dstoolkit km solution accelerator
V1.6

Lösungsbeschleuniger für Knowledge Mining
Dieses Repository enthält den gesamten Code für die Bereitstellung einer End-to-End-Knowledge-Mining-Lösung basierend auf Azure Cognitive Search.
Es basiert auf standardmäßigen Azure-Diensten wie Funktionen, Web-App-Diensten, Congitive Services und Cognitive Search. Es bietet eine Bereitstellungspipeline, die eine schnelle und einfache Einrichtung von CI/CD-Pipelines für Ihre Projekte ermöglicht.
Eine ausführliche Dokumentation finden Sie im Abschnitt „Dokumente“ des Repositorys, das das Lösungs-Wiki enthält.
Um Ihre Lösung erfolgreich einzurichten, müssen Sie Zugriff auf Folgendes haben und/oder Folgendes bereitstellen:
Für das Azure-Abonnement oder die Zielressourcengruppe wird die Rolle „Besitzer“ oder „Mitwirkender“ übernommen.
Informationen zur Bereitstellung dieses Lösungsbeschleunigers finden Sie in der README-Datei.
Bei den Anweisungen in allen Handbüchern wird davon ausgegangen, dass Sie über grundlegende Kenntnisse des Azure-Portals, Azure Functions, Azure Cognitive Search, Functions, Storage und Azure Cognitives Services verfügen.
Weitere Schulungen und Unterstützung finden Sie unter:
Knowledge Mining (KM) ist eine aufstrebende Disziplin der künstlichen Intelligenz (KI), die eine Kombination intelligenter Dienste nutzt, um schnell aus riesigen Informationsmengen zu lernen. Es ermöglicht Unternehmen, Informationen tiefgreifend zu verstehen und einfach zu erforschen, verborgene Erkenntnisse aufzudecken und Zusammenhänge und Muster in großem Maßstab zu finden.
Knowledge Mining in Azure
Ziel dieses KM-Lösungsbeschleunigers ist es, Ihnen eine praktikable End-to-End-Knowledge-Mining-Lösung bereitzustellen, die Folgendes umfasst:
Mit diesem cloudbasierten Beschleuniger erhalten Sie eine End-to-End-Lösung mit den Tools zum Bereitstellen, Erweitern, Betreiben und Überwachen.
In dieser Hinsicht bietet die Lösung
Dieser Knowledge Mining Solution Accelerator ist von einem anderen Accelerator, dem Knowledge Mining Solution Accelerator, inspiriert.
Basierend auf unserer Erfahrung in diesem Bereich haben wir Funktionen/Fähigkeiten entwickelt, um häufige Herausforderungen bei unstrukturierten Daten zu bewältigen, wobei der Schwerpunkt auf der Benutzerfreundlichkeit und der Datenerkundungserfahrung liegt.
Nachfolgend finden Sie eine nicht erschöpfende Liste der wichtigsten Highlights:
Indexierung eingebetteter Bilder
Bildnormalisierung :
Metadaten
HTML-Konvertierung
Tabellenextraktion : Tabellarische Informationen sind in unstrukturierten Datenkorpus üblich. Die Lösung extrahiert, indiziert und projiziert Tabellen in einen dedizierten Wissensspeicher (optional).
Übersetzung „: In dieser Lösung gibt es zwei Übersetzungsfunktionen
Textanalyse : Extrahieren Sie Entitäten (benannt, verknüpft) aus jedem Dokument und OCR-verarbeiteten Bildtext.
Nach Excel exportieren : beliebte Frage beim Untersuchen unstrukturierter Daten.
Konfigurierbare Benutzeroberfläche : Das Erstellen einer Benutzeroberfläche ist zeitaufwändig. Wir wollten eine hervorragende Konfigurierbarkeit der Benutzeroberfläche bieten, damit Sie neue KM-Lösungen zeitnah zum Leben erwecken können.
Dieser Lösungsbeschleuniger-Geist entspricht einem Content Research KM-Szenario.
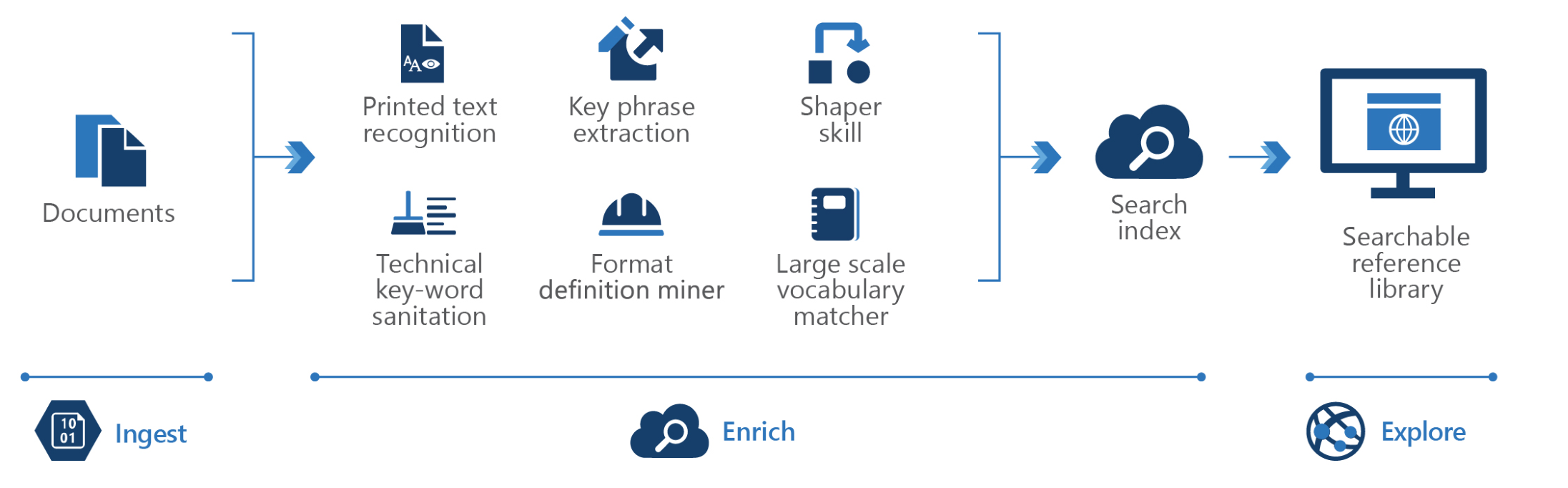
Da die Architektur jedoch offen ist, können Sie sie als Grundlage für speziellere KM-Szenarien verwenden.
Dieser Lösungsbeschleuniger ist nicht auf eine bestimmte Domäne ausgerichtet, bietet Ihnen jedoch durch seine Erweiterbarkeit die Tools, mit denen Sie ihn domänenspezifisch gestalten können.
Einige inspirierende Anwendungsfälle
Möglicherweise denken Sie darüber nach, einen solchen Beschleuniger für Ihr Unternehmen zu produzieren.
Dieser Lösungsbeschleuniger richtet sich an alle, die ihn benötigen
Der Zweck dieses Lösungsbeschleunigers besteht auch darin, die Integration von Data Science-Modulen in Ihre Knowledge-Mining-Lösung zu erleichtern.
Das Data Science Toolkit-Team hat Beschleuniger für Ihre Data Science-Arbeitslast entwickelt.
| Lösung | Beschreibung |
|---|---|
| Vielseitigkeit | Verseagility ist ein Python-basiertes Toolkit zur Beschleunigung Ihrer benutzerdefinierten NLP-Aufgabe (Natural Language Processing), mit dem Sie Ihre eigenen Daten einbringen, Ihre bevorzugten Frameworks verwenden und Modelle in die Produktion bringen können. Es ist eine zentrale Komponente des Microsoft Data Science Toolkits. |
| MLOps-Basis | Dieses Repository enthält die grundlegende Repository-Struktur für maschinelle Lernprojekte basierend auf Azure-Technologien (Azure ML und Azure DevOps). Die Ordnernamen und Dateien werden aufgrund persönlicher Erfahrungen ausgewählt. Hier finden Sie die Prinzipien und Ideen hinter der Struktur, die wir bei der Anpassung Ihres eigenen Projekts und MLOps-Prozesses empfehlen. Außerdem erwarten wir von den Benutzern, dass sie mit den Azure-Konzepten für maschinelles Lernen und der Verwendung der Technologie vertraut sind. |
| MLOps für DataBricks | Dieses Repository enthält das Databricks-Entwicklungsframework für die Bereitstellung beliebiger Data-Engineering-Projekte und maschineller Lernprojekte auf Basis der Azure-Technologien. |
| Klassifizierungslösungsbeschleuniger | Dieses Repository enthält die grundlegende Repository-Struktur für die Bereitstellung von Klassifizierungslösungen für maschinelle Lernprojekte (ML), die auf Azure-Technologien (Azure ML und Azure DevOps) basieren. |
| Beschleuniger der Objekterkennungslösung | Dieses Repository enthält den gesamten Code zum Trainieren von TensorFlow-Objekterkennungsmodellen innerhalb von Azure Machine Learning (AML) mit Setups für das Training zu Azure Compute, Experimentüberwachung und Endpunktbereitstellung als Webservice. Es basiert auf dem MLOps Accelerator und bietet durchgängige Schulungs- und Bereitstellungspipelines, die eine schnelle und einfache Einrichtung von CI/CD-Pipelines für Ihre Projekte ermöglichen. |
Sie können die Solution Accelerator-Dokumentation wie folgt aufrufen:
| Thema | Beschreibung | Dokumentationslink |
|---|---|---|
| Voraussetzungen | Was benötigen Sie, um die Lösung bereitzustellen und zu betreiben? | README |
| Architektur | Wie die Lösung aufgebaut ist | README |
| Einsatz | So stellen Sie diesen Solution Accelerator bereit | README |
| Konfiguration | Alles, was Sie über die Solution Accelerator-Konfiguration wissen müssen | README |
| Datenwissenschaft | Integration mit Data Science | README |
| Einsatz | So beginnen Sie mit der Bereitstellung der Lösung | README |
| Überwachung | So überwachen Sie die Lösung | README |
| Suchen | Wie die Suche konfiguriert und verwaltet wird | README |
| Suchen und Entdecken (UI) | Benutzeroberfläche zum Suchen und Entdecken | README |
Die Repository-Struktur dieses Beschleunigers ist wie folgt
Klonen Sie dieses Repository oder laden Sie es herunter und navigieren Sie dann zum Ordner „Bereitstellung“, indem Sie die im Bereitstellungshandbuch beschriebenen Schritte befolgen.
Wenn Sie alle Schritte abgeschlossen haben, verfügen Sie über eine funktionierende End-to-End-Knowledge-Mining-Lösung, die die Erfassung von Datenquellen mit Fähigkeiten zur Datenanreicherung und einer Web-App kombiniert, die auf Azure Cognitive Search basiert.
Diese Lösung ist von der Originalarbeit des inspiriert
Hauptverantwortliche für diesen Lösungsbeschleuniger sind:
Das Sponsoring-Team des Data Science Toolkits
Für das tolle Gespräch über Knowledge Mining und unstrukturierte Daten
Dieses Projekt freut sich über Beiträge und Vorschläge. Für die meisten Beiträge müssen Sie einem Contributor License Agreement (CLA) zustimmen, in dem Sie erklären, dass Sie das Recht haben, uns die Rechte zur Nutzung Ihres Beitrags zu gewähren, und dies auch tatsächlich tun. Weitere Informationen finden Sie unter https://cla.opensource.microsoft.com.
Wenn Sie eine Pull-Anfrage einreichen, ermittelt ein CLA-Bot automatisch, ob Sie eine CLA bereitstellen müssen, und schmückt die PR entsprechend (z. B. Statusprüfung, Kommentar). Folgen Sie einfach den Anweisungen des Bots. Sie müssen dies nur einmal für alle Repos tun, die unsere CLA verwenden.
Dieses Projekt hat den Microsoft Open Source Verhaltenskodex übernommen. Weitere Informationen finden Sie in den FAQ zum Verhaltenskodex oder wenden Sie sich bei weiteren Fragen oder Kommentaren an [email protected].
Dieses Projekt kann Marken oder Logos für Projekte, Produkte oder Dienstleistungen enthalten. Die autorisierte Nutzung von Microsoft-Marken oder -Logos unterliegt den Marken- und Markenrichtlinien von Microsoft und muss diesen entsprechen. Die Verwendung von Microsoft-Marken oder -Logos in geänderten Versionen dieses Projekts darf keine Verwirrung stiften oder eine Sponsorschaft durch Microsoft implizieren. Jegliche Nutzung von Marken oder Logos Dritter unterliegt den Richtlinien dieser Drittanbieter.


