boost search engine
latest

Tipp
Wenn Sie Fragen zum Betrieb und zur Umsetzung dieses Projekts haben oder bessere Optimierungsvorschläge für dieses Projekt haben, können Sie mich direkt kontaktieren oder einen Issue im Repository hinterlassen.
Bei diesem Projekt handelt es sich um eine Suchmaschinenimplementierung, die auf der Boost-Bibliothek basiert und darauf abzielt, ein effizientes und genaues Suchsystem speziell für die Suche in Boost-Dokumenten bereitzustellen. Durch die Ausarbeitung des Suchmaschinenaufbauprozesses, von der Datenvorverarbeitung über die Indexerstellung bis hin zur Suchabfrageverarbeitung und Ergebnispräsentation, zeigt dieses Projekt, wie man ein vollständiges Suchmaschinensystem aufbaut. Der Technologie-Stack umfasst C++, Boost-Bibliothek, HTML, CSS und JavaScript und realisiert die Back-End-Indexkonstruktion und Front-End-Benutzerinteraktion. Die Grundfunktionen des Projekts sind umfassend und es wurden erweiterte Funktionen wie Worthäufigkeitsstatistiken, dynamisch aktualisierte Indizes und Sortierung nach Priorität der Suchergebnisse hinzugefügt, was die Sucheffizienz und -genauigkeit erheblich verbessert. Dadurch eignet sich die Suchmaschine besonders für Entwickler, die bei der Verwendung von Boost-Bibliotheken schnell die technischen Dokumente finden möchten, die sie benötigen, was die Entwicklungseffizienz und die Zugänglichkeit von Dokumenten erheblich verbessert.
Die Suche nach einer großen Anzahl von Dokumenten und den darin enthaltenen Inhalten ist offensichtlich eine sehr zeitaufwändige und arbeitsintensive Angelegenheit. Wenn Sie sie einzeln direkt durchqueren und darauf zugreifen, reagiert der Dienst grundsätzlich lange Zeit nicht. Aus diesem Grund ist eine schnellere und bequemere Möglichkeit erforderlich, große Datenmengen zu planen und zu verwalten, um eine schnelle Suche zu erreichen. Der Aufbau eines Index ist der Kern der Lösung dieses Problems.
Der sogenannte Index dient dazu, dem Dokument ein Etikett hinzuzufügen und anhand des Etiketts schnell zu suchen. Die Verwaltung von Etiketten ist weitaus stressfreier als die Verwaltung von Dokumenten, was der wesentliche Grund für die Erstellung eines Index ist.

Boost-Bibliothek ist ein allgemeiner Begriff für einige C++-Bibliotheken, die Erweiterungen der C++-Sprachstandardbibliothek bereitstellen. Es wird von der Boost-Community entwickelt und gepflegt. Die Boost-Bibliothek kann perfekt mit der C++-Standardbibliothek zusammenarbeiten und erweiterte Funktionen dafür bereitstellen. Die Boost-Website stellt eine große Anzahl an Dokumenten zur Verfügung. Die Implementierung einer Suchmaschine kann uns helfen, die benötigten Dokumente in einer großen Anzahl von Dokumenten genau und schnell zu finden.
Backend: C/C+, C++11, STL, Boost, Jsoncpp, cppjieba, cpp-httplib
Frontend: HTML5, CSS, JS, jQuery, Ajax
Wirkung:
Backend-Effekte:
Da das Projekt keine Crawler-Dienste implementiert, wird hier die Methode des Herunterladens von Daten auf den lokalen Computer übernommen. Die Daten-HTML-Datei oder das Datenverzeichnis kann im folgenden Verzeichnis abgelegt werden.
Spezifische Schritte finden Sie unter: word.md-chapter
boost-search-engine/search-engine/data/input
[!NOTE] Die Umgebung, die ich verwende, ist:
Linux ubuntu-linux-22-04-desktop 5.15.0-113-generic #123-Ubuntu SMP Mon Jun 10 08:16:46 UTC 2024 aarch64 aarch64 aarch64 GNU/Linux
CMake installieren:
Visual Studio installieren:
Boost-Bibliothek installieren:
C:Librariesboost_1_75_0 cd C:Librariesboost_1_75_0
.bootstrap.bat
.b2.exe
BOOST_ROOT auf das Verzeichnis zu setzen, in dem Boost installiert ist.Installieren Sie jsoncpp:
vcpkg install jsoncpp
CMake-Projekt konfigurieren:
BOOST_ROOT ).Homebrew installieren:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"
Installieren Sie CMake und abhängige Bibliotheken:
brew install cmake boost jsoncpp
CMake-Projekt konfigurieren:
mkdir build && cd build
cmake ..
make
Linux (Ubuntu, CentOS)
sudo apt-get update
sudo apt-get install cmake g++ libboost-all-dev libjsoncpp-dev
sudo yum install cmake gcc-c++ boost-devel jsoncpp-devel
CMake-Projekt konfigurieren:
mkdir build && cd build
cmake ..
make
Sie können makefile auch zum direkten Kompilieren verwenden:
make
[!TIPP]
- Stellen Sie sicher, dass die Pfade auf allen Plattformen korrekt eingestellt sind, insbesondere unter Windows, wo Sie die Pfade zu einigen Bibliotheken möglicherweise manuell festlegen müssen.
- Bei verschiedenen Linux-Distributionen können sich die Installationsbefehle und verfügbaren Pakete geringfügig unterscheiden. Passen Sie sie daher entsprechend an.
- Stellen Sie beim Erstellen unter Windows mit Visual Studio sicher, dass Sie die richtige Architektur (x86 oder x64) auswählen, die zur Version der Bibliothek passt.
Offizielle Links:
https://github.com/yanyiwu/cppjieba
Verknüpfen Sie das cppjieba -Verzeichnis mit dem Projektverzeichnis boost-search-engine/search-engine/include .

Geben Sie das cppjieba Verzeichnis ein
Verknüpfen Sie die dict Wörterbuchbibliothekskomponente und die limonp Komponente mit cppjieba .
Analysieren Sie die Daten.
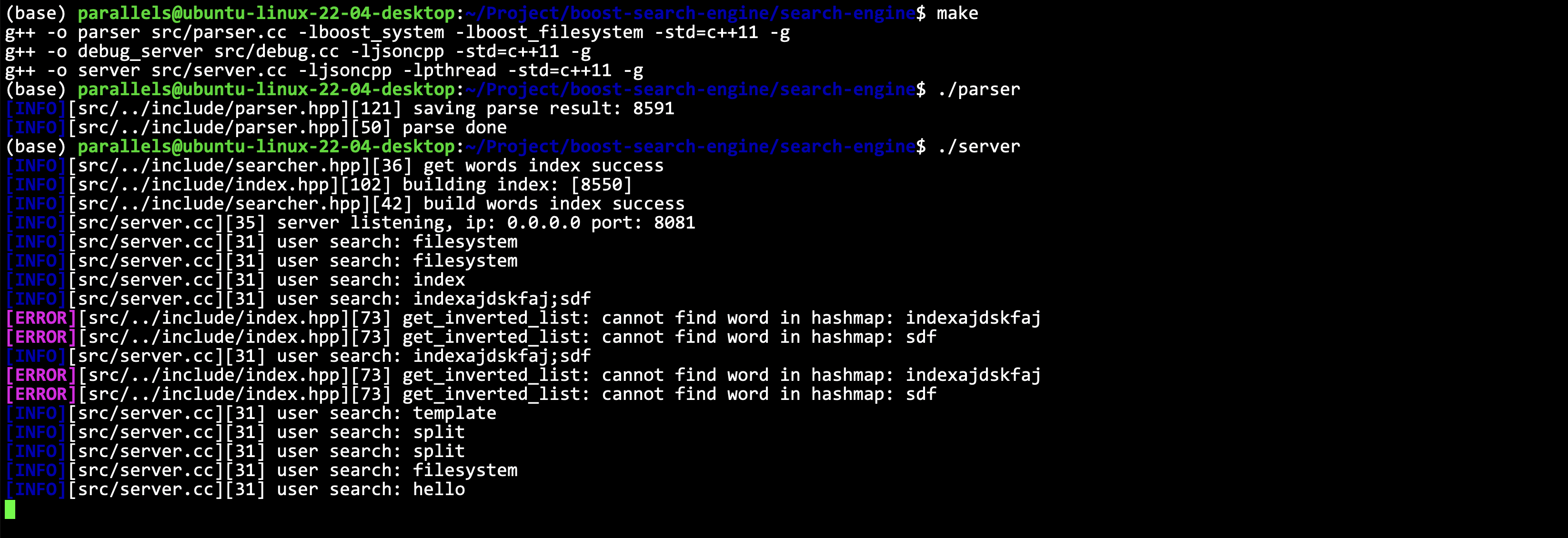
./parser
Wie in der Abbildung gezeigt, ist der Vorgang erfolgreich. Wenn der Vorgang fehlschlägt, können Sie die Fehlermeldung überprüfen. Möglicherweise ist die Pfadkonfiguration falsch. Sie können den Pfad selbst im Code konfigurieren.
Starten Sie den Dienst:

Wie in der Abbildung gezeigt, ist der Start erfolgreich.
Natürlich können auch andere Methoden zur Bereitstellung im Hintergrunddienst verwendet werden, wie zum Beispiel:
nohup ./server > log/log.txt 2>&1 &Sie können auch einige andere Methoden verwenden, z. B. tmux usw.
Verwenden Sie einen Browser, um auf die 8081-Portnummer der IP zuzugreifen. Die Portnummer wird in ./src/server.cc festgelegt.
Der Protokollteil kann weiter verbessert werden.


