T5Elasticsearch
1.0.0
Nachfolgend finden Sie ein Beispiel für eine Jobsuche:
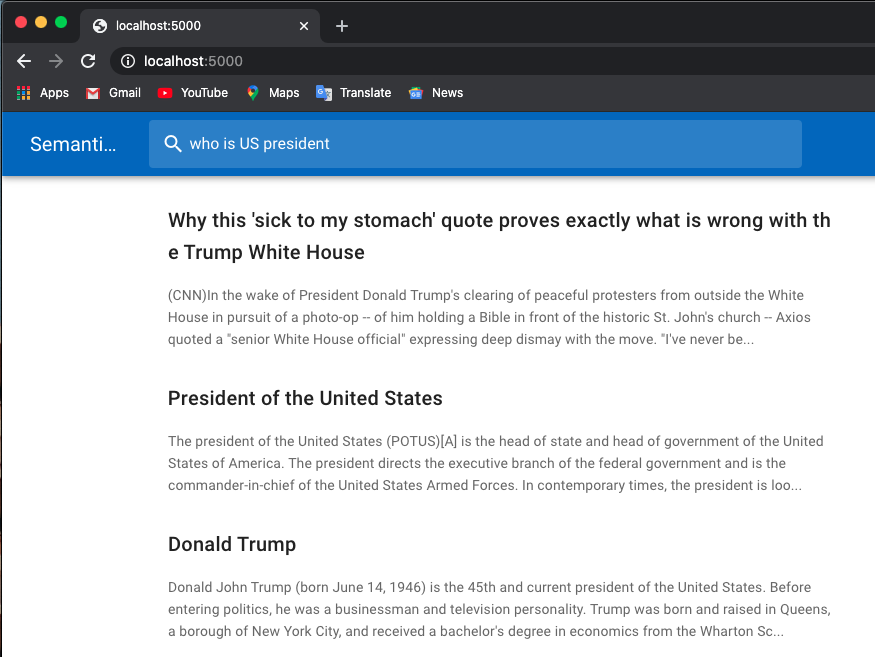
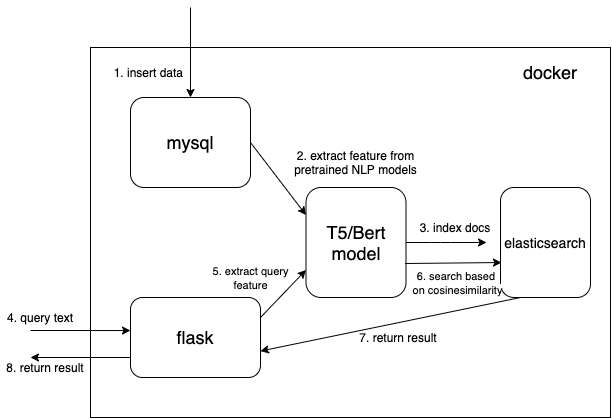
Ich verwende vorab trainierte Modelle von Huggingface-Transformatoren.
Laden Sie den vorab trainierten Tokenizer und das t5/bert-Modell manuell in lokale Verzeichnisse herunter. Sie können die Modelle hier überprüfen.
Ich verwende das Modell „t5-small“. Klicken Sie hier und klicken Sie auf List all files in model um Dateien herunterzuladen. 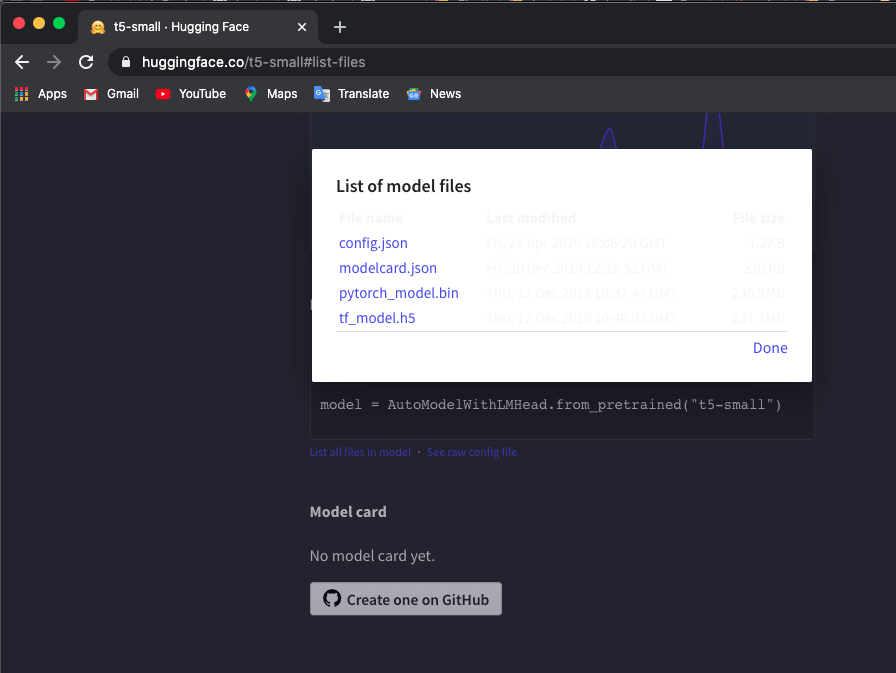
Beachten Sie die Verzeichnisstruktur der manuell heruntergeladenen Dateien.
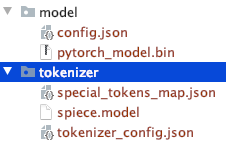
Sie könnten andere T5- oder Bert-Modelle verwenden.
Wenn Sie andere Modelle herunterladen, überprüfen Sie die Liste der vorgefertigten Hugaface Transformers-Modelle, um den Modellnamen zu überprüfen.
$ export TOKEN_DIR=path_to_your_tokenizer_directory/tokenizer
$ export MODEL_DIR=path_to_your_model_directory/model
$ export MODEL_NAME=t5-small # or other model you downloaded
$ export INDEX_NAME=docsearch$ docker-compose up --build Ich verwende auch docker system prune um alle nicht verwendeten Container, Netzwerke und Bilder zu entfernen und so mehr Speicher zu erhalten. Erhöhen Sie Ihren Docker-Speicher (ich verwende 8GB ), wenn Sie auf den Fehler Container exits with non-zero exit code 137 stoßen.
Wir verwenden einen dichten Vektordatentyp, um die extrahierten Merkmale aus vorab trainierten NLP-Modellen zu speichern (hier t5 oder bert, aber Sie können Ihre gewünschten vorab trainierten Modelle auch selbst hinzufügen).
{
...
"text_vector" : {
"type" : " dense_vector " ,
"dims" : 512
}
...
} Abmessungen dims:512 gilt für T5-Modelle. Ändern Sie dims auf 768, wenn Sie Bert-Modelle verwenden.
Lesen Sie das Dokument aus MySQL und konvertieren Sie es in das richtige JSON-Format, um es in großen Mengen in Elasticsearch zu übertragen.
$ cd index_files
$ pip install -r requirements.txt
$ python indexing_files.py
# or you can customize your parameters
# $ python indexing_files.py --index_file='index.json' --index_name='docsearch' --data='documents.jsonl'Gehen Sie zu http://127.0.0.1:5000.
Der Schlüsselcode für die Verwendung eines vorab trainierten Modells zum Extrahieren von Features ist die Funktion get_emb in den Dateien ./index_files/indexing_files.py und ./web/app.py .
def get_emb ( inputs_list , model_name , max_length = 512 ):
if 't5' in model_name : #T5 models, written in pytorch
tokenizer = T5Tokenizer . from_pretrained ( TOKEN_DIR )
model = T5Model . from_pretrained ( MODEL_DIR )
inputs = tokenizer . batch_encode_plus ( inputs_list , max_length = max_length , pad_to_max_length = True , return_tensors = "pt" )
outputs = model ( input_ids = inputs [ 'input_ids' ], decoder_input_ids = inputs [ 'input_ids' ])
last_hidden_states = torch . mean ( outputs [ 0 ], dim = 1 )
return last_hidden_states . tolist ()
elif 'bert' in model_name : #Bert models, written in tensorlow
tokenizer = BertTokenizer . from_pretrained ( 'bert-base-multilingual-cased' )
model = TFBertModel . from_pretrained ( 'bert-base-multilingual-cased' )
batch_encoding = tokenizer . batch_encode_plus ([ "this is" , "the second" , "the thrid" ], max_length = max_length , pad_to_max_length = True )
outputs = model ( tf . convert_to_tensor ( batch_encoding [ 'input_ids' ]))
embeddings = tf . reduce_mean ( outputs [ 0 ], 1 )
return embeddings . numpy (). tolist ()Sie können den Code ändern und Ihr bevorzugtes vorab trainiertes Modell verwenden. Sie können beispielsweise das GPT2-Modell verwenden.
Sie können Ihre elastische Suche auch anpassen, indem Sie Ihre eigene Score-Funktion anstelle von cosineSimilarity in .webapp.py verwenden.
Dieser Repräsentant wurde basierend auf Hironsan/bertsearch modifiziert, die bert-serving -Pakete verwenden, um Bert-Funktionen zu extrahieren. Es ist auf TF1.x beschränkt


