Meme-Retrieval-Engine
Projektbeschreibung
Eingesetzte Technologien
- Bildverarbeitung
- Maschinelles Lernen
- Verarbeitung natürlicher Sprache
- Shell-Scripting
Sammlung
Die Memes werden mithilfe eines Scraper-Skripts scrape/scraper.py aus beliebten Subreddits gesammelt
Standardisierung
- Die gesammelten Memes werden im
raw -Ordner abgelegt und das Skript standard.py wird ausgeführt - Jeder Dateiname wird extrahiert und in einer Textdatei neben dem neuen hexadezimalen Dateinamen gespeichert, der für das Bild generiert wird
- Die standardisierten Bilder werden im
processed Ordner abgelegt
Abfrageextraktion
- Die eingegebene Abfrage wird in Wörter aufgeteilt und Synonyme für jedes Wort werden mithilfe der NLTK-Bibliothek zur Liste
related queries hinzugefügt - Wir durchsuchen die Datenbank, um Wörter mit den Wörtern in
related queries abzugleichen - Dies erweitert den Suchbereich und minimiert Null-Ausgabe-Szenarien
Relevanz für die Abfrage
- Die Memes sind in der Reihenfolge ihrer Relevanz für die Suchanfrage sortiert
- Dies geschieht, indem jedem in der Datenbank vorhandenen Meme eine Bewertung zugewiesen und dann in absteigender Reihenfolge der Bewertungen sortiert wird
Optische Zeichenerkennung
- OCR wird mit Tesseract durchgeführt, um Text aus den Memes zu extrahieren, was ein wesentlicher Bestandteil des Projekts ist
- Der extrahierte Text ist nicht ganz genau, daher wird die Ausgabe von ocr in die Rechtschreibprüfung der Python-
autocorrect eingespeist - Die Rechtschreibprüfung macht die Konvertierung genauer
Schnelltest
Um die GUI auszuführen und die Funktionen zu testen, geben Sie einfach Folgendes ein
Sammeln und ausführen
- Um die Memes von Subreddits zu sammeln
- Das Bash-Skript bereitet die Datenbank vor, damit die Meme Engine ordnungsgemäß funktioniert
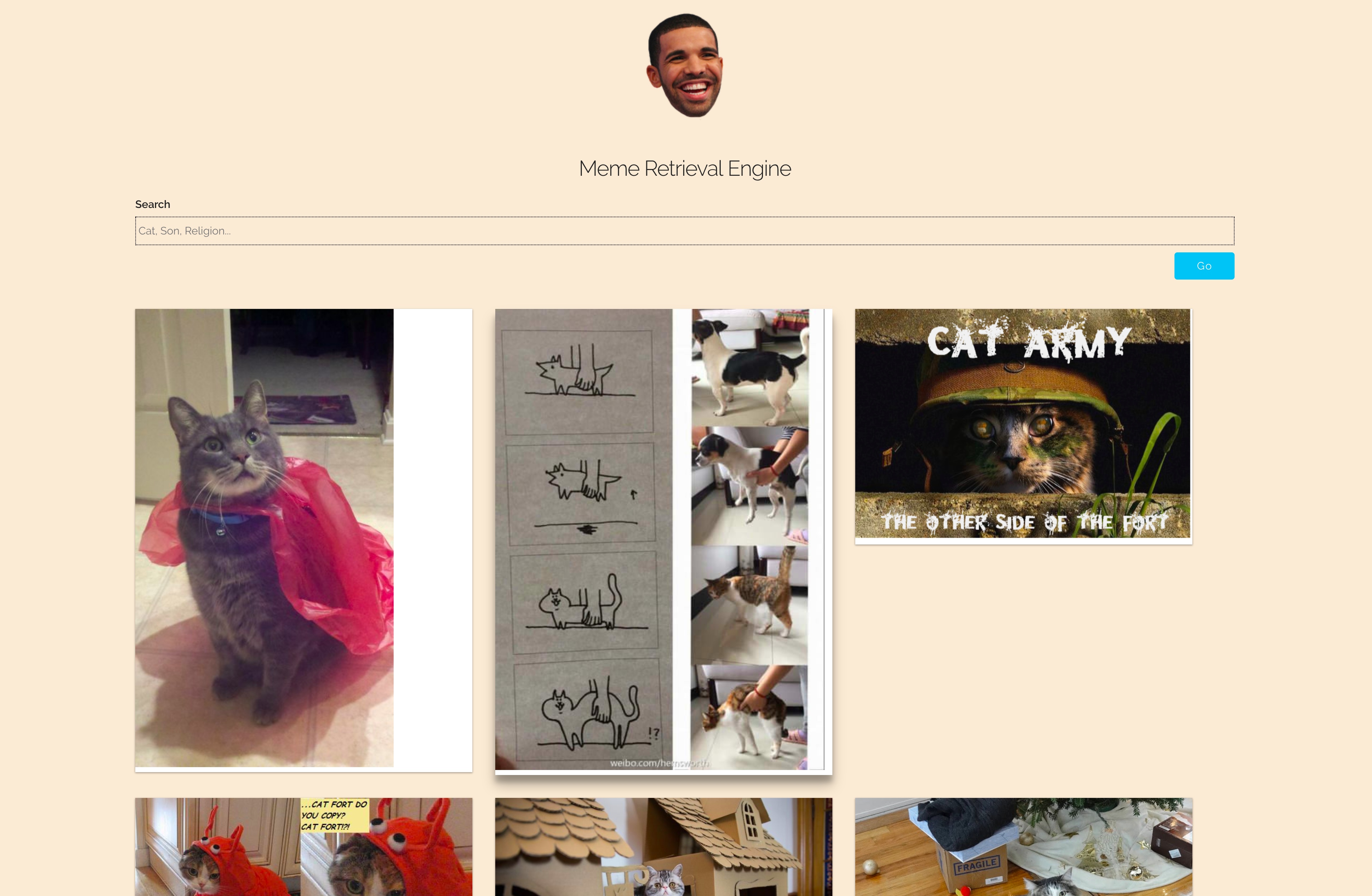
- Um die Meme Retrieval Engine (Meme Finder) auszuführen, geben Sie Folgendes ein:
- Geben Sie die Abfrage in das Textfeld ein und klicken Sie auf
Go - Die Memes sind nach Relevanz sortiert
- Die ausgewählten Memes können mit den Schaltflächen
Next und Previous durchsucht werden
Fügen Sie der Liste neue Subreddits hinzu
Anforderungen
- cv2 (OpenCV)
- Pytesserakt
- nltk
- PIL
- Hashlib
- Shutil
- Autokorrektur
- Pymongo
Zukünftige Verbesserungen
- Hinzufügen von Funktionen zum Fortschrittsbalken
- Korrigieren Sie die Größenskalierung von Memes für die Anzeige auf der Leinwand
- Funktion zum Löschen gespeicherter Memes hinzugefügt
- Speichern beliebter Meme-Vorlagen und Überprüfen von Bildern auf Ähnlichkeit und Verknüpfen spezieller Schlüsselwörter
Dokumentation
MemeFinder-Dokumentation


