cleanrl
v1.0.0 CleanRL Release ?
CleanRL ist eine Deep Reinforcement Learning-Bibliothek, die eine hochwertige Einzeldateiimplementierung mit forschungsfreundlichen Funktionen bietet. Die Implementierung ist sauber und einfach, wir können sie jedoch skalieren, um mit AWS Batch Tausende von Experimenten durchzuführen. Die Highlight-Funktionen von CleanRL sind:
ppo_atari.py nur 340 Codezeilen, enthält aber alle Implementierungsdetails darüber, wie PPO mit Atari-Spielen funktioniert. Daher ist es eine großartige Referenzimplementierung zum Lesen für Leute, die nicht eine ganze modulare Bibliothek lesen möchten .Weitere Informationen zu CleanRL finden Sie in unserem JMLR-Artikel und der Dokumentation.
Bemerkenswerte CleanRL-bezogene Projekte:
Unterstützung für Gymnasium : Farama-Foundation/Gymnasium ist die nächste Generation von
openai/gym, die weiterhin gepflegt wird und neue Funktionen einführt. Weitere Einzelheiten finden Sie in der Ankündigung. Wir migrieren zumgymnasiumund der Fortschritt kann in vwxyzjn/cleanrl#277 verfolgt werden.
️ HINWEIS : CleanRL ist keine modulare Bibliothek und daher nicht zum Importieren gedacht. Auf Kosten von doppeltem Code machen wir alle Implementierungsdetails einer DRL-Algorithmusvariante leicht verständlich, sodass CleanRL seine eigenen Vor- und Nachteile hat. Sie sollten die Verwendung von CleanRL in Betracht ziehen, wenn Sie 1) alle Implementierungsdetails der Variante eines Algorithmus verstehen oder 2) erweiterte Funktionen prototypisieren möchten, die andere modulare DRL-Bibliotheken nicht unterstützen (CleanRL verfügt über nur minimale Codezeilen, sodass Sie eine hervorragende Debugging-Erfahrung erhalten und nicht Ich muss nicht viele Unterklassen erstellen, wie es manchmal in modularen DRL-Bibliotheken der Fall ist.
Voraussetzungen:
Um Experimente lokal durchzuführen, probieren Sie Folgendes aus:
git clone https://github.com/vwxyzjn/cleanrl.git && cd cleanrl
poetry install
# alternatively, you could use `poetry shell` and do
# `python run cleanrl/ppo.py`
poetry run python cleanrl/ppo.py
--seed 1
--env-id CartPole-v0
--total-timesteps 50000
# open another terminal and enter `cd cleanrl/cleanrl`
tensorboard --logdir runsUm die Experimentverfolgung mit wandb zu verwenden, führen Sie Folgendes aus:
wandb login # only required for the first time
poetry run python cleanrl/ppo.py
--seed 1
--env-id CartPole-v0
--total-timesteps 50000
--track
--wandb-project-name cleanrltest Wenn Sie keine poetry verwenden, können Sie CleanRL mit requirements.txt installieren:
# core dependencies
pip install -r requirements/requirements.txt
# optional dependencies
pip install -r requirements/requirements-atari.txt
pip install -r requirements/requirements-mujoco.txt
pip install -r requirements/requirements-mujoco_py.txt
pip install -r requirements/requirements-procgen.txt
pip install -r requirements/requirements-envpool.txt
pip install -r requirements/requirements-pettingzoo.txt
pip install -r requirements/requirements-jax.txt
pip install -r requirements/requirements-docs.txt
pip install -r requirements/requirements-cloud.txt
pip install -r requirements/requirements-memory_gym.txtSo führen Sie Trainingsskripte in anderen Spielen aus:
poetry shell
# classic control
python cleanrl/dqn.py --env-id CartPole-v1
python cleanrl/ppo.py --env-id CartPole-v1
python cleanrl/c51.py --env-id CartPole-v1
# atari
poetry install -E atari
python cleanrl/dqn_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/c51_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/ppo_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/sac_atari.py --env-id BreakoutNoFrameskip-v4
# NEW: 3-4x side-effects free speed up with envpool's atari (only available to linux)
poetry install -E envpool
python cleanrl/ppo_atari_envpool.py --env-id BreakoutNoFrameskip-v4
# Learn Pong-v5 in ~5-10 mins
# Side effects such as lower sample efficiency might occur
poetry run python ppo_atari_envpool.py --clip-coef=0.2 --num-envs=16 --num-minibatches=8 --num-steps=128 --update-epochs=3
# procgen
poetry install -E procgen
python cleanrl/ppo_procgen.py --env-id starpilot
python cleanrl/ppg_procgen.py --env-id starpilot
# ppo + lstm
poetry install -E atari
python cleanrl/ppo_atari_lstm.py --env-id BreakoutNoFrameskip-v4
Sie können auch eine vorgefertigte Entwicklungsumgebung verwenden, die in Gitpod gehostet wird:
| Algorithmus | Varianten implementiert |
|---|---|
| ✅ Proximaler Richtliniengradient (PPO) | ppo.py , Dokumente |
ppo_atari.py , Dokumente | |
ppo_continuous_action.py , Dokumente | |
ppo_atari_lstm.py , Dokumente | |
ppo_atari_envpool.py , Dokumente | |
ppo_atari_envpool_xla_jax.py , Dokumente | |
ppo_atari_envpool_xla_jax_scan.py , Dokumente) | |
ppo_procgen.py , Dokumente | |
ppo_atari_multigpu.py , Dokumente | |
ppo_pettingzoo_ma_atari.py , Dokumente | |
ppo_continuous_action_isaacgym.py , Dokumente | |
ppo_trxl.py , Dokumente | |
| ✅ Deep Q-Learning (DQN) | dqn.py , Dokumente |
dqn_atari.py , Dokumente | |
dqn_jax.py , Dokumente | |
dqn_atari_jax.py , Dokumente | |
| ✅ Kategorischer DQN (C51) | c51.py , Dokumente |
c51_atari.py , Dokumente | |
c51_jax.py , Dokumente | |
c51_atari_jax.py , Dokumente | |
| ✅ Soft Actor-Critic (SAC) | sac_continuous_action.py , Dokumente |
sac_atari.py , Dokumente | |
| ✅ Deep Deterministic Policy Gradient (DDPG) | ddpg_continuous_action.py , Dokumente |
ddpg_continuous_action_jax.py , Dokumente | |
| ✅ Twin Delayed Deep Deterministic Policy Gradient (TD3) | td3_continuous_action.py , Dokumente |
td3_continuous_action_jax.py , Dokumente | |
| ✅ Phasischer Politikgradient (PPG) | ppg_procgen.py , Dokumente |
| ✅ Random Network Distillation (RND) | ppo_rnd_envpool.py , Dokumente |
| ✅ Qdagger | qdagger_dqn_atari_impalacnn.py , Dokumente |
qdagger_dqn_atari_jax_impalacnn.py , Dokumente |
Um unsere experimentellen Daten transparent zu machen, beteiligt sich CleanRL an einem verwandten Projekt namens Open RL Benchmark, das nachverfolgte Experimente aus beliebten DRL-Bibliotheken wie unserer, Stable-baselines3, openai/baselines, jaxrl und anderen enthält.
Unter https://benchmark.cleanrl.dev/ finden Sie eine Sammlung von Gewichtungs- und Biases-Berichten, die verfolgte DRL-Experimente präsentieren. Die Berichte sind interaktiv und Forscher können problemlos Informationen wie die GPU-Auslastung und Videos des Gameplays eines Agenten abfragen, die in anderen RL-Benchmarks normalerweise schwer zu erhalten sind. In Zukunft wird Open RL Benchmark wahrscheinlich eine Datensatz-API bereitstellen, damit Forscher einfach auf die Daten zugreifen können (siehe Repo).
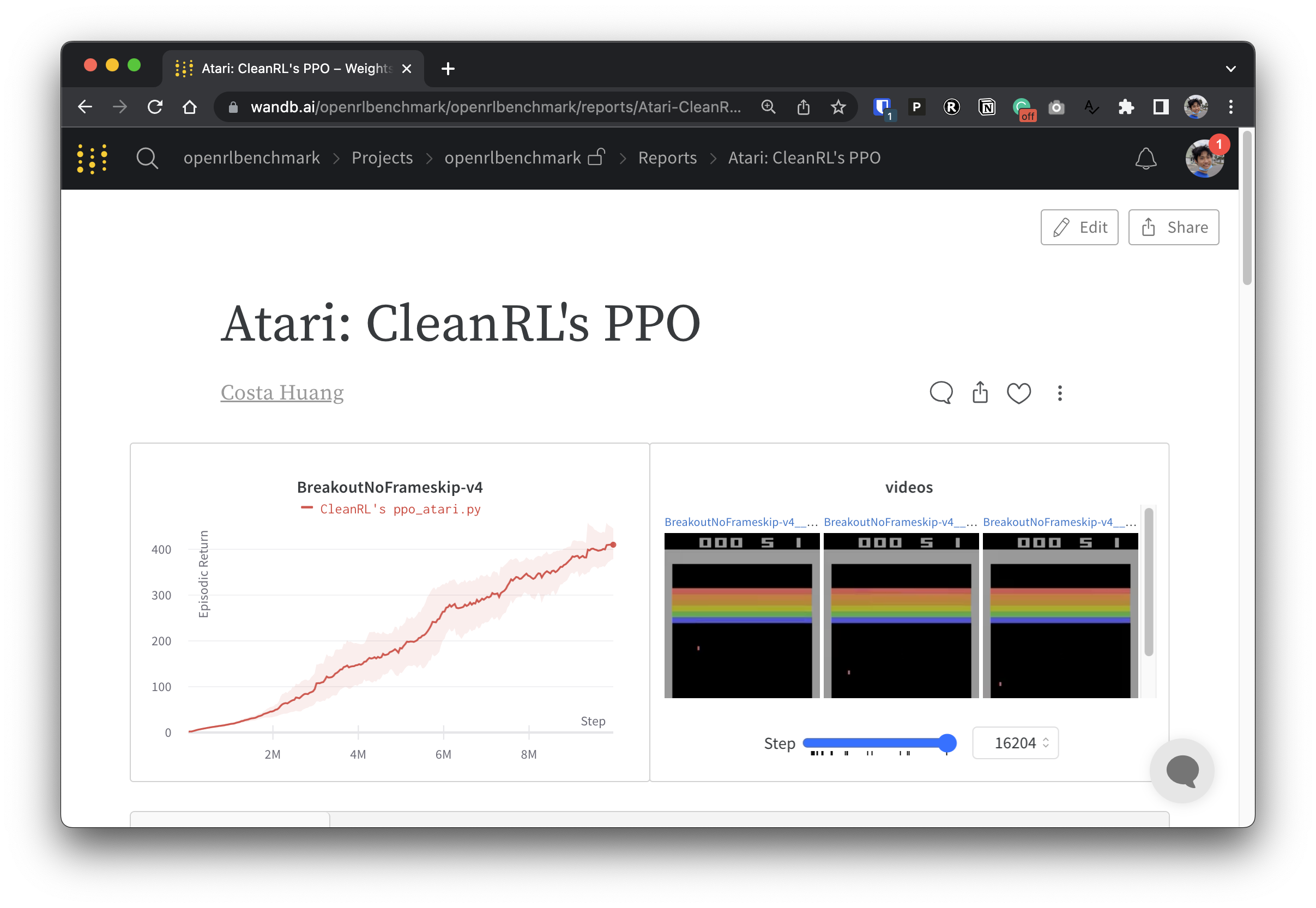
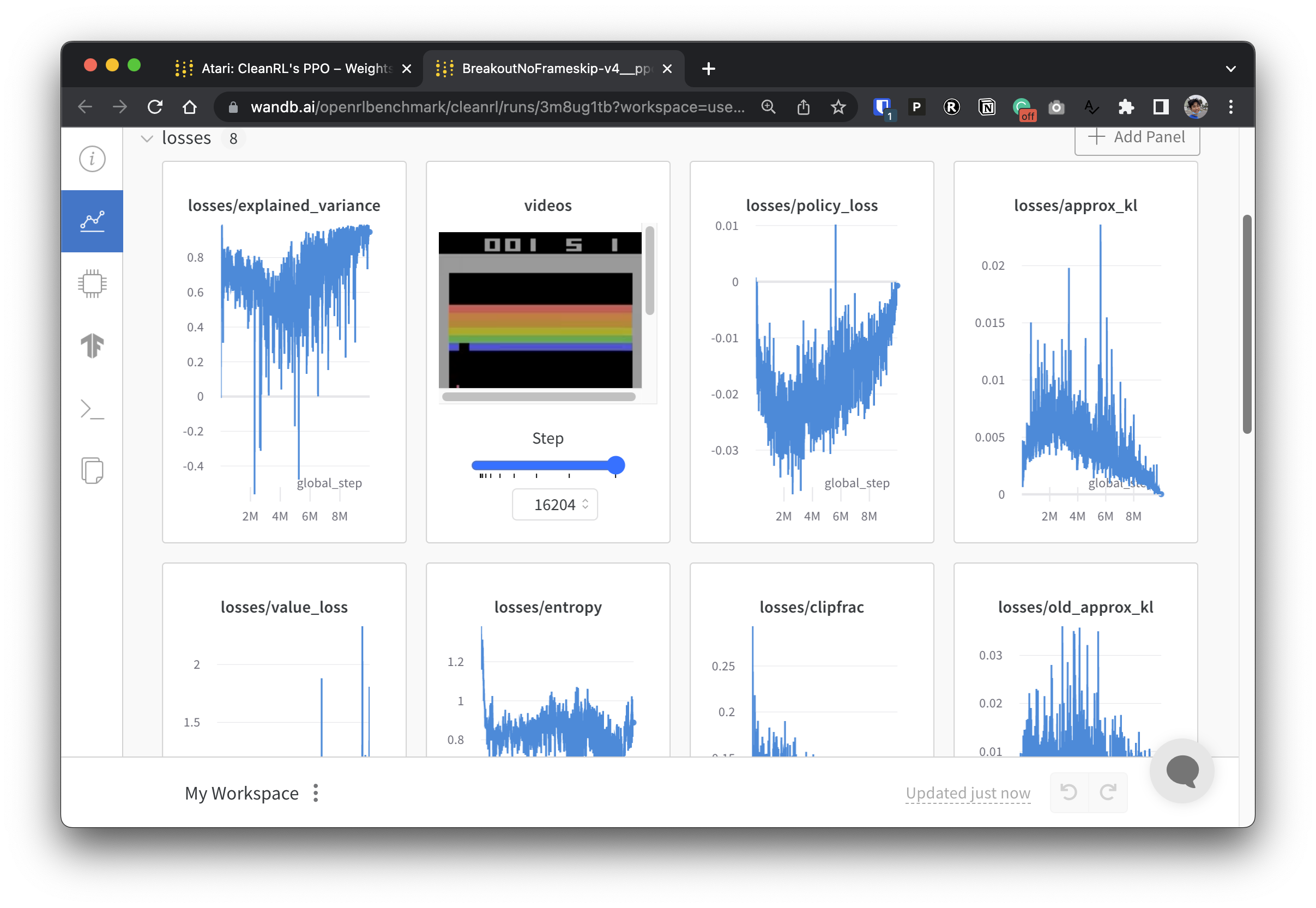
Wir haben eine Discord-Community zur Unterstützung. Stellen Sie gerne Fragen. Das Posten in Github-Problemen und PRs ist ebenfalls willkommen. Auch unsere vergangenen Videoaufzeichnungen sind auf YouTube verfügbar
Wenn Sie CleanRL in Ihrer Arbeit verwenden, zitieren Sie bitte unser Fachpapier:
@article { huang2022cleanrl ,
author = { Shengyi Huang and Rousslan Fernand Julien Dossa and Chang Ye and Jeff Braga and Dipam Chakraborty and Kinal Mehta and João G.M. Araújo } ,
title = { CleanRL: High-quality Single-file Implementations of Deep Reinforcement Learning Algorithms } ,
journal = { Journal of Machine Learning Research } ,
year = { 2022 } ,
volume = { 23 } ,
number = { 274 } ,
pages = { 1--18 } ,
url = { http://jmlr.org/papers/v23/21-1342.html }
}CleanRL ist ein von der Community betriebenes Projekt und unsere Mitwirkenden führen Experimente auf einer Vielzahl von Hardware durch.


