context search engine
1.0.0

Das Hauptziel dieses Projekts besteht darin, die Funktionen der Vektorsuche zu demonstrieren, indem eine benutzerfreundliche Schnittstelle bereitgestellt wird, die es Benutzern ermöglicht, kontextbezogene Suchen in einem Korpus von Textdokumenten durchzuführen. Indem wir die Leistungsfähigkeit von BERT von Hugging Face und FAISS von Facebook nutzen, geben wir hochrelevante Textpassagen zurück, die auf der semantischen Bedeutung der Suchanfrage des Benutzers basieren und nicht auf bloßen Schlüsselwortübereinstimmungen. Dieses Projekt dient als Ausgangspunkt für Entwickler, Forscher und Enthusiasten, die tiefer in die Welt der kontextualisierten Textsuche eintauchen und ihre Anwendungen mit modernsten NLP-Techniken verbessern möchten.
Mein Ziel ist es sicherzustellen, dass wir die Hintergründe der Vektordatenbank von Grund auf verstehen.
Screenshot der Anwendung:
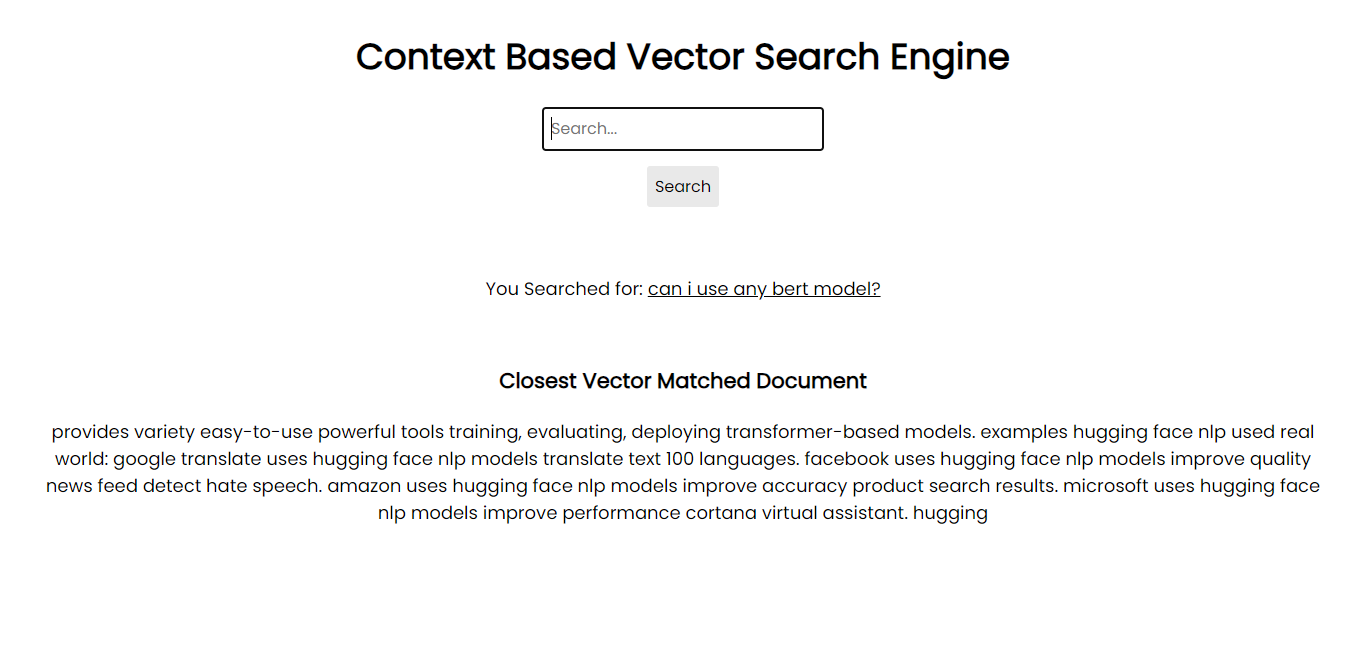
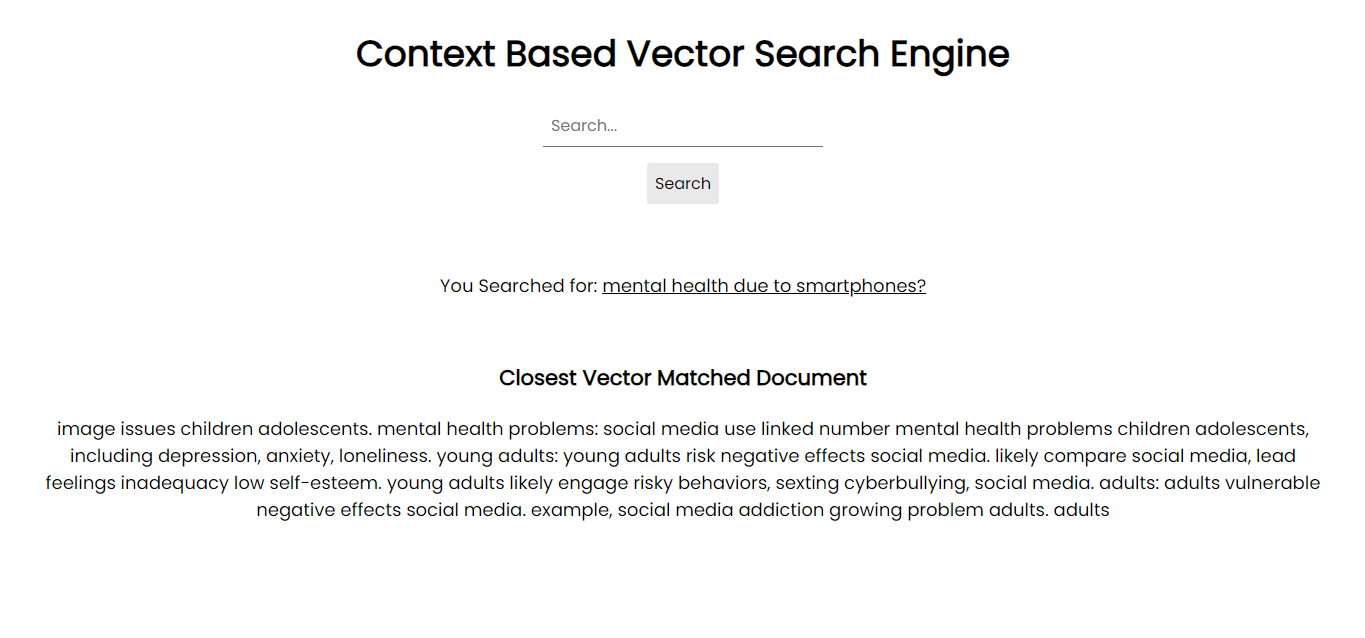
Um auf Ihrem System ausgeführt zu werden, können Sie alle erforderlichen Pakete über pip mithilfe der Anforderungsdateien installieren:
pip install -r requirements.txtZu Ihrer Information: Ich verwende Python 3.10.1.
Wenn Sie jedoch über eine GPU verfügen, werden Sie gebeten, die FAISS GPU zu installieren, um schnellere und größere Datenbankintegrationen zu ermöglichen.
Die aktuelle Version dieses Projekts umfasst:
Das Projekt bietet zwar ein funktionales kontextbezogenes Suchsystem, ist aber modular aufgebaut und ermöglicht eine mögliche Erweiterung und Integration in größere Systeme oder Anwendungen.
Die Grundlage dieses Projekts liegt in der Überzeugung, dass moderne NLP-Techniken im Vergleich zu herkömmlichen schlüsselwortbasierten Methoden weitaus genauere und kontextrelevantere Suchergebnisse liefern können. Hier ist eine Aufschlüsselung unseres Ansatzes:
Basierend auf dem Ansatz habe ich das Projekt in 2 Abschnitte unterteilt:
Abschnitt 1: Generieren durchsuchbarer vektorisierter Daten
In diesem Abschnitt lesen wir zunächst Eingaben aus Dokumenten, zerlegen sie in kleinere Teile, erstellen Vektoren mithilfe eines BERT-basierten Modells und speichern sie dann effizient mithilfe von FAISS. Hier ist ein Flussdiagramm, das dasselbe veranschaulicht.
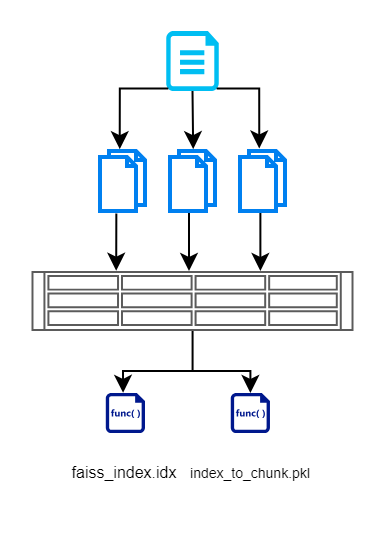
Wir erstellen eine FAISS-Indexdatei, die eine Vektordarstellung des segmentierten Dokuments enthält. Wir speichern auch den Index jedes Blocks. Dies wird beibehalten, damit wir die Datenbank/Dokumente nicht erneut abfragen müssen. Dies hilft uns, redundante Lesevorgänge zu entfernen.
Wir führen diesen Abschnitt mit create_index.py aus. Es werden die beiden oben genannten Dateien generiert. Wenn Sie andere Modelle verwenden müssen, können Sie dies über den HuggingFace-Hub tun?
Hinweis: Wenn Sie Probleme beim Einrichten von Hyperparametern für die Dimension feststellen, überprüfen Sie die Datei „config.json“ des Modells, um Details zur Dimension des Modells zu finden, das Sie verwenden möchten.
Abschnitt 2: Durchsuchbare Anwendungsschnittstelle erstellen
In diesem Abschnitt besteht mein Ziel darin, eine Schnittstelle zu erstellen, die es Benutzern ermöglicht, mit den Dokumenten zu interagieren. Ich lege Wert auf minimalistisches Design, ohne zusätzliche Hürden zu schaffen.
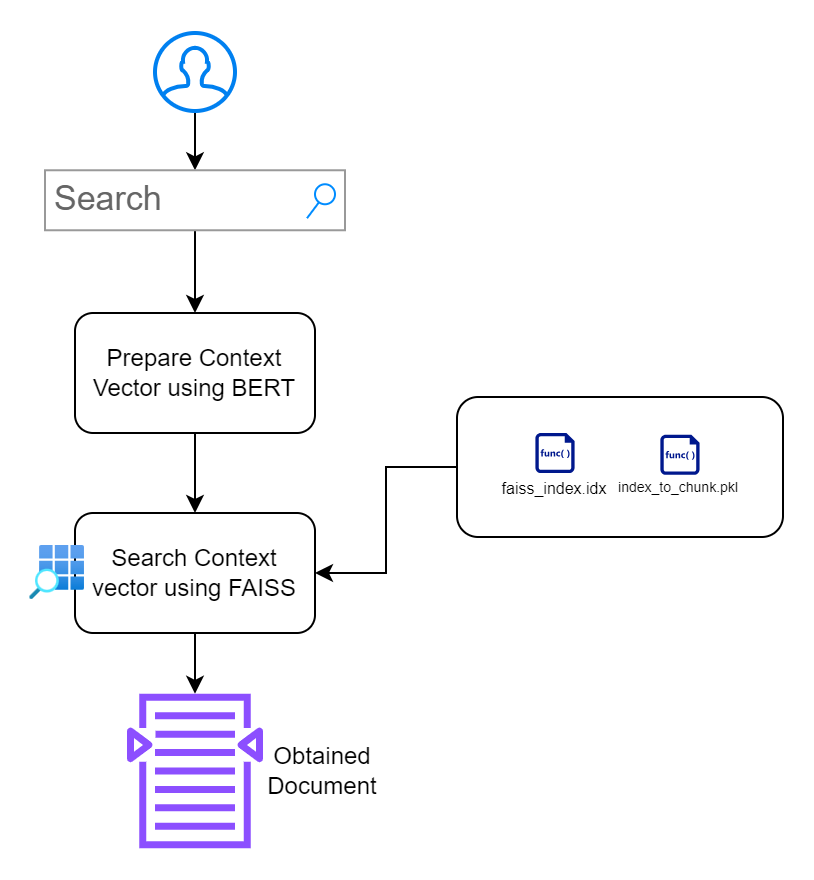
index.html : Frontend-HTML-Seite zur Eingabe von Suchanfragen.app.py : Flask-Anwendung, die das Frontend bedient und Suchanfragen verarbeitet.search_engine.py : Enthält Logik für die Einbettungsgenerierung, die FAISS-Suche und die Schlüsselworthervorhebung. /context_search/
- templates/
- index.html
- static/
- css/
- style.css
- images/
- img1.png
- img2.png
- Approach.png files
- app.py
- search_engine.py
- create_index.py
- index_to_chunk.pkl
- faiss_index.idxfaiss_index.idx ) und eine begleitende Zuordnung vom Index zum Textblock ( index_to_chunk.pkl ) verfügen. python app.py
-- OR --
flask run --host=127.0.0.1 --port=5000
http://localhost:5000 .Es gibt immer Raum für Verbesserungen. Hier sind einige mögliche Verbesserungen und zusätzliche Funktionen, die integriert werden können:
Dieses Projekt steht unter der MIT-Lizenz. Fühlen Sie sich frei, es zu verwenden, zu zitieren, zu ändern, zu verbreiten und beizutragen. Mehr lesen.
Wenn Sie daran interessiert sind, dieses Projekt zu verbessern, sind Ihre Beiträge willkommen! Bitte öffnen Sie einen Pull Request oder Issue für dieses Repository. Ich priorisiere im Wesentlichen die oben genannten Maßnahmen zur Verbesserung. Andere Pull-Anfragen werden ebenfalls berücksichtigt, haben jedoch eine geringere Priorität.
Vielen Dank im Voraus für Ihr Interesse. :Glücklich: .


