donkeybot
1.0.0
Dieses Repository wird nicht gepflegt und wurde archiviert.
Donkeybot ist ein End-to-End-Frage-Antwort-System. Es nutzt mehrere Datenquellen, eine FAQ-Tabelle und Transfer-Learning-Sprachmodelle wie BERT, um Rucio-Supportfragen zu beantworten.
Das Ziel des Projekts im Rahmen von GSoC 2020 besteht darin, mithilfe der Verarbeitung natürlicher Sprache (NLP) einen intelligenten Bot-Prototyp zu entwickeln, der in der Lage ist, Rucio-Benutzern zufriedenstellende Antworten zu geben und Supportanfragen bis zu einem bestimmten Komplexitätsgrad zu bearbeiten und nur die verbleibenden an den weiterzuleiten Experten.
Donkeybot kann je nach Bedarf erweitert und als Frage-Antwort-System eingesetzt werden. Änderungen im Code sind erforderlich, um Donkeybot für Ihren spezifischen Anwendungsfall und Ihre Daten zu verwenden. Die aktuelle Implementierung gilt für Rucio-spezifische Datenquellen.
Datenspeicher : Ein Datenspeicher, der Rucio-domänenspezifische Daten enthält. Die aktuelle Implementierung des Moduls erfolgt in SQLite, um ein schnelles Prototyping zu ermöglichen. Zu den Datenquellen gehören sichere und anonyme Support-E-Mails von Rucio-Benutzern, Rucio GitHub-Probleme und Rucio-Dokumentation.
Fragenerkennung : Ein Modul zur Fragenerkennung und Extraktion aus einem beliebigen Text. Dies wird verwendet, um frühere Fragen aus den Support-E-Mails und GitHub-Problemen mithilfe regulärer Ausdrücke zu extrahieren. Diese Fragen werden als Dokumente archiviert und von den anderen Modulen verwendet.
Dokumentenabruf : Ein Suchmaschinenmodul, das den BM25-Algorithmus zum Abruf der Top-n-Dokumente mit der höchsten Ähnlichkeit (zuvor gestellte Fragen oder Rucio-Dokumentation) verwendet, die vom Antworterkennungsmodul als Kontext verwendet werden.
Antworterkennung : Das Antworterkennungsmodul, das sowohl einem Transfer-Learning-Ansatz als auch einem überwachten Ansatz folgt.
Zu den zusätzlichen Funktionen gehören:
GUI zur Erstellung von FAQs : Der Benutzer kann eine bereitgestellte GUI als Schnittstelle verwenden, um mit dem Datenspeicher zu interagieren, FAQ-Fragen einzufügen, die Suchmaschine neu zu indizieren und die Wissensdatenbank von Donkeybot zu erweitern.
Namens-Hashing : Ein Skript, das den NER-Tagger von Stanford verwendet, um private Benutzerinformationen aus Support-E-Mails zu erkennen und diese zu hashen. Befolgen Sie daher die Datenschutzrichtlinien des CERN und halten Sie alle Daten anonym.
Beispiele, Betriebsdetails und andere Informationen finden Sie in der vollständigen Dokumentation.
Unter FAQ: GSoC finden Sie einen detaillierten Zeitplan, Studenteninformationen, aufgetretene Probleme, zukünftige Verbesserungsvorschläge, eine Leseliste und mehr.
Sie können versuchen, Donkeybot selbst zu fragen!
Verwendung des Slackbots:
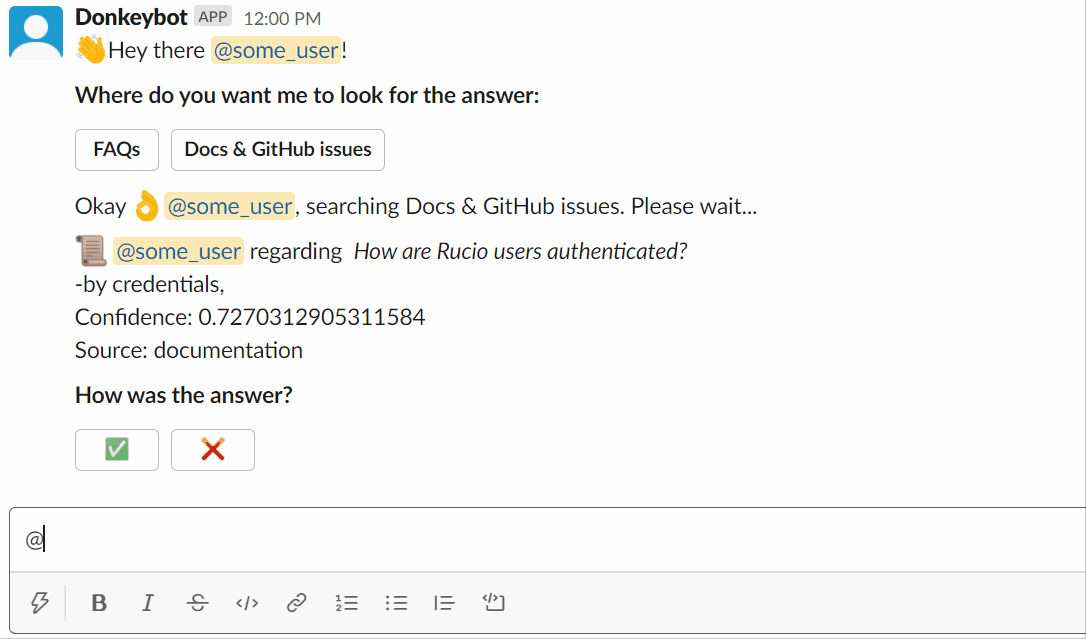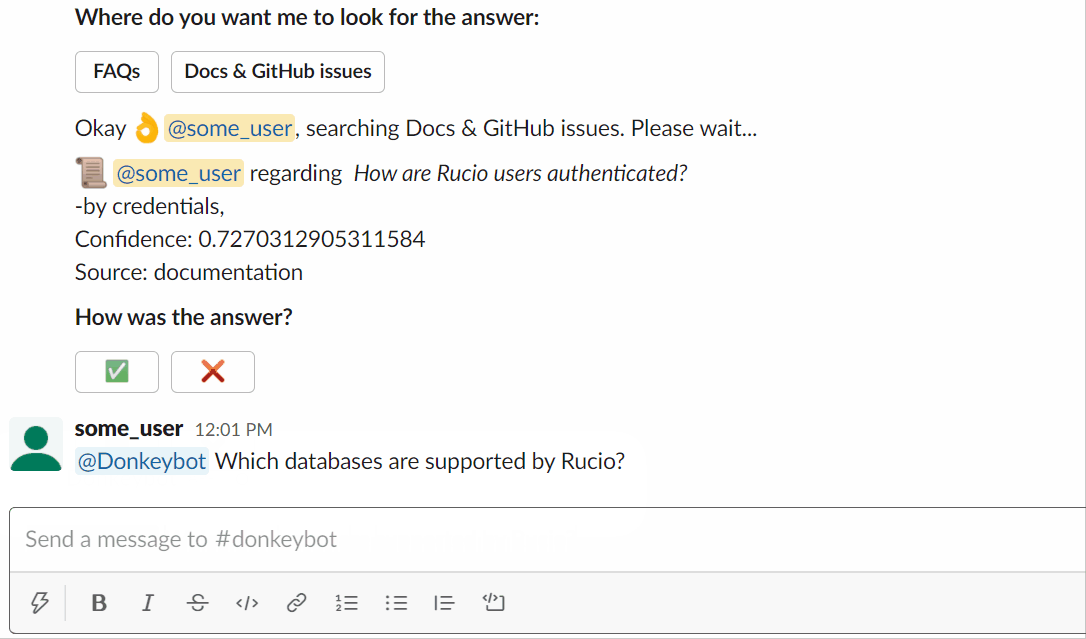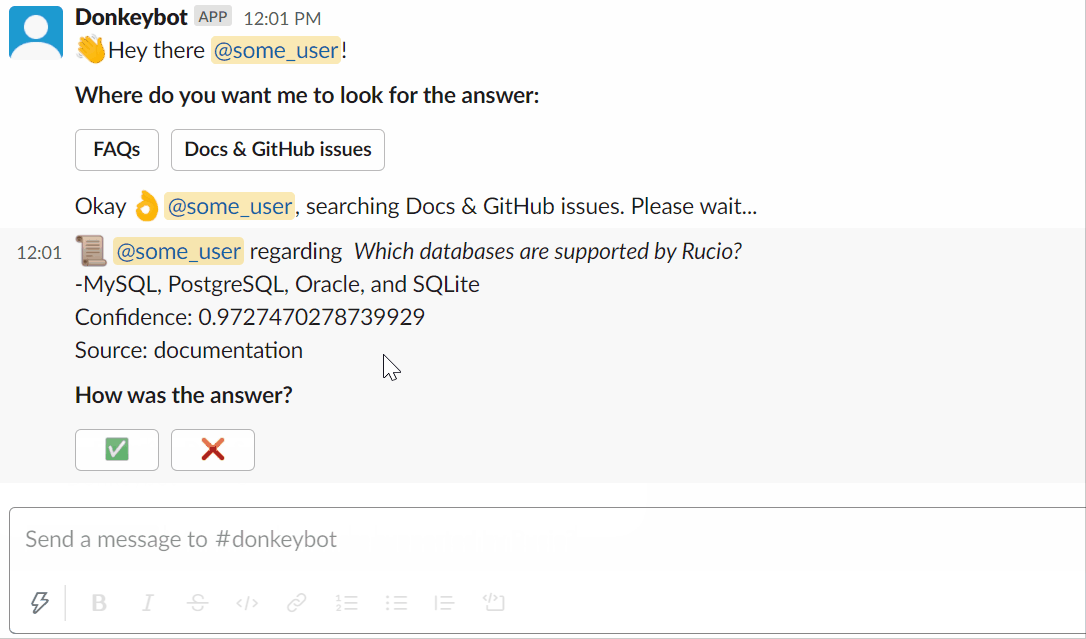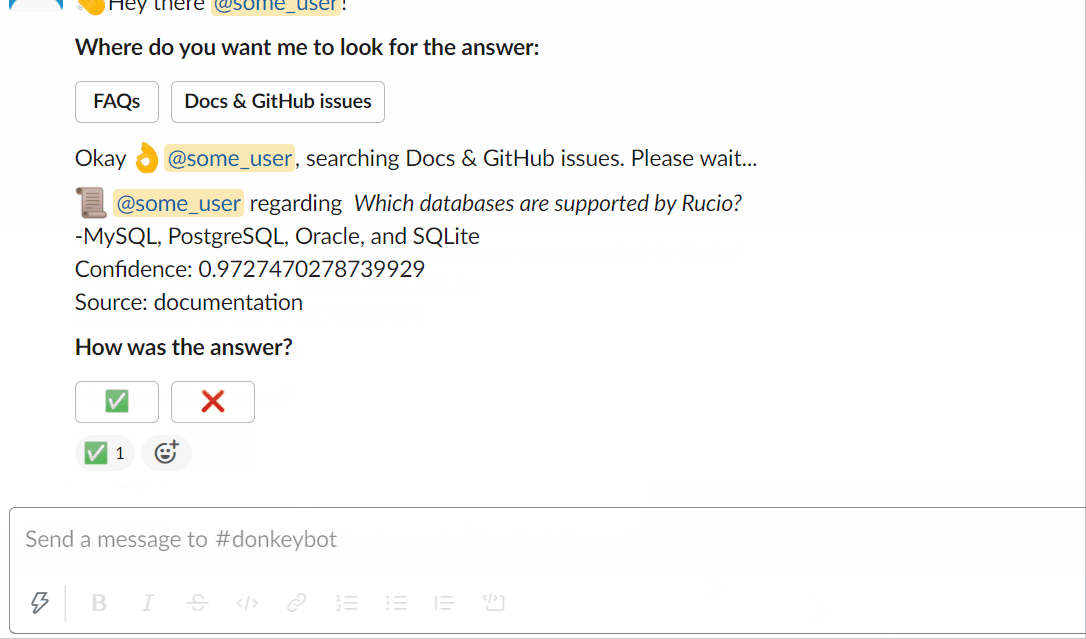
Oder Sie können die CLI verwenden:
$ python . s cripts a sk_donkeybot.py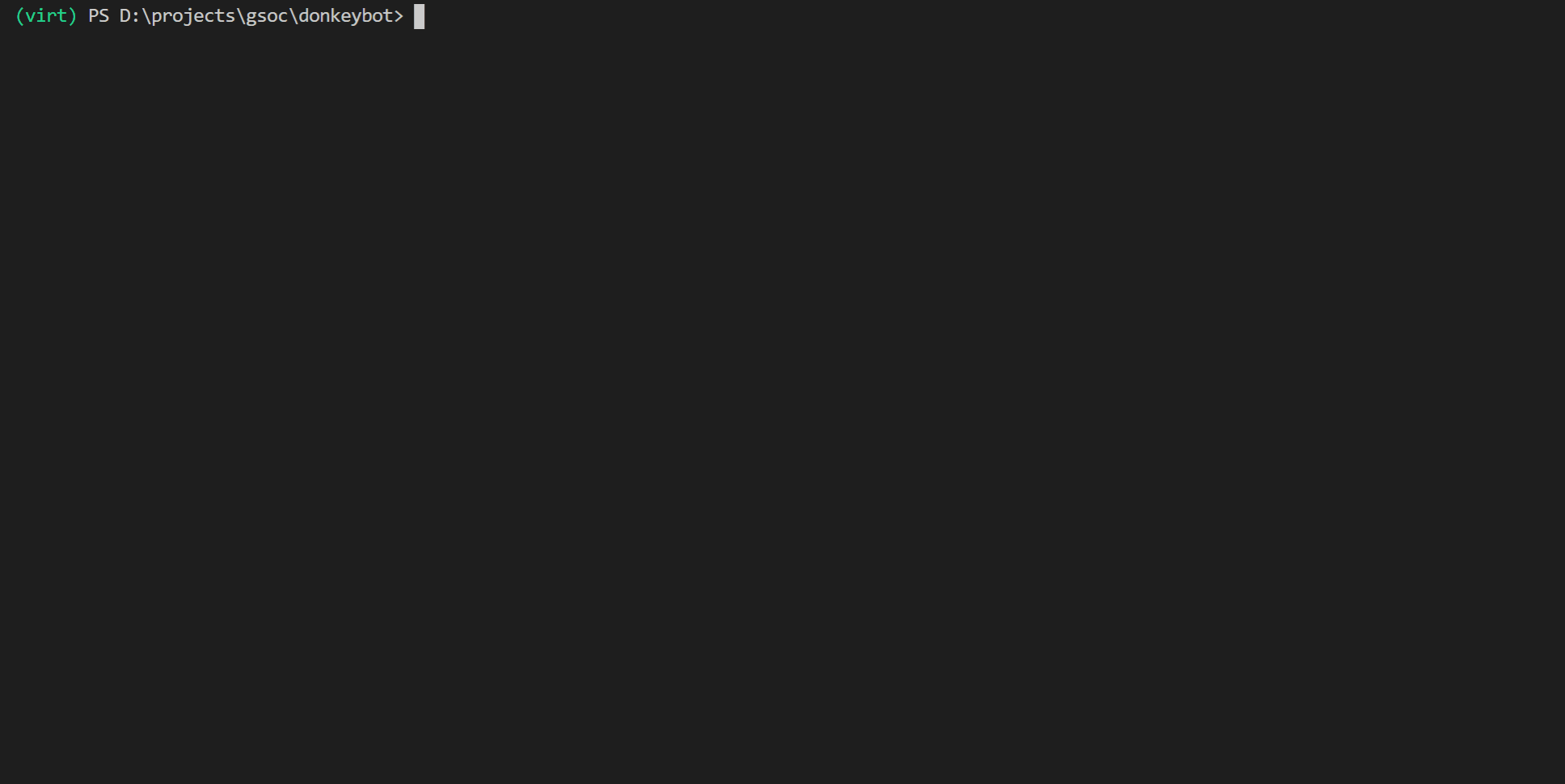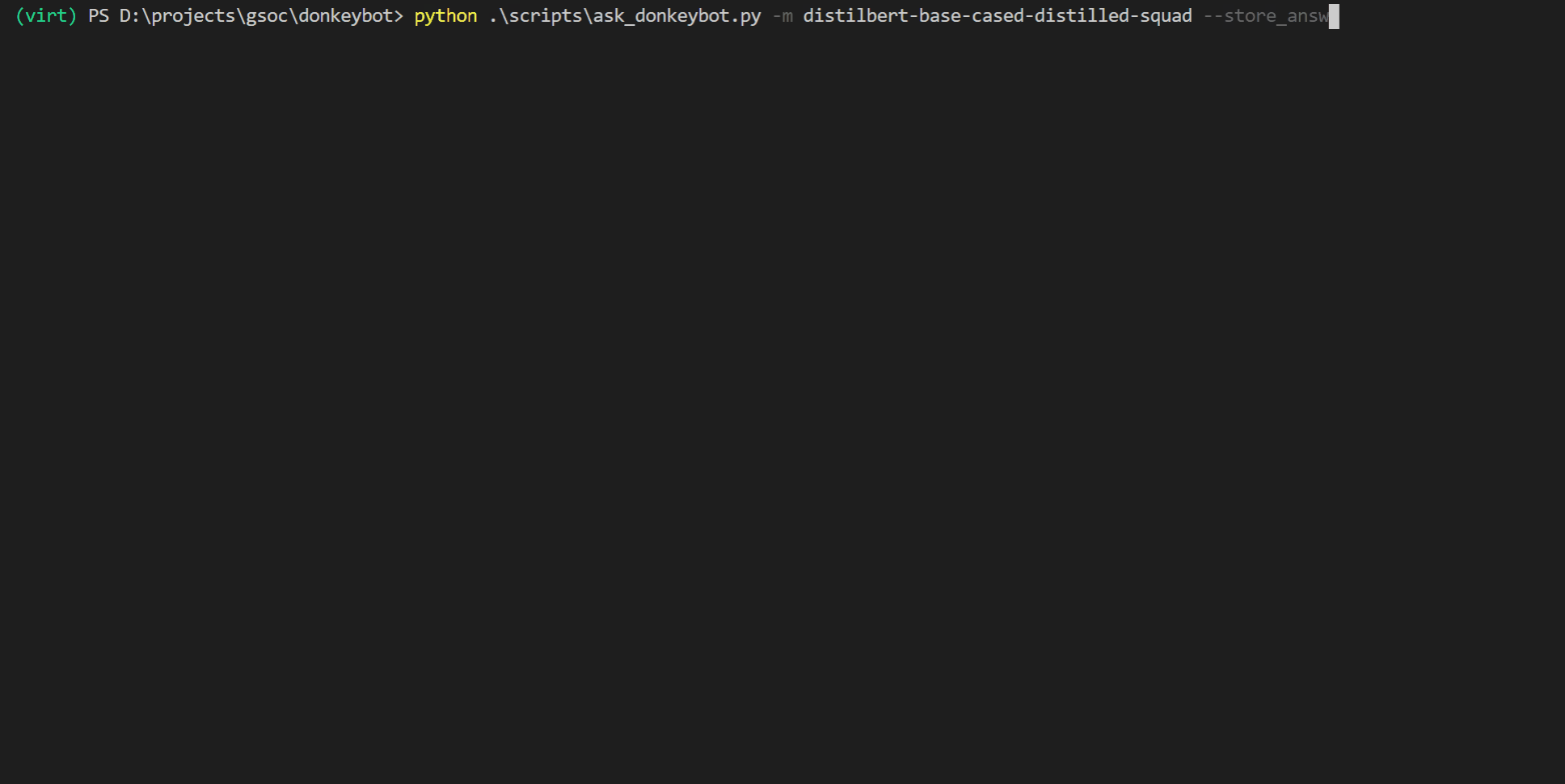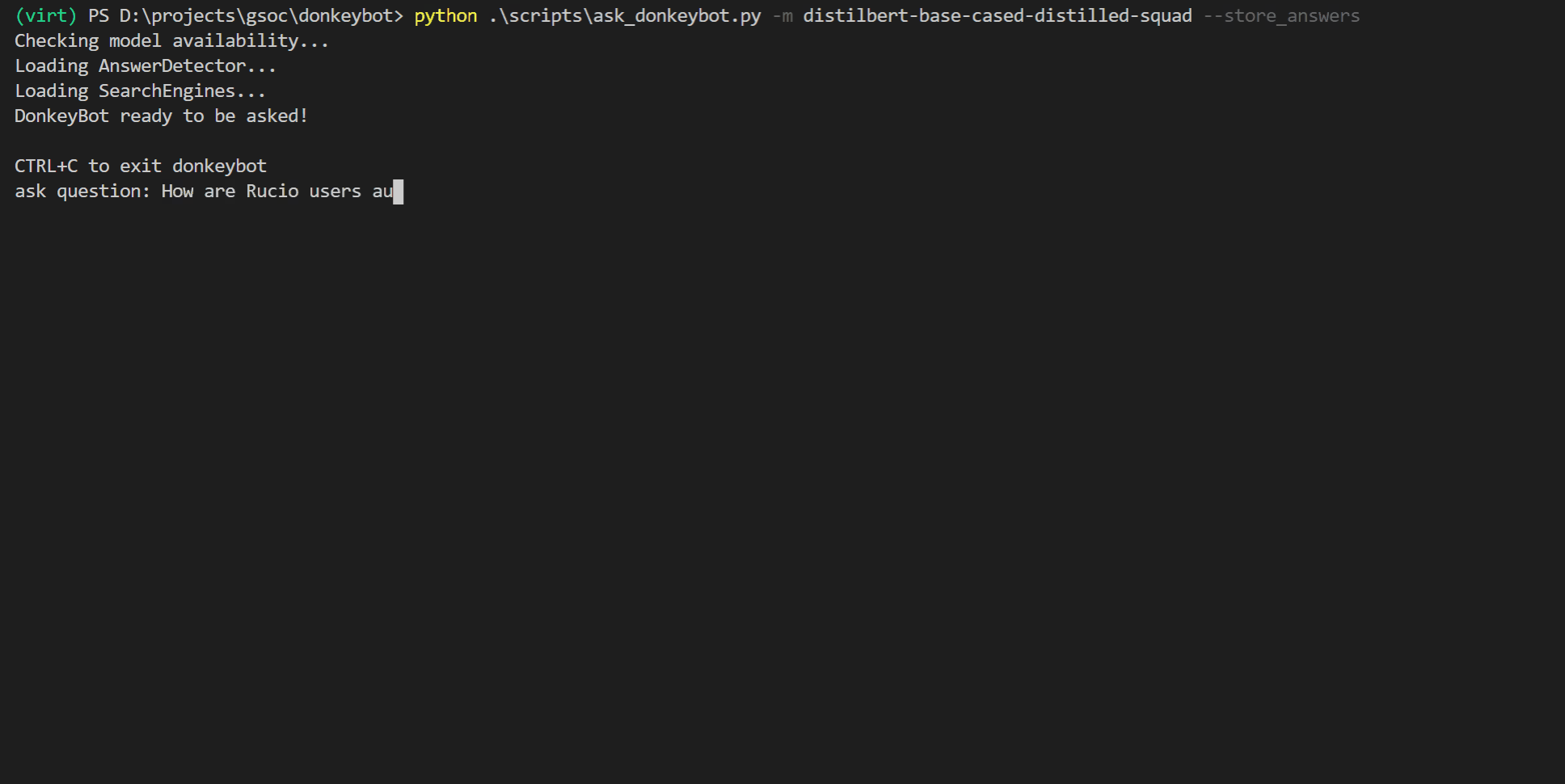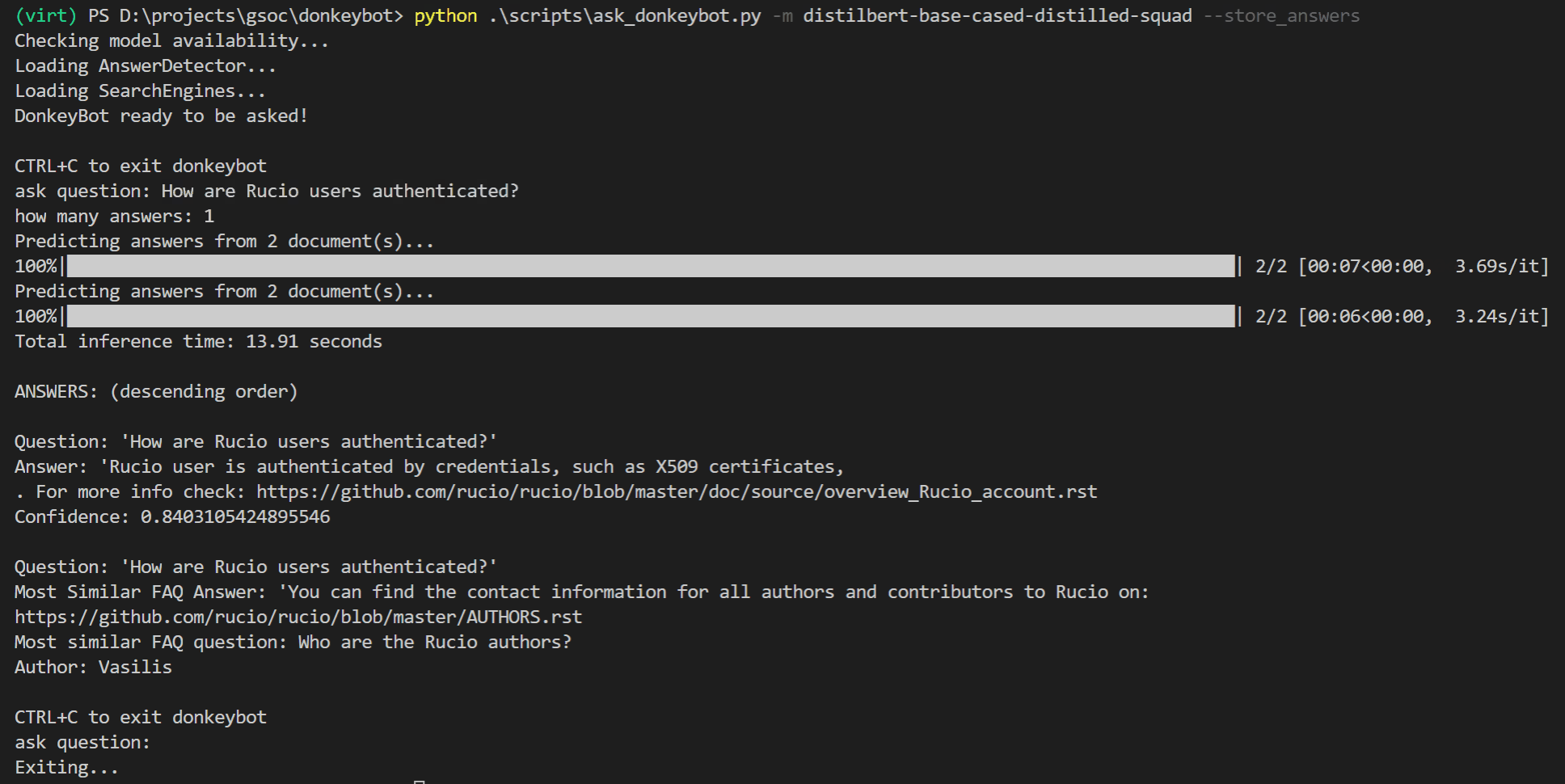
Weitere Beispiele und Informationen finden Sie im Abschnitt „Anwendung“.
Schritt 1: Für PyTorch ist eine 64-Bit-Python 3.x-Installation erforderlich.
Schritt 2: Um PyTorch zu installieren, gehen Sie zu https://pytorch.org/ und folgen Sie der Schnellstartanleitung für Ihr Betriebssystem.
# versions used in development
torch == 1.6 . 0 - - find - links https : // download . pytorch . org / whl / torch_stable . html
torchvision == 0.7 . 0 - - find - links https : // download . pytorch . org / whl / torch_stable . htmlSchritt 3: Klonen Sie das Repository auf Ihren Entwicklungscomputer.
$ git clone https://github.com/rucio/donkeybot.git
$ cd donkeybotSchritt 4: Für zusätzliche Anforderungen ausführen.
$ pip install -r requirements.txtSchritt 5: Erstellen und füllen Sie den Datenspeicher von Donkeybot.
$ python scripts/build_donkeybot -t < GITHUB_API_TOKEN >Weitere Informationen zum Mitwirken, Initiieren des Entwicklermodus und Testen finden Sie auf der Seite „Erste Schritte“.
Für Fehler, Fragen und Diskussionen nutzen Sie bitte die GitHub Issues oder kontaktieren Sie den Studenten @mageirakos.
Lizenziert unter der Apache-Lizenz, Version 2.0;
http://www.apache.org/licenses/LICENSE-2.0


