genai_robotics
1.0.0
Dieses Repository enthält einen experimentellen, datenschutzbewussten Aufbau zur Nutzung generativer KI-Methoden in der Robotiksteuerung. Mit der hier vorgestellten Lösung kann ein Benutzer Aktionen per Stimme frei definieren, die in Pläne übersetzt werden, die ein Roboterstaubsauger in einer von einer Kamera beobachteten Open-World-Umgebung ausführen kann.
Die wesentlichen Vorteile der hier vorgestellten Methoden sind:
Das System wurde in einem dreitägigen Hackathon als Lernübung und Proof-of-Concept entwickelt, dass moderne KI-Tools die Entwicklungszeit für Robotik-Steuerungslösungen erheblich verkürzen können.
Um alle Funktionen dieses Repositorys nutzen zu können, sollten Sie Folgendes haben:
Führen Sie zunächst die folgenden Schritte aus:
requirements.txt in einer Python-Umgebung (getestet mit Python 3.11).src/config.template.toml in config.toml um. Für alle folgenden Schritte fügen Sie die erworbenen Anmeldeinformationen in config.toml einpython-roborock -Bibliothek.src/run.py aus, um den Workflow auszuführen. Der beste Weg, um zu verstehen, was dieses Repository im Detail macht und wie die Elemente interagieren, ist ein Architekturdiagramm:
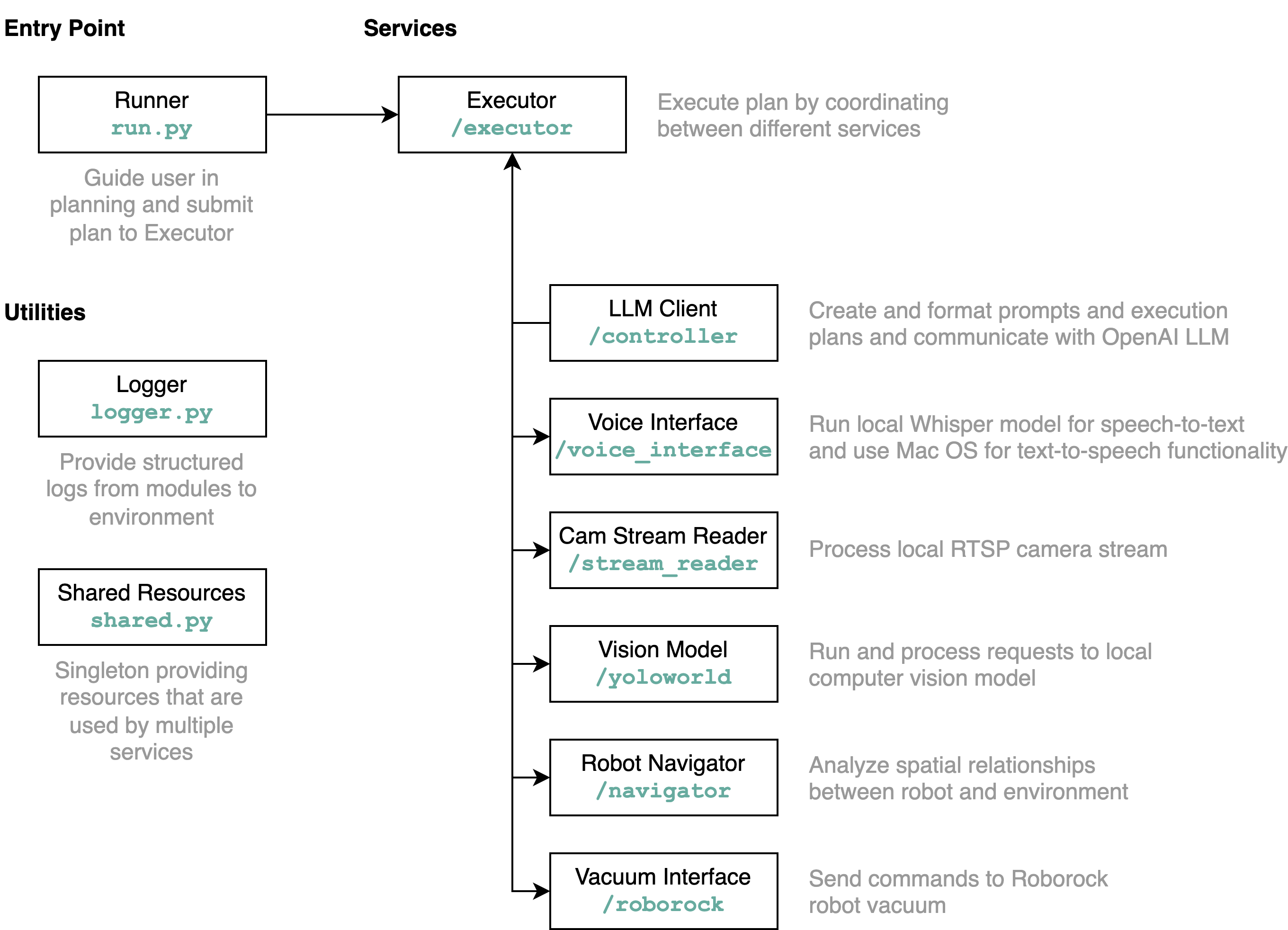
Wenn Sie die Datei run.py wie oben beschrieben ausführen, passiert Folgendes und wie es funktioniert:
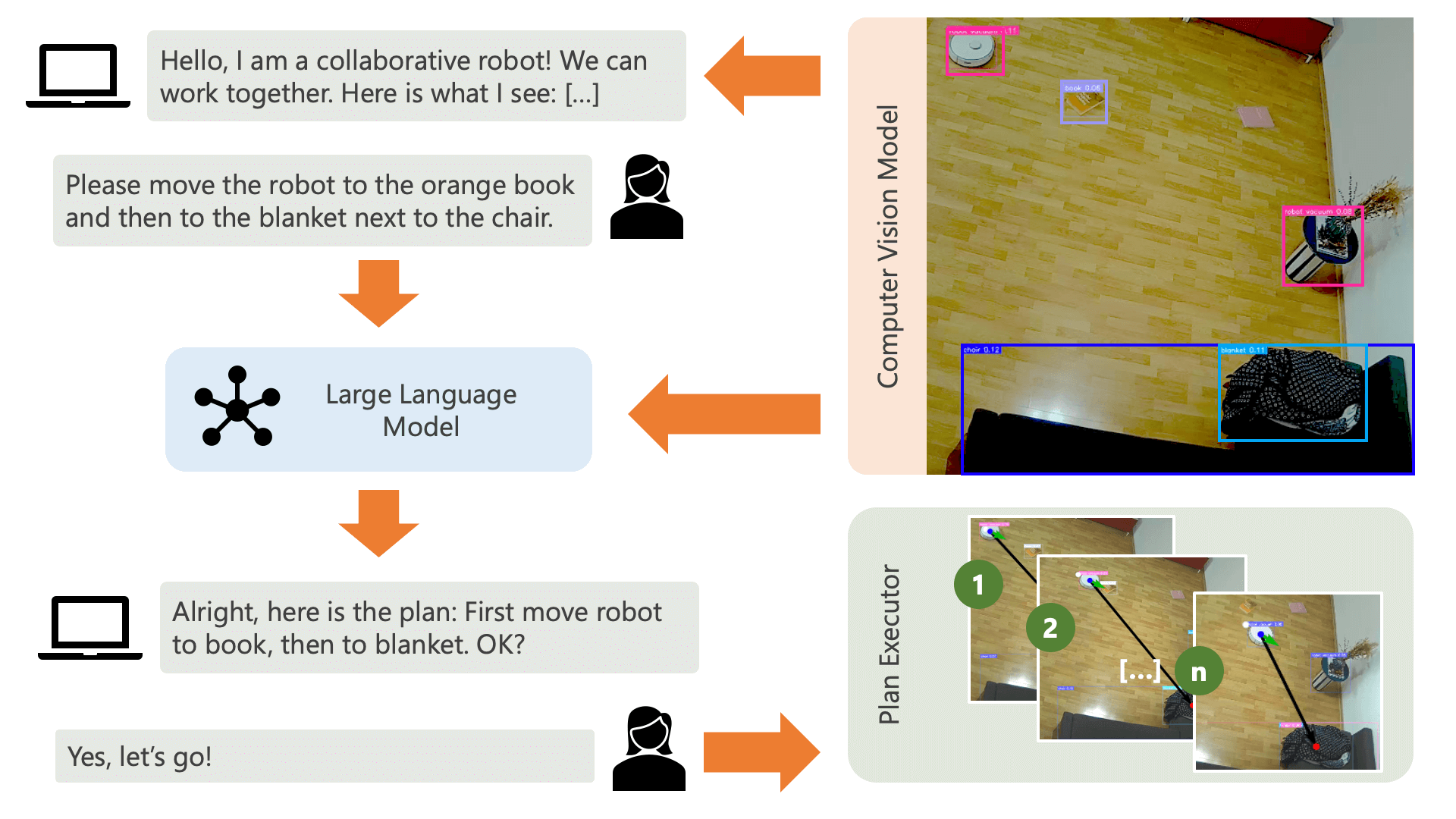
Das System begrüßt den Benutzer mit einer Audionachricht und erwartet von ihm, dass er dem System mitteilt, was er tun möchte. Ein Benutzer möchte beispielsweise, dass der Roboter einen Kaffee von einer Person aufnimmt, die auf einem gelben Stuhl sitzt, und ihn zu einer anderen Person transportiert, die auf einem schwarzen Sofa sitzt. Das System würde dann einen Plan zur Ausführung dieser Aktionen erstellen.
Was braucht das System, um zu verstehen, wie es das erreichen kann, was der Benutzer tun möchte? Das System muss sich seiner Umgebung und der Aktionen bewusst sein, die in dieser Umgebung ausgeführt werden können. Hier verwenden wir ein Computer-Vision-Modell mit Objekterkennung, um dem System Informationen über die Umgebung bereitzustellen. Der Staubsauger selbst kann drei einfache Aktionen ausführen: Vorwärts bewegen, umdrehen und nichts tun. Eine weitere Aktion in der Umgebung wartet darauf, dass der Benutzer eine bestimmte Aktion ausführt.
Um Verwirrung auf Nutzerseite zu vermeiden, ist es wichtig, dass der Nutzer weiß, wie die KI seine Umgebung wahrnimmt. Wenn beispielsweise ein Objekt vom Computer-Vision-Modell nicht erkannt wird, kann die KI es nicht in einen Plan einbeziehen. Es ist auch wichtig, dass sich der Benutzer darüber im Klaren ist, dass hinsichtlich der Erkennung der Modelle Unsicherheit besteht. Unter Verwendung des großen Sprachmodells GPT-4o von OpenAI mit der Beschreibungsaufforderung erstellt das System eine Erklärung seiner Umgebung und liest sie dem Benutzer vor, bevor er den Benutzer fragt, was das System tun soll.
Anhand der Umgebungsinformationen und der Benutzereingaben hinsichtlich dessen, was sie tun möchten, kann das System dann einen Plan erstellen. Hier bitten wir das LLM, einen Plan zu erstellen, der die Eingaben des Benutzers und die Beschreibung der Umgebung berücksichtigt. Sie finden die Eingabeaufforderungsvorlage im controller Verzeichnis. Der spannende Trick dabei ist, dass das LLM seine Umgebung nur durch zwei Tabellen wahrnimmt, die aus den Ausgaben des Computer-Vision-Modells generiert werden. Hier ist ein Beispiel:
Item locations:
| id | label | position | confidence | color_rgb |
|-----:|:-------------|:----------------|-------------:|:----------------|
| 0 | robot vacuum | (122.0, 140.0) | 0.23 | [205, 206, 210] |
| 1 | blanket | (1697.0, 923.0) | 0.59 | [60, 72, 90] |
| 2 | chair | (532.5, 210.0) | 0.39 | [177, 177, 171] |
| 3 | chair | (160.0, 521.5) | 0.24 | [99, 99, 98] |
| 4 | book | (1216.5, 601.0) | 0.2 | [137, 141, 155] |
Distances:
| id | 0 | 1 | 2 | 3 | 4 |
|-----:|-----:|-----:|-----:|-----:|-----:|
| 0 | 0 | 1758 | 416 | 383 | 1187 |
| 1 | 1758 | 0 | 1365 | 1588 | 578 |
| 2 | 416 | 1365 | 0 | 485 | 787 |
| 3 | 383 | 1588 | 485 | 0 | 1059 |
| 4 | 1187 | 578 | 787 | 1059 | 0 |
Sobald das LLM die Planungsaufforderung verarbeitet hat, gibt es zwei Dinge aus: Begründung und den Plan. Bevor das System mit der Ausführung des Plans fortfährt, generiert es mithilfe der Erklärungsaufforderung eine kurze Zusammenfassung des Plans, um vom Benutzer eine Bestätigung zu erhalten, dass der Plan seinen Anforderungen entspricht. Dies steht im Sinne eines „Human-in-the-Loop“-Ansatzes, bei dem wir davon ausgehen, dass Menschen in einer realen, offenen, physischen Umgebung möglicherweise durch die Aktionen der KI geschädigt werden können, daher ist es sinnvoll, nach menschlichem Handeln zu fragen Feedback, bevor die KI mit der Ausführung eines Plans fortfährt, den sie sich selbst ausgedacht hat.
Sobald der Benutzer bestätigt hat, fährt das System mit der Ausführung des Plans fort. Ein solcher Plan, wie er vom LLM erstellt wird, könnte wie folgt aussehen:
[
{ "action" : " MOVE " , "location" : [ 1216.5 , 601.0 ]},
{ "action" : " WAIT_UNTIL " , "task_fulfilled" : " Please place the book on the robot vacuum so that the robot can transport it to the chair. " },
{ "action" : " MOVE " , "location" : [ 532.5 , 210.0 ]},
{ "action" : " END " }
] Mithilfe des executor führt das System den Plan Schritt für Schritt aus. Um die erforderliche Rüstzeit zu reduzieren, folgt die Robotersteuerung einem einfachen, ungenauen, aber effektiven Algorithmus:
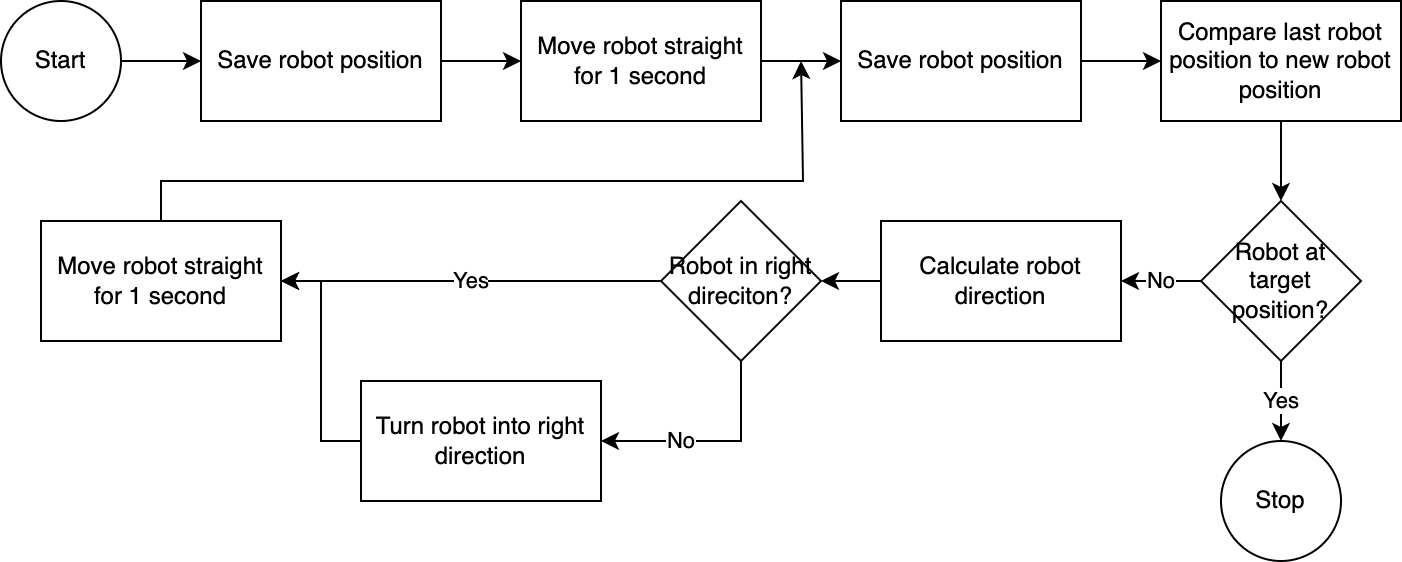
Das Computer-Vision-System ermittelt die Position des Roboters. Durch Code im navigator wird die Roboterposition relativ zu seiner Zielposition und relativ zu seiner letzten bekannten Position analysiert und verglichen. Dieser Ansatz ist unvollkommen, da die Position und die Objektivverzerrung der Kamera nicht berücksichtigt werden. Die mit diesem Ansatz gemessenen Winkel sind ungenau. Da das System jedoch iterativ ist, werden Fehler häufig kompensiert. Allerdings ist zu beachten, dass dies auf Kosten der Geschwindigkeit geht. Das System ist langsam, da es Zeit braucht, das Bild zu analysieren, einen Pfad zu berechnen und den Roboter über die nächsten Schritte zu informieren.
Sobald der Roboter seine Zielposition erreicht hat, fährt der Ausführende mit dem nächsten Schritt des Plans fort. Bei Aktionen, bei denen Benutzereingaben erforderlich sind, nutzt der Ausführende die Text-to-Speech- und Speech-to-Text-Funktionalität, um mit dem Benutzer zu interagieren.
In diesem System verwenden wir hauptsächlich Dienste, die auf einem lokalen Computer oder Netzwerk ausgeführt werden. Die Ausnahme ist GPT-4o. Wir senden Textdaten über das Internet an das OpenAI-Modell. Die Textdaten umfassen transkribierte Benutzereingaben und eine Tabelle erkannter Objekte. Der einzige Grund, warum wir hier GPT-4o verwenden, besteht darin, dass es sich um eines der besten Modelle handelt, die zum Zeitpunkt des Hackathons verfügbar waren. Wir könnten auch ein lokales LLM ausführen und dann vollständig ohne Verbindung zum Internet arbeiten, wodurch die Privatsphäre im gesamten Datenfluss gewahrt bleibt Operationen.
Das in diesem Repository enthaltene Computer-Vision-Modell wurde vom YOLO-World-Modell in einem HuggingFace-Raum mit der folgenden Eingabeaufforderung erstellt: chair, book, candle, blanket, vase, bulb, robot vacuum, mug, glass, human . Wenn Sie weitere Objekte erkennen möchten, passen Sie bitte die Eingabeaufforderung an und laden Sie über diesen Bereich ein ONNX-Modell herunter. Anschließend können Sie das Modell im Verzeichnis src/yoloworld/models/rev0 ersetzen.
Beachten Sie, dass Sie zum korrekten Extrahieren des Modells die Parameter „Maximale Anzahl an Boxen“ und „Score-Schwellenwert“ im HuggingFace-Bereich manuell ändern müssen, bevor Sie das Modell exportieren.
Auf der YOLO-World-Website können Sie mehr über das spannende YOLO-World-Modell erfahren, das auf den jüngsten Fortschritten in der Vision-Language-Modellierung aufbaut.
Dieses Projekt wird unter der MIT-Lizenz veröffentlicht.
Dieses Repository wird nicht aktiv überwacht und es besteht keine Absicht, es zu erweitern – es handelt sich in erster Linie um eine Lernübung. Wenn Sie sich jedoch inspiriert fühlen, können Sie gerne zum Projekt beitragen, indem Sie ein GitHub-Issue oder eine Pull-Anfrage eröffnen.


