3DDFA
1.0.0
Von Jianzhu Guo.

[Aktualisierungen]
2022.5.14 : Empfehlen Sie eine Python-Implementierung der Gesichtsprofilierung: face_pose_augmentation.2020.8.30 : Das vorab trainierte Modell und der Code von ECCV-20 werden auf 3DDFA_V2 veröffentlicht, das Urheberrecht wird von Jianzhu Guo und der CBSR-Gruppe erklärt.2020.8.2 : Aktualisieren Sie einen einfachen C++-Port dieses Projekts.2020.7.3 : Die erweiterte Arbeit Towards Fast, Accurate and Stable 3D Dense Face Alignment wird vom ECCV 2020 akzeptiert. Weitere Details finden Sie auf meiner Seite.2019.9.15 : Einige Updates, Einzelheiten finden Sie in den Commits.2019.6.17 : Hinzufügen einer Videodemo von zjjMaiMai.2019.5.2 : Bewertung der Inferenzgeschwindigkeit auf der CPU mit PyTorch v1.1.0, siehe hier und speed_cpu.py.2019.4.27 : Eine einfache Render-Pipeline, die mit ~25 ms/Frame (720p) läuft. Weitere Details finden Sie unter „rendering.py“.2019.4.24 : Bereitstellung des Demogebäudes von Obama, weitere Einzelheiten finden Sie unter demo@obama/readme.md.2019.3.28 : Einige Aktualisierungen.2018.12.23 : Mehrere Funktionen hinzufügen: Tiefenbildschätzung, PNCC, PAF-Funktion und Obj-Serialisierung. Weitere Informationen finden Sie unter den Optionen dump_depth , dump_pncc , dump_paf und dump_obj .2018.12.2 : Unterstützt das beschneiden von Gesichtern ohne Orientierungspunkte, siehe Option dlib_landmark .2018.12.1 : Code verfeinern und Posenschätzungsfunktion hinzufügen, weitere Details finden Sie unter utils/estimate_pose.py.2018.11.17 : Code verfeinern und 3D-Scheitelpunkt dem ursprünglichen Bildraum zuordnen.2018.11.11 : End-to-End-Inferenzpipeline aktualisiert: 3D-Gesichtsform und 68 Orientierungspunkte anhand eines beliebigen Bildes ableiten/serialisieren. Weitere Einzelheiten finden Sie in der Datei readme.md unten.2018.10.4 : Matlab-Face-Mesh-Rendering-Demo in Visualize hinzugefügt.2018.9.9 : Vorprozess zum Zuschneiden von Gesichtern im Benchmark hinzugefügt.[Alles]
Dieses Repo enthält die verbesserte Pytorch-Version des Artikels: Face Alignment in Full Pose Range: A 3D Total Solution. Mehrere Arbeiten, die über das Originalpapier hinausgehen, werden hinzugefügt, darunter das Echtzeittraining und Trainingsstrategien. Daher ist dieses Repo eine verbesserte Version des Originalwerks. Bisher veröffentlicht dieses Repo die vorab trainierten Pytorch-Modelle der ersten Stufe der MobileNet-V1-Struktur, den vorverarbeiteten Trainings- und Testdatensatz und die Codebasis. Beachten Sie, dass die Inferenzzeit auf der GeForce GTX TITAN X etwa 0,27 ms pro Bild (Eingabestapel mit 128 Bildern als Eingabestapel) beträgt.
Dieses Repo wird in meiner Freizeit ständig aktualisiert, und alle wichtigen Probleme und PR sind willkommen.
Nachfolgend werden mehrere Ergebnisse zum ALFW-2000-Datensatz (abgeleitet aus dem Modell „phase1_wpdc_vdc.pth.tar “) angezeigt.
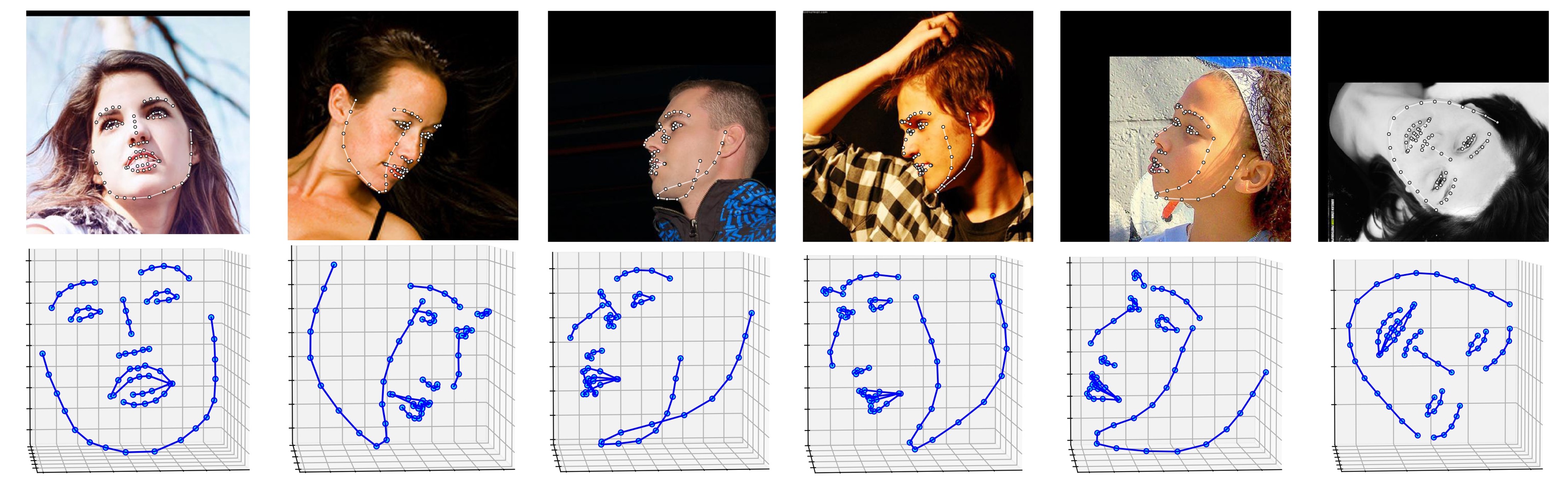





# installation structions
sudo pip3 install torch torchvision # for cpu version. more option to see https://pytorch.org
sudo pip3 install numpy scipy matplotlib
sudo pip3 install dlib==19.5.0 # 19.15+ version may cause conflict with pytorch in Linux, this may take several minutes. If 19.5 version raises errors, you may try 19.15+ version.
sudo pip3 install opencv-python
sudo pip3 install cython
Darüber hinaus empfehle ich aufgrund des besseren Designs dringend, Python3.6+ anstelle der älteren Version zu verwenden.
Klonen Sie dieses Repo (dies kann einige Zeit dauern, da es etwas groß ist)
git clone https://github.com/cleardusk/3DDFA.git # or [email protected]:cleardusk/3DDFA.git
cd 3DDFA
Laden Sie dann das vorab trainierte Dlib-Markenmodell in Google Drive oder Baidu Yun herunter und legen Sie es im models ab. (Um die Größe dieses Repos zu reduzieren, entferne ich einige große Binärdateien, einschließlich dieses Modells, Sie sollten es also herunterladen : ) )
Cython-Modul erstellen (nur eine Zeile zum Erstellen)
cd utils/cython
python3 setup.py build_ext -i
Dies dient der Beschleunigung der Tiefenschätzung und des PNCC-Renderings, da Python in der for-Schleife zu langsam ist.
Führen Sie main.py mit einem beliebigen Bild als Eingabe aus
python3 main.py -f samples/test1.jpg
Wenn Sie dieses Ausgabeprotokoll im Terminal sehen können, haben Sie es erfolgreich ausgeführt.
Dump tp samples/test1_0.ply
Save 68 3d landmarks to samples/test1_0.txt
Dump obj with sampled texture to samples/test1_0.obj
Dump tp samples/test1_1.ply
Save 68 3d landmarks to samples/test1_1.txt
Dump obj with sampled texture to samples/test1_1.obj
Dump to samples/test1_pose.jpg
Dump to samples/test1_depth.png
Dump to samples/test1_pncc.png
Save visualization result to samples/test1_3DDFA.jpg
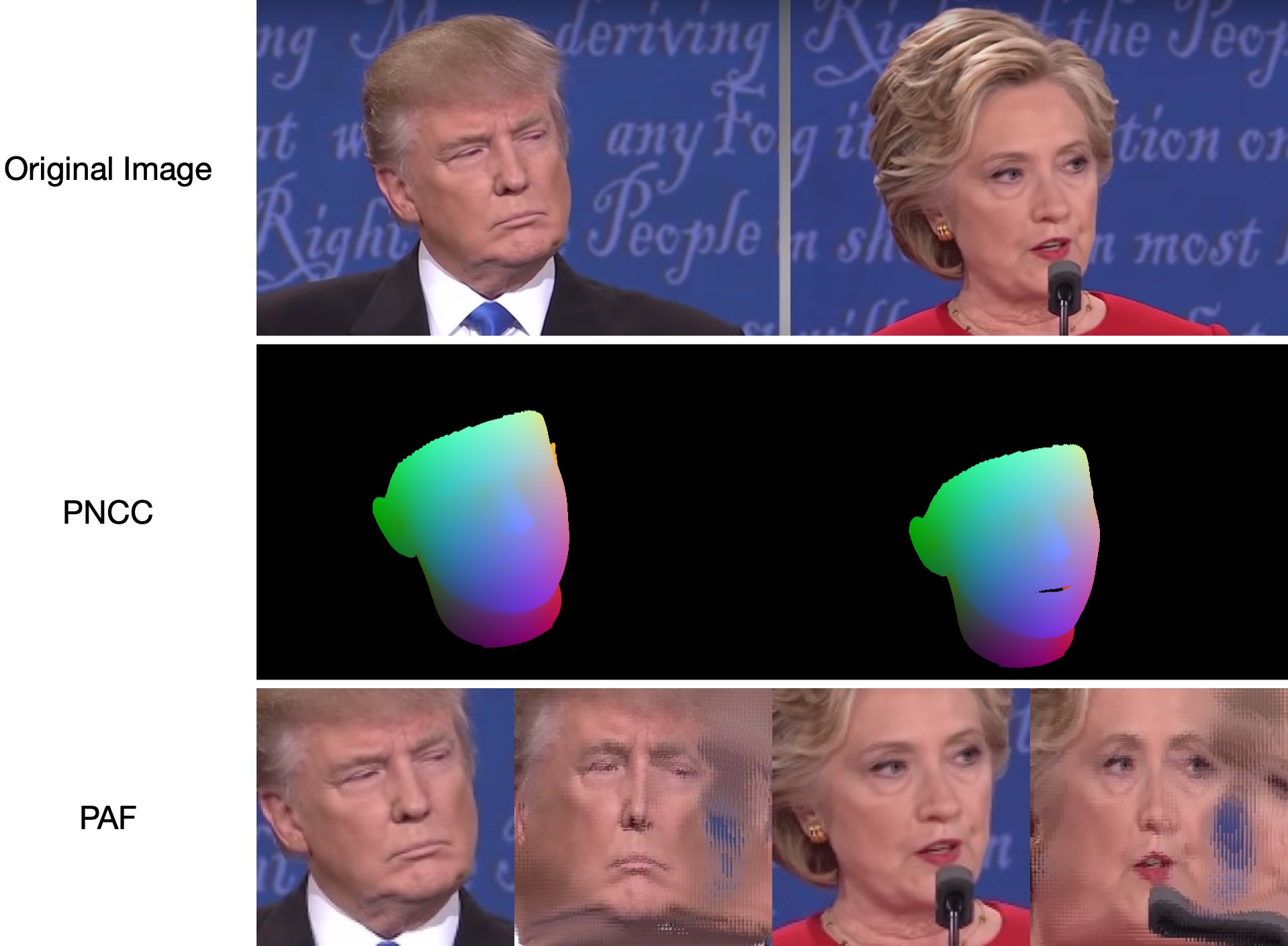
Da test1.jpg zwei Gesichter hat, werden zwei .ply und .obj Dateien vorhergesagt (können von Meshlab oder Microsoft 3D Builder gerendert werden). Tiefe, PNCC, PAF und Posenschätzung sind standardmäßig alle auf „true“ gesetzt. Bitte führen Sie python3 main.py -h aus oder überprüfen Sie den Code für weitere Details.
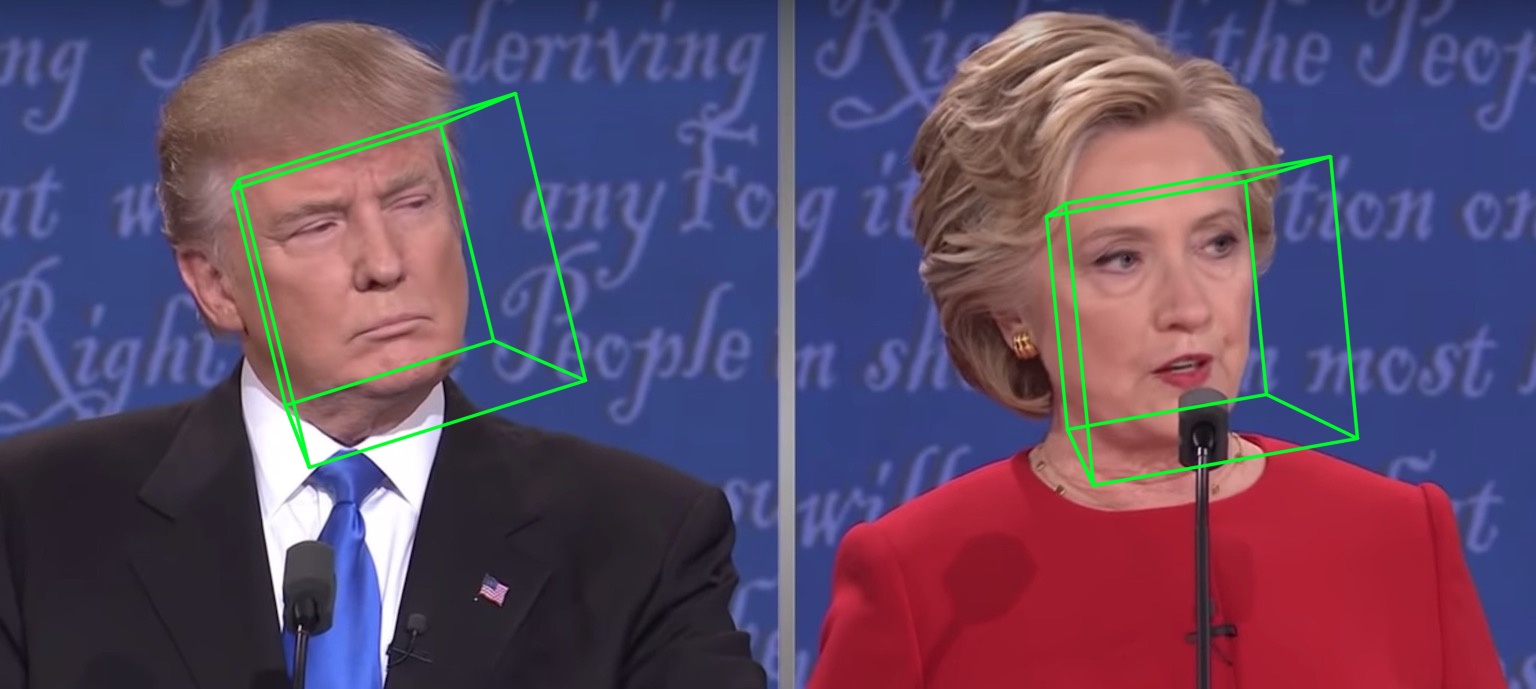
Die Ergebnisse der Visualisierung von 68 Orientierungspunkten samples/test1_3DDFA.jpg und Posenschätzungsergebnisse samples/test1_pose.jpg sind unten dargestellt:

Zusätzliches Beispiel
python3 ./main.py -f samples/emma_input.jpg --bbox_init=two --dlib_bbox=false
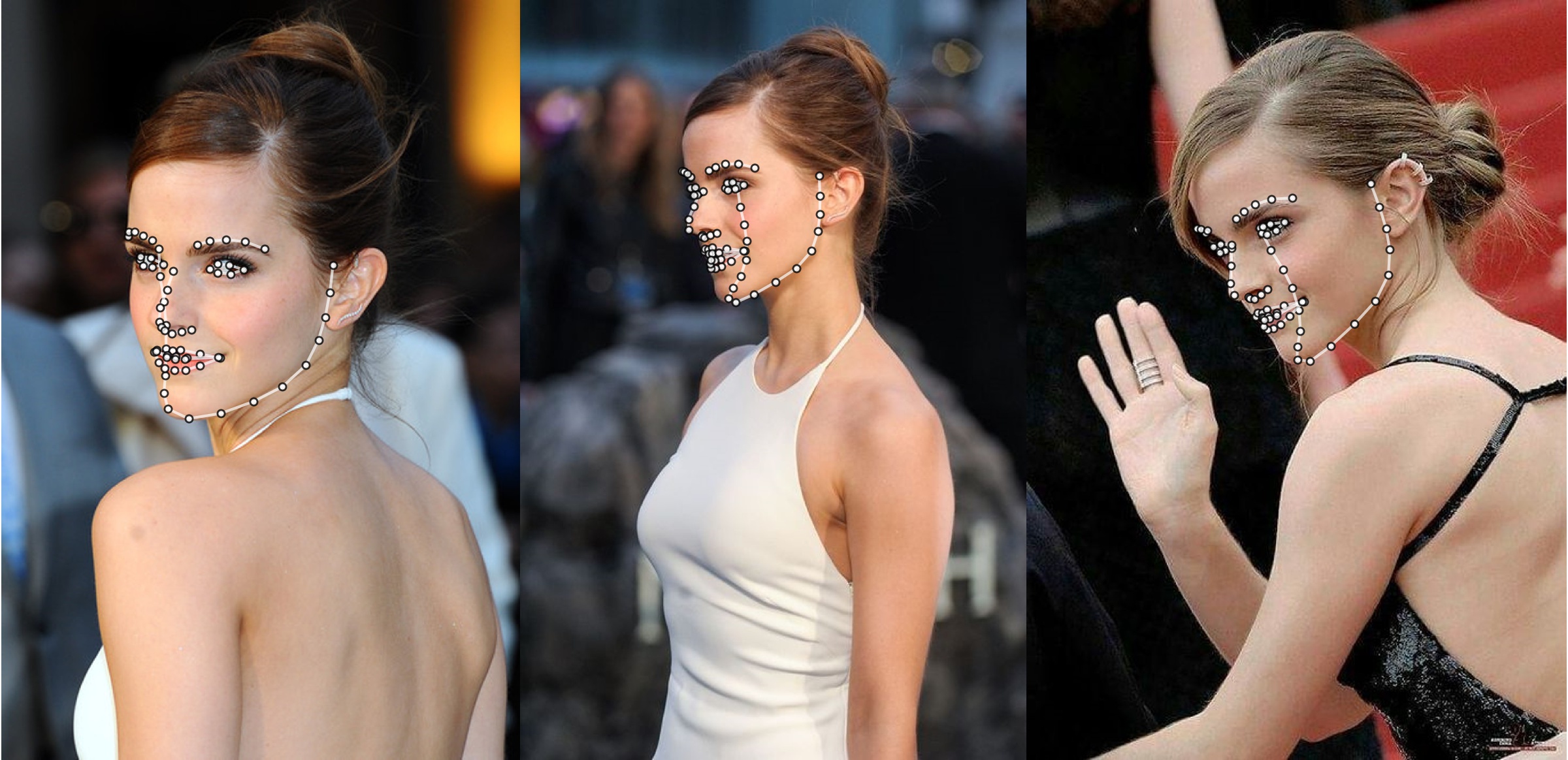
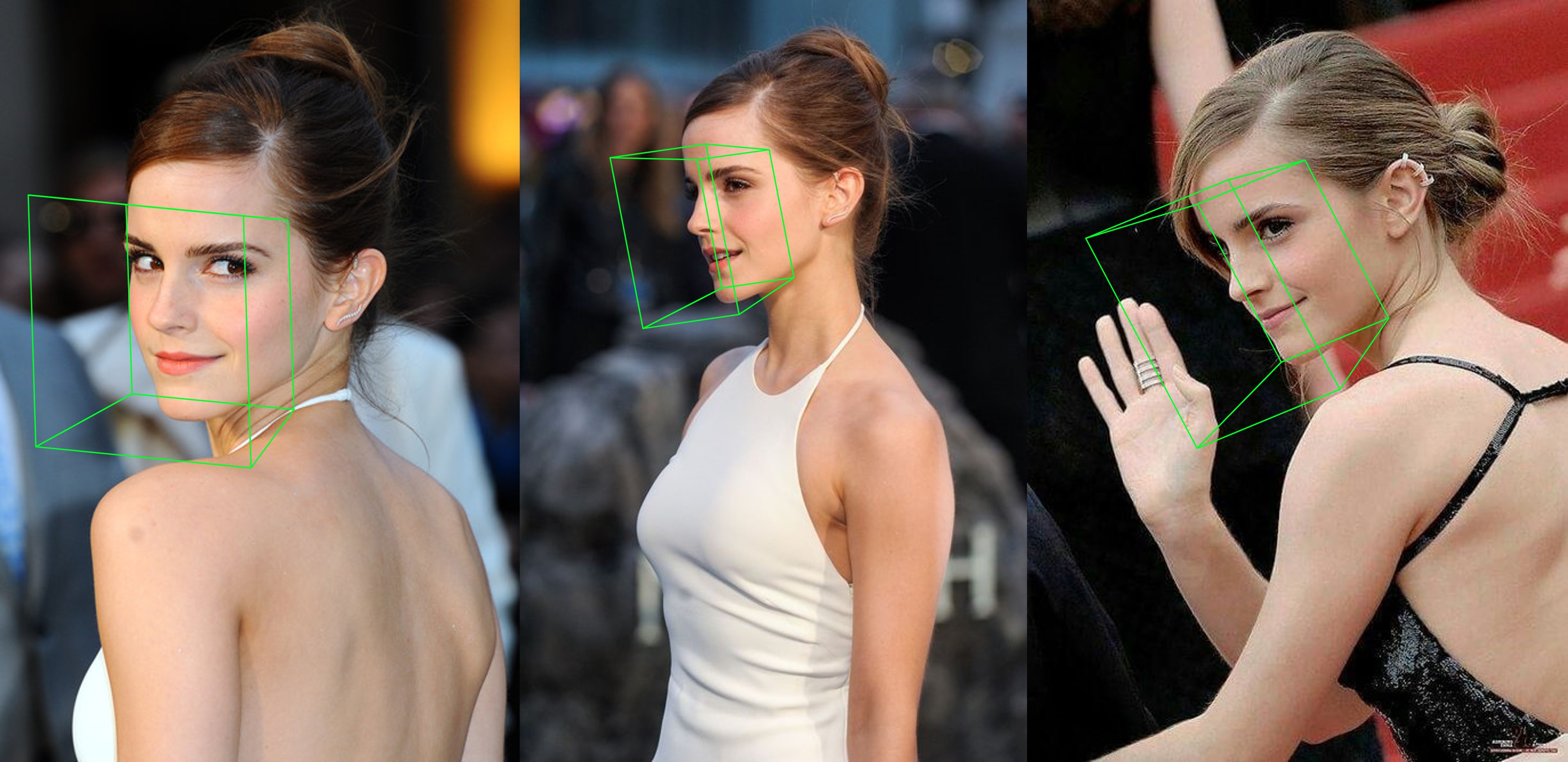
Lauf einfach
python3 speed_cpu.py
Auf meinem MBP (i5-8259U CPU bei 2,30 GHz auf 13-Zoll MacBook Pro), basierend auf PyTorch v1.1.0 , mit einem einzigen Eingang, ist die laufende Ausgabe:
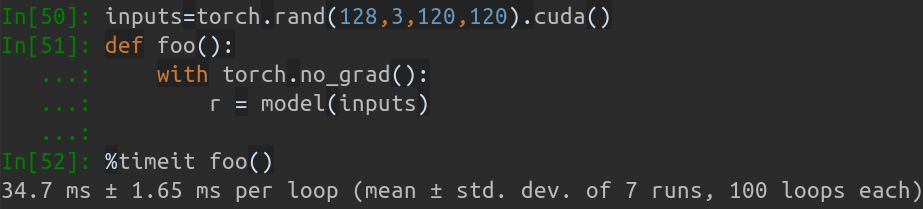
Inference speed: 14.50±0.11 ms
Wenn die Eingabestapelgröße 128 beträgt, beträgt die gesamte Inferenzzeit von MobileNet-V1 etwa 34,7 ms. Die Durchschnittsgeschwindigkeit beträgt etwa 0,27 ms/Bild .
Die Trainingsskripte liegen im training . Die zugehörigen Ressourcen finden Sie in der folgenden Tabelle.
| Daten | Download-Link | Beschreibung |
|---|---|---|
| train.configs | BaiduYun oder Google Drive, 217M | Das Verzeichnis mit 3DMM-Parametern und Dateilisten des Trainingsdatensatzes |
| train_aug_120x120.zip | BaiduYun oder Google Drive, 2,15G | Die zugeschnittenen Bilder des Augmentationstrainingsdatensatzes |
| test.data.zip | BaiduYun oder Google Drive, 151 Mio | Die zugeschnittenen Bilder des AFLW- und ALFW-2000-3D-Testsatzes |
Gehen Sie nach der Vorbereitung des Trainingsdatensatzes und der Konfigurationsdateien in training und führen Sie die zu trainierenden Bash-Skripte aus. train_wpdc.sh , train_vdc.sh und train_pdc.sh sind Beispiele für Trainingsskripte. Nachdem Sie die Trainings- und Testsätze konfiguriert haben, führen Sie sie einfach zum Training aus. Nehmen Sie train_wpdc.sh als Beispiel wie folgt:
#!/usr/bin/env bash
LOG_ALIAS=$1
LOG_DIR="logs"
mkdir -p ${LOG_DIR}
LOG_FILE="${LOG_DIR}/${LOG_ALIAS}_`date +'%Y-%m-%d_%H:%M.%S'`.log"
#echo $LOG_FILE
./train.py --arch="mobilenet_1"
--start-epoch=1
--loss=wpdc
--snapshot="snapshot/phase1_wpdc"
--param-fp-train='../train.configs/param_all_norm.pkl'
--param-fp-val='../train.configs/param_all_norm_val.pkl'
--warmup=5
--opt-style=resample
--resample-num=132
--batch-size=512
--base-lr=0.02
--epochs=50
--milestones=30,40
--print-freq=50
--devices-id=0,1
--workers=8
--filelists-train="../train.configs/train_aug_120x120.list.train"
--filelists-val="../train.configs/train_aug_120x120.list.val"
--root="/path/to//train_aug_120x120"
--log-file="${LOG_FILE}"
Die spezifischen Trainingsparameter werden alle in Bash-Skripten dargestellt, einschließlich Lernrate, Mini-Batch-Größe, Epochen usw.
Zuerst sollten Sie das zugeschnittene Testset ALFW und ALFW-2000-3D in test.data.zip herunterladen, es dann entpacken und im Stammverzeichnis ablegen. Führen Sie als Nächstes den Benchmark-Code aus, indem Sie den trainierten Modellpfad bereitstellen. Ich habe bereits fünf vorab trainierte Modelle im models bereitgestellt (siehe Tabelle unten). Diese Modelle werden in der ersten Stufe mit unterschiedlichen Verlusten trainiert. Aufgrund der hohen Effizienz der MobileNet-V1-Struktur beträgt die Modellgröße etwa 13 MB.
python3 ./benchmark.py -c models/phase1_wpdc_vdc.pth.tar
Die Leistungen vorab trainierter Modelle sind unten aufgeführt. In der ersten Stufe ist die Wirksamkeit verschiedener Verluste in der Reihenfolge: WPDC > VDC > PDC. Während die Strategie, VDC zur Feinabstimmung von WPDC zu verwenden, das beste Ergebnis erzielt.
| Modell | AFLW (21 Punkte) | AFLW 2000-3D (68 Punkte) | Download-Link |
|---|---|---|---|
| Phase1_pdc.pth.tar | 6,956 ± 0,981 | 5,644 ± 1,323 | Baidu Yun oder Google Drive |
| Phase1_vdc.pth.tar | 6,717 ± 0,924 | 5,030 ± 1,044 | Baidu Yun oder Google Drive |
| Phase1_wpdc.pth.tar | 6,348 ± 0,929 | 4,759 ± 0,996 | Baidu Yun oder Google Drive |
| Phase1_wpdc_vdc.pth.tar | 5,401 ± 0,754 | 4,252 ± 0,976 | In diesem Repo. |
Glauben Sie mir, dass das Framework dieses Repos eine bessere Leistung als PRNet erzielen kann, ohne das Rechenbudget zu erhöhen. Zugehörige Arbeiten werden derzeit überprüft und der Code wird nach Annahme veröffentlicht.
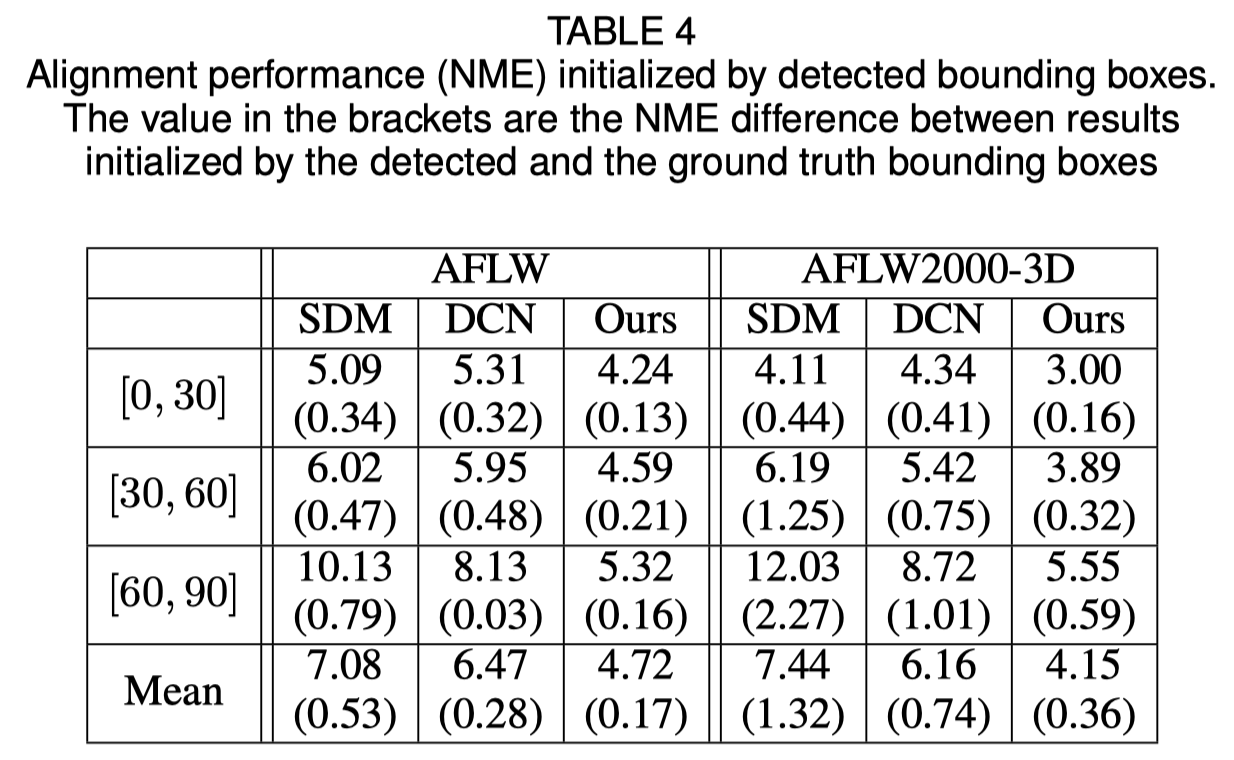
Initialisierung des Gesichtsbegrenzungsrahmens
Das Originalpapier zeigt, dass die Verwendung der erkannten Begrenzungsbox anstelle der Ground-Truth-Box zu einem leichten Leistungsabfall führt. Daher ist die aktuelle Gesichtsbeschneidungsmethode die robusteste. Die quantitativen Ergebnisse sind in der folgenden Tabelle aufgeführt.
Gesichtsrekonstruktion
Die Textur des nicht sichtbaren Bereichs ist aufgrund der Selbstokklusion verzerrt, daher kann der nicht sichtbare Gesichtsbereich seltsam (ein wenig schrecklich) erscheinen.
Informationen zum Beschneiden von Form- und Ausdrucksparametern
Das Beschneiden der Parameter beschleunigt das Training und die Rekonstruktion, beeinträchtigt jedoch die Genauigkeit, insbesondere bei Details wie dem Schließen der Augen. Unten ist ein Bild mit den Parameterdimensionen 40+10, 60+29 und 199+29 (das Original). Im Vergleich zur Form hat das Ausschneiden von Ausdrücken einen größeren Einfluss auf die Rekonstruktionsgenauigkeit, wenn Emotionen im Spiel sind. Daher können Sie einen Kompromiss zwischen Geschwindigkeit/Parametergröße und Genauigkeit wählen. Eine Empfehlung für den Clipping-Kompromiss ist 60+29.

Vielen Dank für Ihr Interesse an diesem Repo. Wenn Ihre Arbeit oder Forschung von diesem Repo profitiert, markieren Sie es?
Willkommen, um mich auf meine Arbeiten im Zusammenhang mit 3D-Gesichtern zu konzentrieren: MeGlass und Face Anti-Spoofing.
Wenn Ihre Arbeit von diesem Repo profitiert, geben Sie bitte unten drei Startnummern an.
@misc{3ddfa_cleardusk,
author = {Guo, Jianzhu and Zhu, Xiangyu and Lei, Zhen},
title = {3DDFA},
howpublished = {url{https://github.com/cleardusk/3DDFA}},
year = {2018}
}
@inproceedings{guo2020towards,
title= {Towards Fast, Accurate and Stable 3D Dense Face Alignment},
author= {Guo, Jianzhu and Zhu, Xiangyu and Yang, Yang and Yang, Fan and Lei, Zhen and Li, Stan Z},
booktitle= {Proceedings of the European Conference on Computer Vision (ECCV)},
year= {2020}
}
@article{zhu2017face,
title= {Face alignment in full pose range: A 3d total solution},
author= {Zhu, Xiangyu and Liu, Xiaoming and Lei, Zhen and Li, Stan Z},
journal= {IEEE transactions on pattern analysis and machine intelligence},
year= {2017},
publisher= {IEEE}
}
Jianzhu Guo (郭建珠) [Homepage, Google Scholar]: [email protected] oder [email protected] .


