idt
1.0.0

Das Image Dataset Tool (IDT) ist eine CLI-App, die entwickelt wurde, um die Erstellung von Bilddatensätzen für Deep Learning einfacher und schneller zu machen. Dies erreicht das Tool durch das Scrapen von Bildern aus mehreren Suchmaschinen wie Duckgo, Bing und Deviantart. IDT optimiert auch den Bilddatensatz. Obwohl diese Funktion optional ist, kann der Benutzer die Bilder verkleinern und komprimieren, um optimale Dateigröße und -abmessungen zu erzielen. Ein mit idt erstellter Beispieldatensatz, der insgesamt 23.688 Bilddateien enthält, wiegt nur 559,2 Megabyte.
Ich bin stolz, unsere neueste Version ankündigen zu dürfen! ??
Was hat sich geändert?
Sie können es über pip installieren oder dieses Repository klonen.
user@admin:~ $ pip3 install idt
ODER
user@admin:~ $ git clone https://github.com/deliton/idt.git && cd idt
user@admin:~/idt $ sudo python3 setup.py install
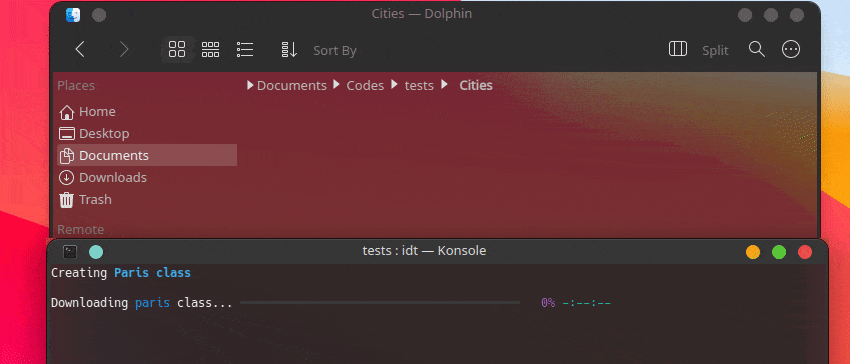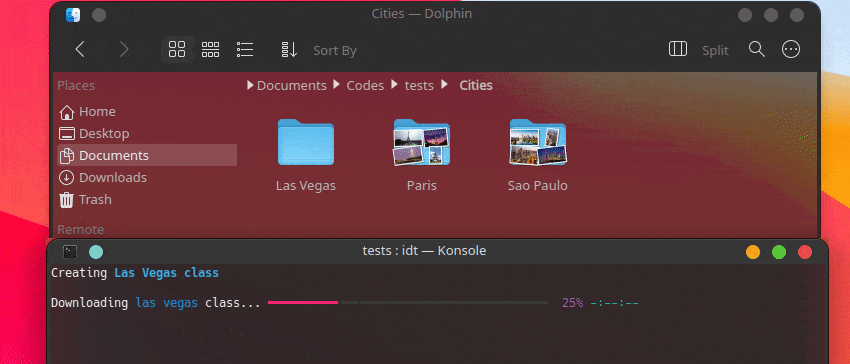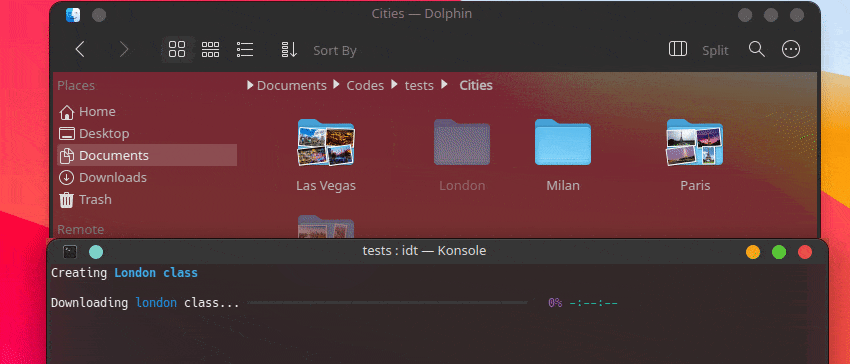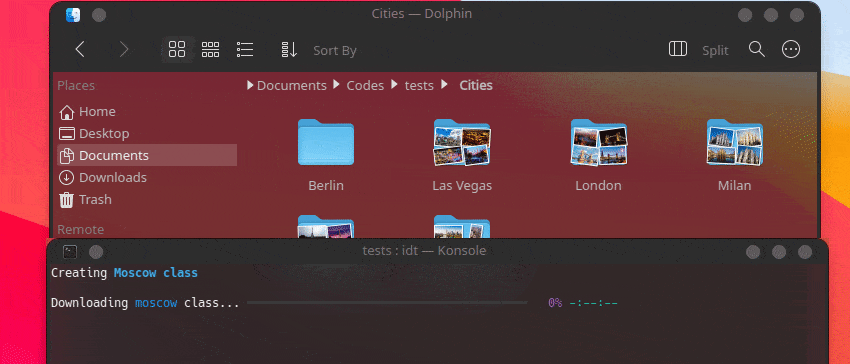
Der schnellste Weg, mit IDT zu beginnen, ist die Ausführung des einfachen Befehls „run“. Schreiben Sie einfach in Ihre Lieblingskonsole etwas wie:
user@admin:~ $ idt run -i apples Dadurch werden schnell 50 Bilder von Äpfeln heruntergeladen. Standardmäßig wird hierfür die Suchmaschine duckgo verwendet. Der Ausführungsbefehl akzeptiert die folgenden Optionen:
| Option | Beschreibung |
|---|---|
| -i oder --input | Geben Sie das Schlüsselwort ein, um die gewünschten Bilder zu finden. |
| -s oder --size | die Anzahl der herunterzuladenden Bilder. |
| -e oder --engine | die gewünschte Suchmaschine (Optionen: duckgo, bing, bing_api und flickr_api) |
| --resize-method | Wählen Sie eine Methode zur Größenänderung von Bildern. (Optionen: long_side, shorter_side und smartcrop) |
| -is oder --image-size | Option zum Einstellen des gewünschten Bildgrößenverhältnisses. Standard = 512 |
| -ak oder --api-key | Wenn Sie eine Suchmaschine verwenden, die einen API-Schlüssel erfordert, ist diese Option erforderlich |
IDT benötigt eine Konfigurationsdatei, die ihm sagt, wie Ihr Datensatz organisiert werden soll. Sie können es mit dem folgenden Befehl erstellen:
user@admin:~ $ idt initDieser Befehl löst den Ersteller der Konfigurationsdatei aus und fragt nach den gewünschten Datensatzparametern. In diesem Beispiel erstellen wir einen Datensatz mit Bildern Ihrer Lieblingsautos. Die ersten Parameter, die dieser Befehl abfragt, sind: Welchen Namen soll Ihr Datensatz haben? In diesem Beispiel nennen wir unseren Datensatz „Meine Lieblingsautos“.
Insert a name for your dataset: : My favorite carsAnschließend fragt das Tool, wie viele Stichproben pro Suche erforderlich sind, um Ihren Datensatz bereitzustellen. Um einen guten Datensatz für Deep Learning zu erstellen, sind viele Bilder erforderlich, und da wir zum Scrapen von Bildern eine Suchmaschine verwenden, sind viele Suchvorgänge mit unterschiedlichen Schlüsselwörtern erforderlich, um einen Datensatz mit guter Größe zusammenzustellen. Dieser Wert entspricht der Anzahl der Bilder, die bei jeder Suche heruntergeladen werden sollen. In diesem Beispiel benötigen wir einen Datensatz mit 250 Bildern in jeder Klasse und verwenden 5 Schlüsselwörter, um jede Klasse bereitzustellen. Wenn wir hier also die Zahl 50 eingeben, lädt IDT 50 Bilder jedes bereitgestellten Schlüsselworts herunter. Wenn wir 5 Schlüsselwörter angeben, sollten wir die erforderlichen 250 Bilder erhalten.
How many samples per search will be necessary? : 50Das Tool fragt nun nach einem Bildgrößenverhältnis. Da die Verwendung großer Bilder zum Trainieren neuronaler Netze nicht sinnvoll ist, können wir optional eines der folgenden Bildgrößenverhältnisse wählen und unsere Bilder auf diese Größe verkleinern. In diesem Beispiel wählen wir 512 x 512, obwohl 256 x 256 für diese Aufgabe eine noch bessere Option wäre.
Choose images resolution:
[1] 512 pixels / 512 pixels (recommended)
[2] 1024 pixels / 1024 pixels
[3] 256 pixels / 256 pixels
[4] 128 pixels / 128 pixels
[5] Keep original image size
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
What is the desired image size ratio: 1Und wählen Sie dann „longer_side“ als Größenänderungsmethode.
[1] Resize image based on longer side
[2] Resize image based on shorter side
[3] Smartcrop
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
Desired Image resize method: : longer_side
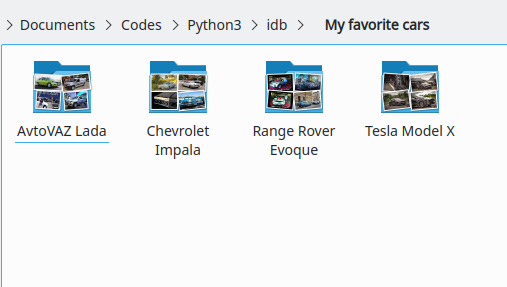
Jetzt müssen Sie auswählen, wie viele Klassen/Ordner Ihr Datensatz haben soll. In diesem Beispiel kann dieser Teil sehr persönlich sein, aber meine Lieblingsautos sind: Chevrolet Impala, Range Rover Evoque, Tesla Model X und (warum nicht) AvtoVAZ Lada. In diesem Fall haben wir also 4 Klassen, eine für jeden Favoriten.
How many image classes are required? : 4Anschließend werden Sie aufgefordert, zwischen einer der verfügbaren Suchmaschinen zu wählen. In diesem Beispiel verwenden wir DuckGO, um für uns nach Bildern zu suchen.
Choose a search engine:
[1] Duck GO (recommended)
[2] Bing
[3] Bing API
[4] Flickr API
Select option:: 1Jetzt müssen wir einige Formulare wiederholt ausfüllen. Wir müssen jede Klasse und alle Schlüsselwörter benennen, die zum Auffinden der Bilder verwendet werden. Beachten Sie, dass dieser Teil später durch Ihren eigenen Code geändert werden kann, um weitere Klassen und Schlüsselwörter zu generieren.
Class 1 name: : Chevrolet ImpalaNachdem wir den ersten Klassennamen eingegeben haben, werden wir aufgefordert, alle Schlüsselwörter anzugeben, um den Datensatz zu finden. Denken Sie daran, dass wir das Programm angewiesen haben, 50 Bilder von jedem Schlüsselwort herunterzuladen. Daher müssen wir in diesem Fall 5 Schlüsselwörter angeben, um alle 250 Bilder zu erhalten. Jedes Schlüsselwort MUSS durch Kommas (,) getrennt werden.
In order to achieve better results, choose several keywords that will
be provided to the search engine to find your class in different settings.
Example:
Class Name: Pineapple
keywords: pineapple, pineapple fruit, ananas, abacaxi, pineapple drawing
Type in all keywords used to find your desired class, separated by commas: Chevrolet Impala 1967 car photos,
chevrolet impala on the road, chevrolet impala vintage car, chevrolet impala convertible 1961, chevrolet impala 1964 lowrider
Wiederholen Sie dann den Vorgang zum Ausfüllen des Klassennamens und seiner Schlüsselwörter, bis Sie alle vier erforderlichen Klassen ausgefüllt haben.
Dataset YAML file has been created successfully. Now run idt build to mount your dataset!Ihre Datensatzkonfigurationsdatei wurde erstellt. Jetzt rosten Sie einfach den folgenden Befehl und sehen Sie, wie die Magie geschieht:
user@admin:~ $ idt buildUnd warten Sie, während der Datensatz gemountet wird:
Creating Chevrolet Impala class
Downloading Chevrolet Impala 1967 car photos [#########################-----------] 72% 00:00:12
Am Ende stehen alle Ihre Bilder in einem Ordner mit dem Datensatznamen zur Verfügung. Außerdem ist im Stammordner des Datensatzes eine CSV-Datei mit den Datensatzstatistiken enthalten.
Da Deep Learning oft erfordert, dass Sie Ihren Datensatz in eine Teilmenge von Trainings-/Validierungsordnern aufteilen, kann dieses Projekt dies auch für Sie erledigen! Führen Sie einfach Folgendes aus:
user@admin:~ $ idt splitJetzt müssen Sie einen Zug/gültigen Anteil auswählen. In diesem Beispiel habe ich ausgewählt, dass 70 % der Bilder für das Training reserviert werden, während der Rest für die Validierung reserviert wird:
Choose the desired proportion of images of each class to be distributed in train/valid folders.
What percentage of images should be distributed towards training?
(0-100): 70
70 percent of the images will be moved to a train folder, while 30 percent of the remaining images
will be stored in a validation folder.
Is that ok? [Y/n]: yUnd das ist es! Der Datensatz-Split sollte nun mit den entsprechenden train/valid-Unterverzeichnissen gefunden werden.
Dieses Projekt wird in meiner Freizeit entwickelt und erfordert noch viel Aufwand, um fehlerfrei zu sein. Pull-Anfragen und Mitwirkende sind sehr willkommen. Fühlen Sie sich frei, auf jede erdenkliche Weise einen Beitrag zu leisten!


