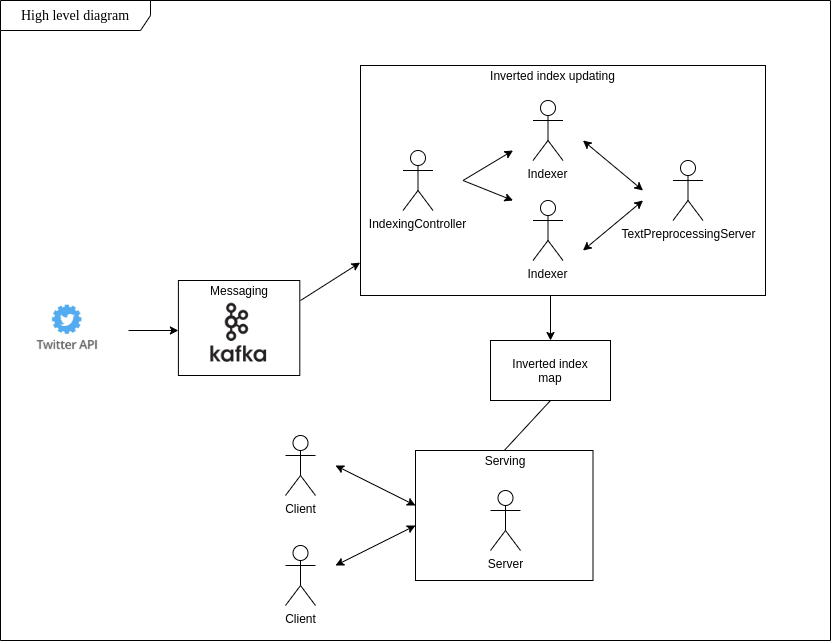
Es könnte schwierig sein, nach Phrasen zu suchen, die die Leute in der Umgebung sagen. Was ist mit dynamischen Aktualisierungen dieses Datensatzes? Skalierbarer Speicher und geringe Latenz? Mein Hauptziel bei diesem Projekt ist der Aufbau eines Systems, das diese Anforderungen erfüllt und es ermöglicht, in Echtzeit über Trends in Tweets auf dem Laufenden zu bleiben.
Der Idee des invertierten Index folgend, habe ich die App implementiert, die Tweets mit bestimmten Inhalten in Echtzeit findet, sie in einem lokalen Dateisystem speichert und eine wortbasierte Suche direkt nach der Initialisierung der Clientverbindung ermöglicht.
Um die App auszuführen, benötigen Sie:
git clone https://github.com/cyberpunk317/inverted_index.git TWITTER_APP_KEY = 'YOUR APP KEY'
TWITTER_APP_SECRET = 'YOUR APP SECRET'
TWITTER_KEY = 'YOUR KEY'
TWITTER_SECRET = 'YOUR SECRET' Erstellen Sie Docker-Dateien für Client und Server:
./gradlew clean build createClientDockerfile createMainDockerfile
Dadurch werden app_server.Dockerfile und app_client.Dockerfile im Stammverzeichnis erstellt.
Bewerbung starten:
docker-compose up
Starten Sie eine Client-Sitzung:
docker build -f app_client.Dockerfile -t client:latest . && docker run -it --rm --network=host client:latest bash
Beginnen Sie mit der Eingabe interessanter Wörter. Der Server gibt den Standort von Tweets im Format „dataset_v2//tweet_N.txt“ zurück. Zum Beispiel:
You entered: war
Server response: [dataset_v2/Veeresh Dambal/tweet_30.txt, dataset_v2/pedro schliesser/tweet_1.txt]
Eine Liste der vorgeschlagenen Funktionen (und bekannten Probleme) finden Sie unter „Offene Probleme“.
Verteilt unter der MIT-Lizenz. Weitere Informationen finden Sie unter LICENSE .


