mind x
1.0.0

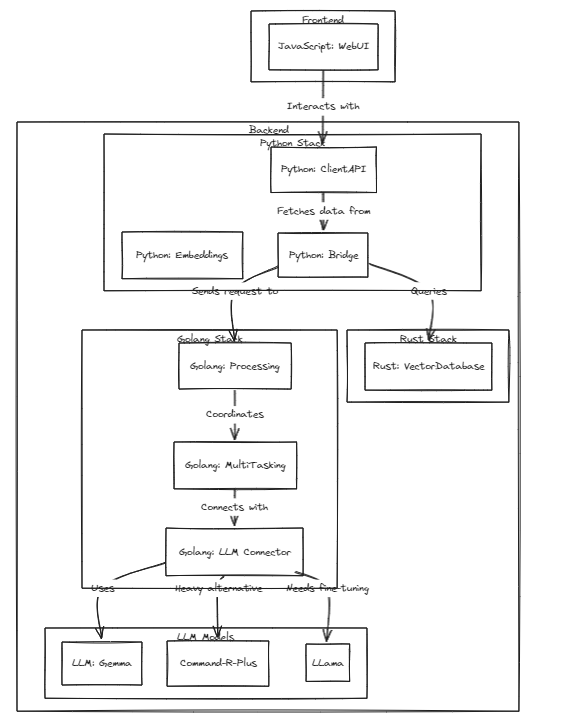
Dieses Projekt demonstriert die Machbarkeit personalisierter LLMs (oder LMMs) als persönliche Assistenten und hält mit dem schnellen Wachstum dieser Modelle Schritt.
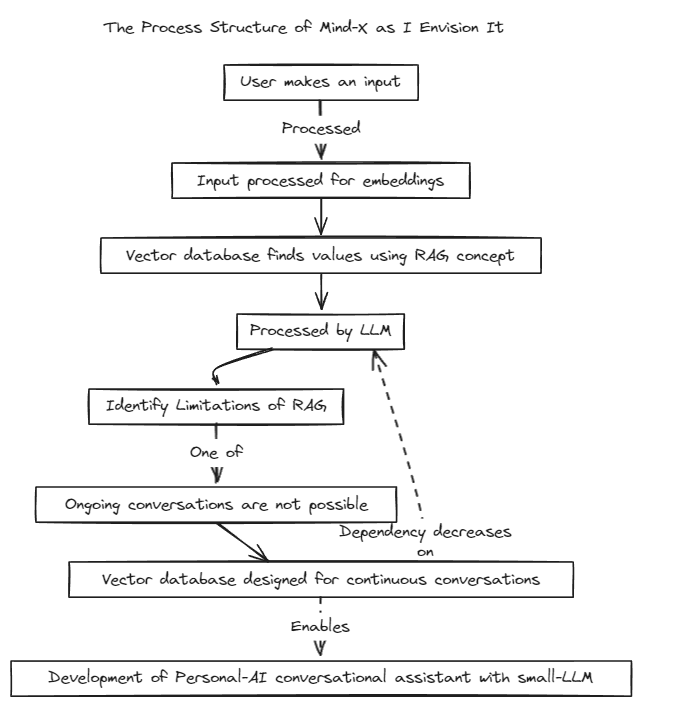
Wir haben eine Retrieval-Augmented Generation (RAG)-Methode eingeführt, um die Einschränkungen des traditionellen Prompt-Tunings zu überwinden, das Kontextgrenzen hat, und des Fine-Tunings, das unter Problemen mit Echtzeit-Datenaktualisierungen und Halluzinationen leidet.
Traditionell wurde RAG zum Durchsuchen von Datenbanken wie Chroma über LangChain als Speicher verwendet, diese Methode funktioniert jedoch in festen Kontexten, was eine Einschränkung darstellt.
Daher planen wir den Aufbau eines eigenen RAG-Systems. Dieser Prozess kann die Behandlung von Inferenz- und Regressionsproblemen beinhalten, die LangChain möglicherweise bietet.
Wir setzen auf eine schnelle Entwicklung und werden bald mehrsprachige Kompatibilität ermöglichen. Derzeit unterstützt das System vollständig Englisch, in Kürze sollen auch Koreanisch, Japanisch und andere Sprachen unterstützt werden. Darüber hinaus werden in Kürze auch Regressions- und Inferenzsysteme integriert.
Führen Sie zum Ausführen von Tests den folgenden Befehl aus
# start embeddings server
cd embd & pip install -r requirements.txt
python app.py
# start mindx-v server (vector-database)
# not using cgo, only assembly
cd mindx-v & go run cmd/mxvd/main.go
# start processor server
cd processor & go run cmd/main.go
# start demo client
cd sample_client & npm start
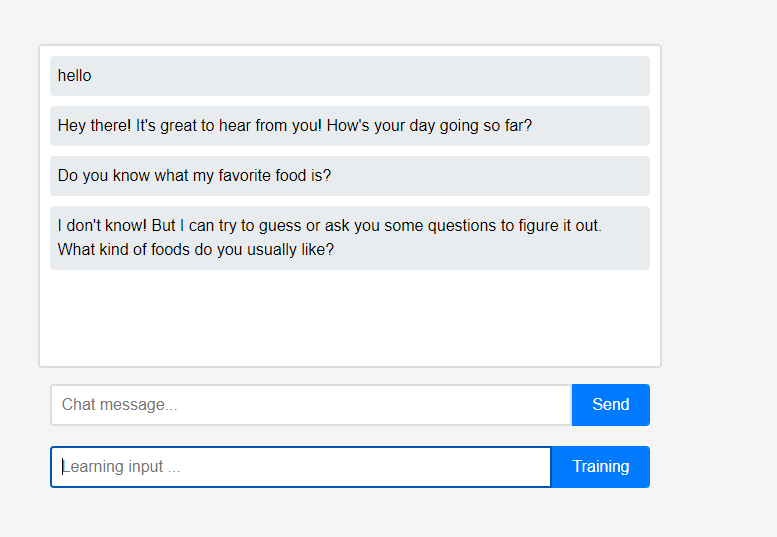 Der Assistent weiß zunächst nichts über den Benutzer.
Der Assistent weiß zunächst nichts über den Benutzer.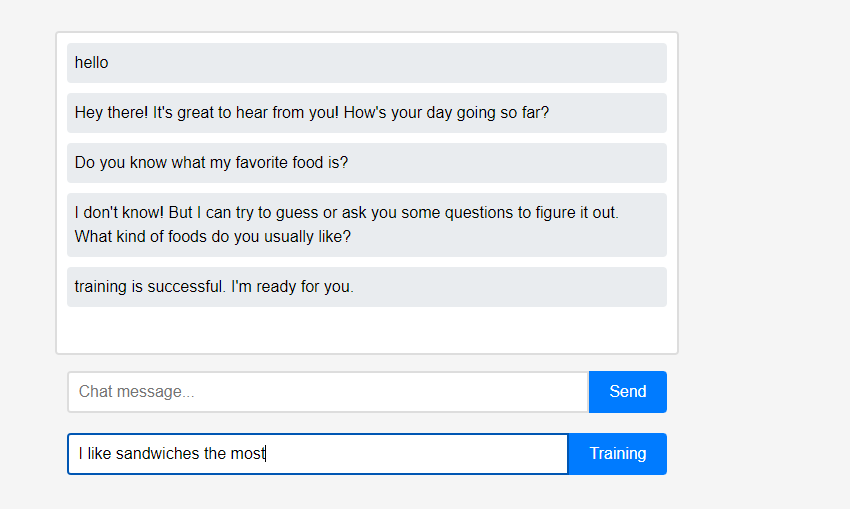 Benutzer können dem Assistenten jedoch in Echtzeit etwas über sich selbst beibringen.
Benutzer können dem Assistenten jedoch in Echtzeit etwas über sich selbst beibringen.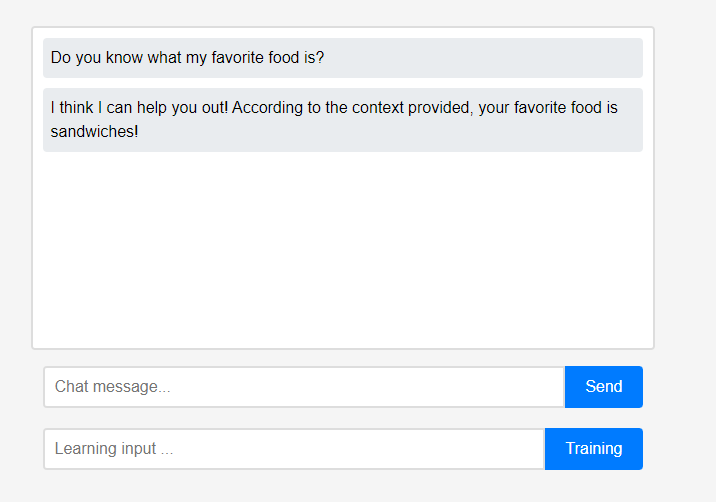 (Aufgrund der Eigenschaften von LLM könnte es missverstanden werden, dass es als Konversationskette und nicht als Lernen gespeichert wurde, sodass dies nach dem Auffrischen erfolgte.) Die gelernten Daten wurden sofort wiedergegeben, und dies kann als erste Personalisierung des Assistenten angesehen werden.
(Aufgrund der Eigenschaften von LLM könnte es missverstanden werden, dass es als Konversationskette und nicht als Lernen gespeichert wurde, sodass dies nach dem Auffrischen erfolgte.) Die gelernten Daten wurden sofort wiedergegeben, und dies kann als erste Personalisierung des Assistenten angesehen werden.
Alle diese Funktionen des Projekts können lokal unterstützt werden, ohne dass eine externe Cloud-Integration oder eine Internetverbindung erforderlich ist.



query = protobuf . search_pb2 . SearchRequest (
dataset_id = dataset_id ,
query = get_image_embedding ( "./test_data/bad.png" ),
k = 1
)
results = search . Search ( query )
try :
for result in results :
print ( "Search result:" , result . id , result . metadata , result . score )
except grpc . RpcError as e :
print ( "Search failed:" , e )
query = protobuf . search_pb2 . SearchRequest (
dataset_id = dataset_id ,
query = get_image_embedding ( "./test_data/good.png" ),
k = 1
)
results = search . Search ( query )
try :
for result in results :
print ( "Search result:" , result . id , result . metadata , result . score )
except grpc . RpcError as e :
print ( "Search failed:" , e )


