Lihang
1.0.0
Die zweite Auflage dieses Buches ist erschienen. Alle Inhaltsaktualisierungen nach Mai 2019 beziehen sich auf den Erstdruck der zweiten Auflage.
Den Inhalt der Erstausgabe finden Sie unter Release first_edition
[Inhaltsverzeichnis]
Um das Lernen zu erleichtern, sind einige Werkzeugbeschreibungen zusammengestellt.
Wenn Sie auf dieses Repo verweisen müssen:
Format: SmirkCao, Lihang, (2018), GitHub repository, https://github.com/SmirkCao/Lihang
oder
@misc{SmirkCao,
author = {SmirkCao},
title = {Lihang},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/SmirkCao/Lihang}},
commit = {c5624a9bd757a5cc88e78b85b89e9221deb08270}
}
Dieser Teil des Inhalts entspricht nicht dem Vorwort in „Statistische Lernmethoden“. Das Vorwort im Buch ist ebenfalls gut geschrieben und wird wie folgt zitiert:
- Bei der Inhaltsauswahl konzentrieren wir uns auf die Einführung der wichtigsten und am häufigsten verwendeten Methoden, insbesondere Methoden im Zusammenhang mit Klassifizierungs- und Kennzeichnungsproblemen .
- Versuchen Sie, alle Methoden in einem einheitlichen Rahmen zu diskutieren, damit das gesamte Buch nicht seine Systematik verliert.
- Gilt für Studenten und Doktoranden mit den Schwerpunkten Informationsbeschaffung und Verarbeitung natürlicher Sprache.
Zu beachten ist auch der berufliche Hintergrund des Autors.
Der Autor hat sich mit der Erforschung verschiedener intelligenter Verarbeitungen von Textdaten unter Verwendung statistischer Lernmethoden beschäftigt, einschließlich der Verarbeitung natürlicher Sprache, des Informationsabrufs und des Text Data Mining.
Wenn Sie mein Modell verwenden, um die Ähnlichkeitssuche zu implementieren, ist das Buch, das dem Buch von Herrn Li ähnelt, „Semiconductor Optoelectronic Devices“. Schade, dass ich es in meiner Jugend nicht wiederholt gelesen habe.
Ich hoffe, dass das gesamte Buch beim wiederholten Lesen immer dicker und dünner wird. Alle Dokumente und Codes in dieser Reihe beziehen sich, sofern nicht anders angegeben, auf „Statistische Lernmethoden“ von Lehrer Li Hang. Inhalte in anderen Referenzen werden bei Zitierung verlinkt.
Einige Referenzen sind in Refs aufgeführt, von denen einige sehr hilfreich für das Verständnis des Buchinhalts sind. Beschreibungen und Erläuterungen dieser Dateien werden in Refs/README.md entsprechend dem Referenzabschnitt hinzugefügt. Einige Hinweise zu anderen Referenzen wurden diesem Dokument ebenfalls hinzugefügt.
Um das Herunterladen von Referenzen zu erleichtern, wurde während review02 ref_downloader.sh hinzugefügt, mit dem die im Buch aufgeführten Referenzen heruntergeladen werden können. Der Aktualisierungsprozess wird im Verlauf von review02 schrittweise abgeschlossen.
Darüber hinaus ist dieses Buch von Lehrer Li Hang, Es ist wirklich dünn (die zweite Version ist nicht mehr dünn) , aber fast jeder Satz bringt viele Punkte zum Vorschein und ist es wert, immer wieder gelesen zu werden.
Nach dem Inhaltsverzeichnis im Buch befindet sich eine Symboltabelle, in der die Symboldefinitionen erläutert werden. Wenn Sie also Symbole nicht verstehen, können Sie diese in der Tabelle nachschlagen. Am Ende des Buches befindet sich ein Index. und Sie können den Index verwenden, um die Bedeutung des entsprechenden Symbols zu finden, das im Buchstandort erscheint. In diesem Repo wird eine glossary_index.md gepflegt, um einige Erläuterungen zu den entsprechenden Symbolen hinzuzufügen und die den Symbolen entsprechenden Seitenzahlen direkt zu markieren. Der Fortschritt wird mit der Überprüfung aktualisiert.
Nach jedem Algorithmus oder Beispiel steht ein ◼️, was anzeigt, dass der Algorithmus oder das Beispiel hier endet. Dies wird als Proof-End-Symbol bezeichnet. Sie werden es kennen, wenn Sie mehr Literatur lesen.
Beim Lesen haben wir oft Fragen zur Basis von Logarithmen. Einige der wichtigeren werden im Buch hervorgehoben. Einige, die nicht hervorgehoben werden, können durch den Kontext verstanden werden. Da es außerdem eine Formel zum Ändern der Basis gibt, spielt es keine große Rolle, was die Basis ist. Der Unterschied liegt in einem konstanten Koeffizienten. Die Wahl verschiedener Basen hat jedoch physikalische Bedeutungen und Überlegungen zur Problemlösung. Zur Analyse dieses Problems können Sie sich die Diskussion zur Entropie in PRML 1.6 ansehen.
Was die Frage der konstanten Koeffizienten in der Formel betrifft, kann außerdem die Konvergenzgeschwindigkeit verbessert werden, wenn eine iterative Lösung verwendet wird und die Formel manchmal bis zu einem gewissen Grad vereinfacht wird. Die Details können nach und nach in der Praxis verstanden werden.
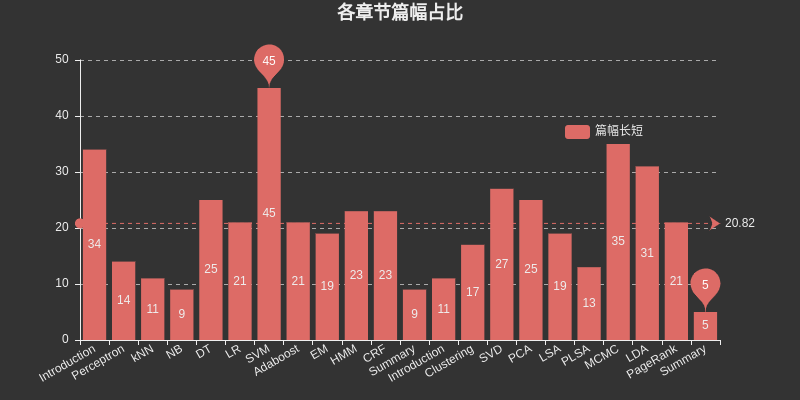
Fügen Sie hier ein Diagramm ein, um den von den einzelnen Kapiteln belegten Platz aufzulisten. Unter diesen nimmt SVM den größten Platz unter überwachtem Lernen ein, MCMC nimmt den größten Platz unter unüberwachtem Lernen ein und DT, HMM, CRF, SVD, PCA, LDA usw PageRank nimmt auch den größten Raum ein.
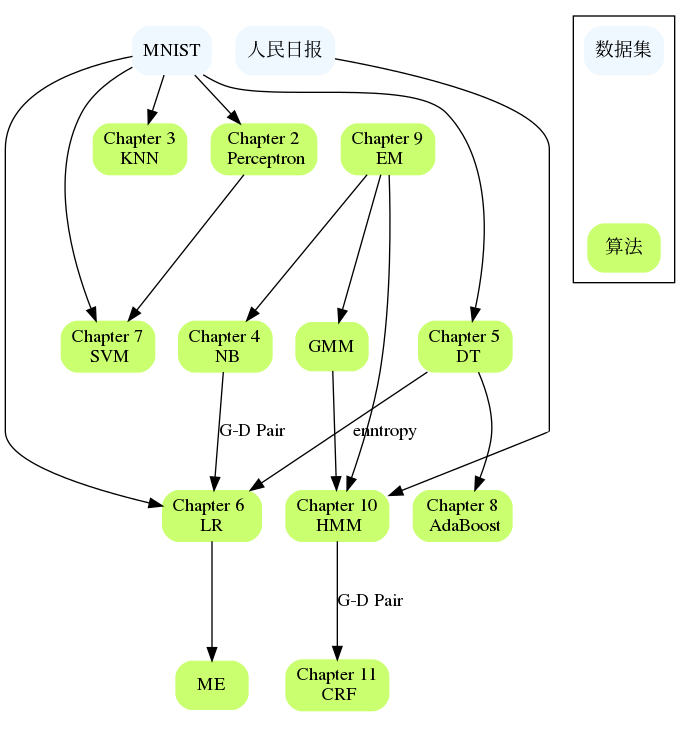
Die Kapitel stehen in Beziehung zueinander, z. B. NB und LR, DT und AdaBoost, Perceptron und SVM, HMM und CRF usw. Wenn Sie in einem großen Kapitel auf Schwierigkeiten stoßen, können Sie den Inhalt der vorherigen Kapitel noch einmal durchgehen oder die Referenzen überprüfen In der Regel werden Verweise auf bestimmte Kapitel gegeben, die das Problem detaillierter beschreiben und möglicherweise erklären, wo Sie nicht weiterkommen.
Einführung
Drei Elemente statistischer Lernmethoden:
Modell
Strategie
Algorithmus
In der zweiten Auflage wurde die Verzeichnisstruktur dieses Kapitels neu organisiert, um es übersichtlicher zu machen.
Perzeptron
kNN
Hinweis:
DT
LR
Bezüglich der Untersuchung der maximalen Entropie wird empfohlen, die Referenzliteratur [1] in diesem Kapitel, Berger, 1996, zu lesen, die für das Verständnis der Beispiele im Buch und das Verständnis des Prinzips der maximalen Entropie hilfreich ist.
Warum werden LR und Maxent in einem Kapitel zusammengefasst?
Alle gehören zum logarithmischen linearen Modell
Beide können zur binären Klassifizierung und Mehrfachklassifizierung verwendet werden
Die Lernmethoden der beiden Modelle verwenden im Allgemeinen die Maximum-Likelihood-Schätzung oder die regulierte Maximum-Likelihood-Schätzung. Sie können als uneingeschränktes Optimierungsproblem formalisiert werden, und die Lösungsmethoden umfassen IIS, GD, BFGS usw.
In der logistischen Regression wird es wie folgt beschrieben:
Die logistische Regression ist trotz ihres Namens eher ein lineares Klassifizierungsmodell als eine logistische Regression, die in der Literatur auch als Logit-Regression, Maximum-Entropie-Klassifizierung (MaxEnt) oder logarithmisch-linearer Klassifikator bezeichnet wird Die möglichen Ergebnisse eines einzelnen Versuchs werden mithilfe einer Logistikfunktion modelliert.
Es gibt auch eine solche Beschreibung
Die logistische Regression ist ein Sonderfall maximaler Entropie mit zwei Bezeichnungen +1 und −1.
Die Ableitung in diesem Kapitel verwendet die Eigenschaft von $yin mathcal{Y}={0,1}$
Manchmal sagen wir, dass die logistische Regression im NLP Maxent genannt wird
SVM
Boosten
Lassen Sie es uns hier aufschlüsseln, da HMM und CRF normalerweise später zur Einführung probabilistischer grafischer Modelle führen. In „Maschinelles Lernen, Zhou Zhihua“ wird ein separates Kapitel über probabilistische grafische Modelle verwendet, um HMM, MRF, CRF und andere Inhalte einzubeziehen. Darüber hinaus gibt es viele verwandte Punkte von HMM bis CRF selbst.
Im ersten Kapitel des Buches werden drei Anwendungen des überwachten Lernens erläutert: Klassifizierung, Kennzeichnung und Regression. Es gibt Ergänzungen in Kapitel 12. Dieses Buch befasst sich hauptsächlich mit den Lernmethoden der ersten beiden. Dementsprechend ist auch hier die Segmentierung angebracht. Das Klassifizierungsmodell wird in einem kleinen Teil erwähnt. Das Kennzeichnungsproblem wird hauptsächlich später eingeführt.
EM
Der EM-Algorithmus ist ein iterativer Algorithmus, der zur Maximum-Likelihood-Schätzung probabilistischer Modellparameter, die versteckte Variablen enthalten, oder zur Maximum-Posteriori-Wahrscheinlichkeitsschätzung verwendet wird. (Die Maximum-Likelihood-Schätzung und die Maximum-Posteriori-Wahrscheinlichkeitsschätzung sind hier Lernstrategien .)
Wenn die Variablen des Wahrscheinlichkeitsmodells alle beobachtete Variablen sind, können die Modellparameter anhand der Daten direkt mithilfe der Maximum-Likelihood-Schätzmethode oder der Bayes'schen Schätzmethode geschätzt werden.
Beachten Sie: Wenn Sie diese Beschreibung im Buch nicht verstehen, lesen Sie bitte den Abschnitt zur Parameterschätzung der Naive-Bayes-Methode in CH04.
Dieser Teil des Codes implementiert BMM und GMM, es lohnt sich, einen Blick darauf zu werfen
In Bezug auf EM wurde nicht viel über dieses Kapitel geschrieben. EM und Hinton haben 2018 den zweiten Artikel von Capsule Network „Matrix Capsules with EM Routing“ veröffentlicht.
In CH22 wird der EM-Algorithmus als grundlegende Methode des maschinellen Lernens klassifiziert und umfasst keine spezifischen Modelle des maschinellen Lernens. Er kann für unbeaufsichtigtes Lernen, überwachtes Lernen und halbüberwachtes Lernen verwendet werden.
HMM
CRF
Zusammenfassung
Dieses Kapitel umfasst nur wenige Seiten. Sie können die folgende Leseroutine berücksichtigen:
Lesen Sie es zusammen mit Kapitel 1
Sollten Sie in früheren Studien auf unklare Fragen stoßen, lesen Sie dieses Kapitel noch einmal.
Lesen Sie dieses Kapitel gründlich durch und erweitern Sie es auf zehn weitere Kapitel.
Beachten Sie, dass es in diesem Kapitel Abbildung 12.2 gibt, in der die logistische Verlustfunktion erwähnt wird, die in $cal{Y}={+1,-1}$ definiert werden sollte ist bei $cal{Y}={0,1}$ definiert, bitte beachten Sie hier.
Durch das Buch von Lehrer Li gewinnt man wirklich jedes Mal etwas Neues, wenn man es liest.
Die zweite Ausgabe fügt acht unbeaufsichtigte Lernmethoden hinzu: Clustering, Singularwertzerlegung, Hauptkomponentenanalyse, latente semantische Analyse, probabilistische latente semantische Analyse, Markov-Ketten-Monte-Carlo-Methode, latente Dirichlet-Zuordnung und PageRank.
Einführung
Clustering
Nicht jedes Kapitel in diesem Buch ist vollständig unabhängig. In diesem Teil sollen die Verbindungen zwischen Kapiteln und anwendbaren Datensätzen organisiert werden. Ein Aspekt ist auch, wie weit der Algorithmus implementiert ist und auf welchen Datensätzen er ausgeführt werden kann.