textgenrnn
T
Trainieren Sie ganz einfach Ihr eigenes textgenerierendes neuronales Netzwerk beliebiger Größe und Komplexität anhand eines beliebigen Textdatensatzes mit wenigen Codezeilen oder trainieren Sie schnell einen Text mithilfe eines vorab trainierten Modells.
textgenrnn ist ein Python 3-Modul auf Keras/TensorFlow zum Erstellen von char-rnns mit vielen coolen Funktionen:
In diesem Colaboratory Notebook können Sie kostenlos mit textgenrnn spielen und jede Textdatei mit einer GPU trainieren! Lesen Sie diesen Blogbeitrag oder schauen Sie sich dieses Video an, um weitere Informationen zu erhalten!
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate () [Spoiler] Anyone else find this post and their person that was a little more than I really like the Star Wars in the fire or health and posting a personal house of the 2016 Letter for the game in a report of my backyard.
Das enthaltene Modell kann problemlos auf neue Texte trainiert werden und kann bereits nach einem einzigen Durchgang der Eingabedaten geeigneten Text generieren.
textgen . train_from_file ( 'hacker_news_2000.txt' , num_epochs = 1 )
textgen . generate () Project State Project Firefox
Die Modellgewichte sind relativ gering (2 MB auf der Festplatte) und können problemlos gespeichert und in eine neue Textgenrnn-Instanz geladen werden. Dadurch können Sie mit Modellen spielen, die in Hunderten von Datendurchläufen trainiert wurden. (Tatsächlich lernt textgenrnn so gut , dass man die Temperatur deutlich erhöhen muss, um kreative Ergebnisse zu erzielen!)
textgen_2 = textgenrnn ( '/weights/hacker_news.hdf5' )
textgen_2 . generate ( 3 , temperature = 1.0 ) Why we got money “regular alter”
Urburg to Firefox acquires Nelf Multi Shamn
Kubernetes by Google’s Bern
Sie können auch ein neues Modell trainieren, das Einbettungen auf Wortebene und bidirektionale RNN-Schichten unterstützt, indem Sie new_model=True zu einer beliebigen Zugfunktion hinzufügen.
Es ist auch möglich, Schritt für Schritt mitzumachen, wie sich das Ergebnis entwickelt. Der interaktive Modus schlägt Ihnen die Top-N -Optionen für das nächste Zeichen/Wort vor und ermöglicht Ihnen die Auswahl einer davon.
Wenn Sie textgenrnn im Terminal ausführen, übergeben Sie interactive=True und top=N um zu generate . N ist standardmäßig 3.
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate ( interactive = True , top_n = 5 )
Dies kann der Ausgabe eine menschliche Note verleihen; es fühlt sich an, als wärst du der Autor! (Referenz)
textgenrnn kann von Pypi über pip installiert werden:
pip3 install textgenrnnFür das neueste Textgenrnn müssen Sie über eine TensorFlow-Mindestversion von 2.1.0 verfügen .
In diesem Jupyter Notebook können Sie eine Demo allgemeiner Funktionen und Modellkonfigurationsoptionen ansehen.
/datasets enthält Beispieldatensätze, die Hacker News/Reddit-Daten zum Training von textgenrnn verwenden.
/weights enthält weiter vorab trainierte Modelle zu den oben genannten Datensätzen, die in textgenrnn geladen werden können.
/outputs enthält Beispiele für Text, der aus den oben vorab trainierten Modellen generiert wurde.
textgenrnn basiert auf dem char-rnn-Projekt von Andrej Karpathy mit einigen modernen Optimierungen, wie beispielsweise der Möglichkeit, mit sehr kleinen Textsequenzen zu arbeiten.
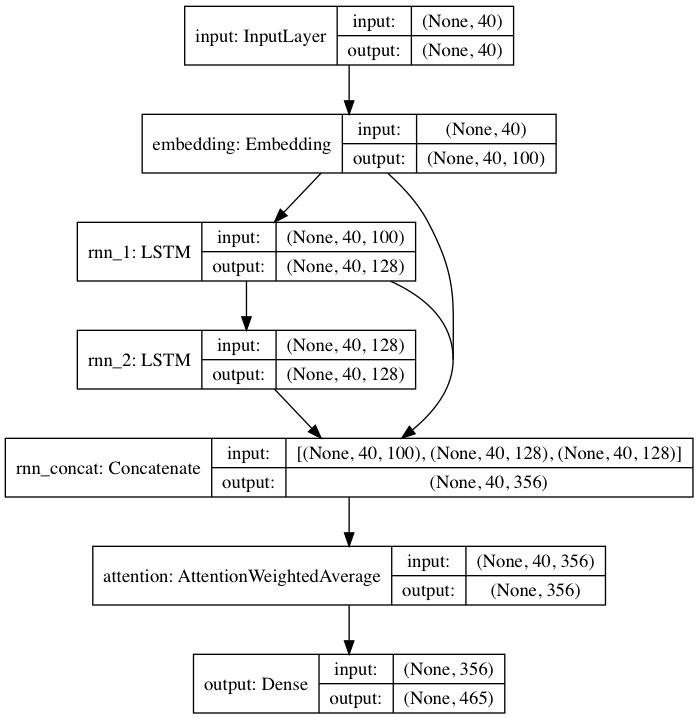
Das enthaltene vorab trainierte Modell folgt einer von DeepMoji inspirierten neuronalen Netzwerkarchitektur. Für das Standardmodell nimmt textgenrnn eine Eingabe von bis zu 40 Zeichen auf, wandelt jedes Zeichen in einen 100-D-Zeicheneinbettungsvektor um und speist diese in eine wiederkehrende 128-Zellen-Long-Short-Term-Memory-Schicht (LSTM) ein. Diese Ausgänge werden dann in ein weiteres 128-Zellen-LSTM eingespeist. Alle drei Schichten werden dann in eine Aufmerksamkeitsschicht eingespeist, um die wichtigsten zeitlichen Merkmale zu gewichten und sie zu mitteln (und da die Einbettungen + das 1. LSTM überspringend mit der Aufmerksamkeitsschicht verbunden sind, können sich die Modellaktualisierungen leichter auf sie zurückpropagieren und ein Verschwinden verhindern Farbverläufe). Dieser Ausgabe werden Wahrscheinlichkeiten für bis zu 394 verschiedene Zeichen zugeordnet, dass sie das nächste Zeichen in der Sequenz sind, einschließlich Großbuchstaben, Kleinbuchstaben, Satzzeichen und Emojis. (Wenn Sie ein neues Modell auf einem neuen Datensatz trainieren, können alle oben genannten numerischen Parameter konfiguriert werden.)
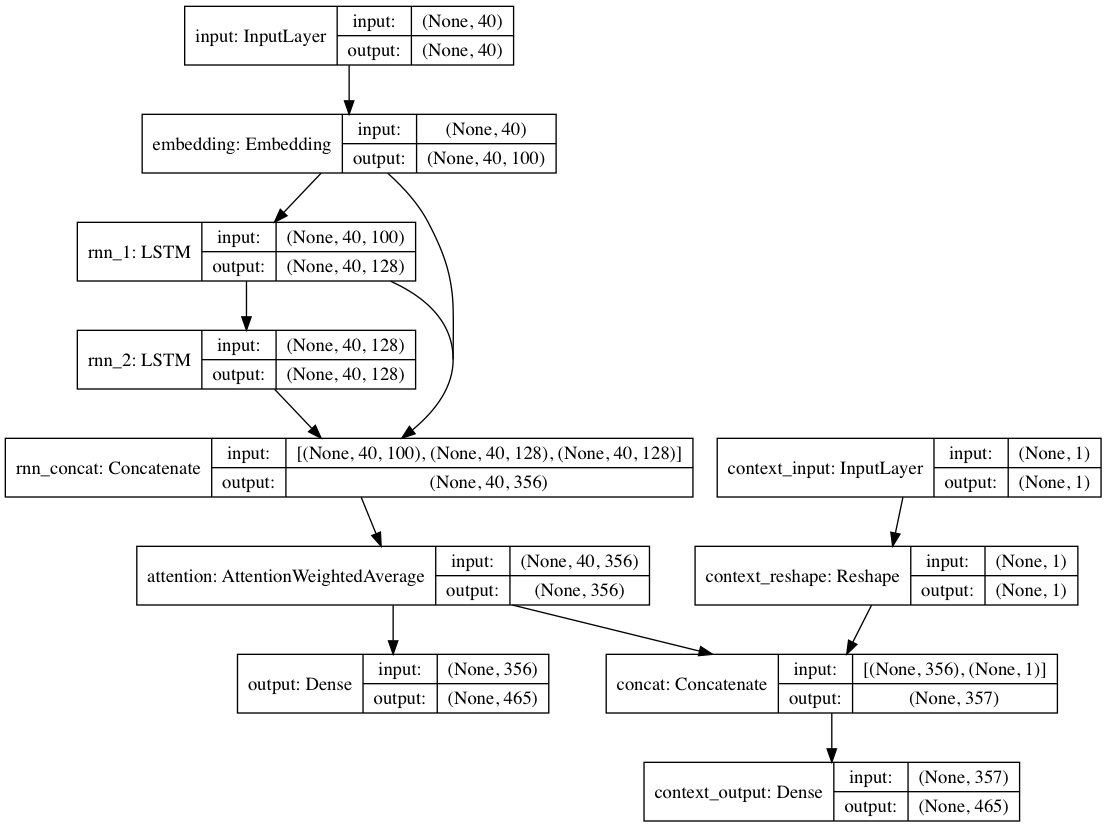
Wenn alternativ zu jedem Textdokument Kontextbezeichnungen bereitgestellt werden, kann das Modell in einem kontextuellen Modus trainiert werden, in dem das Modell den Text anhand des Kontexts lernt, sodass die wiederkehrenden Ebenen die dekontextualisierte Sprache lernen. Der Nur-Text-Pfad kann die dekontextualisierten Ebenen huckepack nehmen; Insgesamt führt dies zu einem viel schnelleren Training und einer besseren quantitativen und qualitativen Modellleistung als nur das Training des Modells allein anhand des Textes.
Die im Paket enthaltenen Modellgewichte werden anhand von Hunderttausenden Textdokumenten aus Reddit-Einreichungen (über BigQuery) und einer Vielzahl von Subreddits trainiert. Das Netzwerk wurde auch mithilfe des oben erwähnten dekontextuellen Ansatzes trainiert, um sowohl die Trainingsleistung zu verbessern als auch die Voreingenommenheit des Autors zu mildern.
Bei der Feinabstimmung des Modells für einen neuen Textdatensatz mithilfe von textgenrnn werden alle Ebenen neu trainiert. Da das ursprüngliche vorab trainierte Netzwerk jedoch zunächst über ein viel robusteres „Wissen“ verfügt, trainiert das neue Textgenrnn am Ende schneller und genauer und kann möglicherweise neue Beziehungen lernen, die im ursprünglichen Datensatz nicht vorhanden sind (z. B. umfassen die vorab trainierten Zeicheneinbettungen den Kontext). für das Zeichen für alle möglichen Arten moderner Internet-Grammatik).
Darüber hinaus erfolgt das Umtraining mit einem impulsbasierten Optimierer und einer linear abfallenden Lernrate. Beides verhindert explodierende Gradienten und macht es deutlich unwahrscheinlicher, dass das Modell nach längerem Training divergiert.
Selbst mit einem stark trainierten neuronalen Netzwerk erhalten Sie nicht in 100 % der Fälle qualitativ hochwertigen Text . Das ist der Hauptgrund dafür, dass virale Blog-Posts/Twitter-Tweets, die die NN-Textgenerierung nutzen, oft viele Texte generieren und die besten anschließend kuratieren/bearbeiten.
Die Ergebnisse variieren stark zwischen den Datensätzen . Da das vorab trainierte neuronale Netzwerk relativ klein ist, kann es nicht so viele Daten speichern wie RNNs, die normalerweise in Blogbeiträgen zur Schau gestellt werden. Um optimale Ergebnisse zu erzielen, verwenden Sie einen Datensatz mit mindestens 2.000–5.000 Dokumenten. Wenn ein Datensatz kleiner ist, müssen Sie ihn länger trainieren, indem Sie num_epochs höher festlegen, wenn Sie eine Trainingsmethode aufrufen und/oder ein neues Modell von Grund auf trainieren. Selbst dann gibt es derzeit keine gute Heuristik zur Bestimmung eines „guten“ Modells.
Zum erneuten Trainieren von textgenrnn ist keine GPU erforderlich, das Training auf einer CPU dauert jedoch viel länger. Wenn Sie eine GPU verwenden, empfehle ich, den Parameter batch_size zu erhöhen, um die Hardwareauslastung zu verbessern.
Formellere Dokumentation
Eine webbasierte Implementierung mit tensorflow.js (funktioniert aufgrund der geringen Größe des Netzwerks besonders gut)
Eine Möglichkeit, die Ausgaben der Aufmerksamkeitsschicht zu visualisieren, um zu sehen, wie das Netzwerk „lernt“.
Ein Modus, der die Verwendung der Modellarchitektur für Chatbot-Gespräche ermöglicht (kann als separates Projekt veröffentlicht werden)
Mehr Tiefe zum Kontext (Positionskontext + Ermöglichen mehrerer Kontextbezeichnungen)
Ein größeres vorab trainiertes Netzwerk, das längere Zeichenfolgen und ein tieferes Verständnis der Sprache verarbeiten kann und so besser generierte Sätze erzeugt.
Hierarchische Softmax-Aktivierung für Modelle auf Wortebene (sobald Keras gute Unterstützung dafür hat).
FP16 für superschnelles Training auf Volta/TPUs (sobald Keras gute Unterstützung dafür hat).
Max Woolf (@minimaxir)
Max‘ Open-Source-Projekte werden von seinem Patreon unterstützt. Wenn Sie dieses Projekt hilfreich fanden, freuen wir uns über jeden finanziellen Beitrag zum Patreon, der sinnvoll und kreativ genutzt werden kann.
Andrej Karpathy für den ursprünglichen Vorschlag des char-rnn über den Blogbeitrag The Unreasonable Effectiveness of Recurrent Neural Networks.
Daniel Grijalva für seinen interaktiven Modus.
MIT
Von DeepMoji verwendeter Aufmerksamkeitsschichtcode (MIT-lizenziert)


