full stack on prem cv mlops
1.0.0
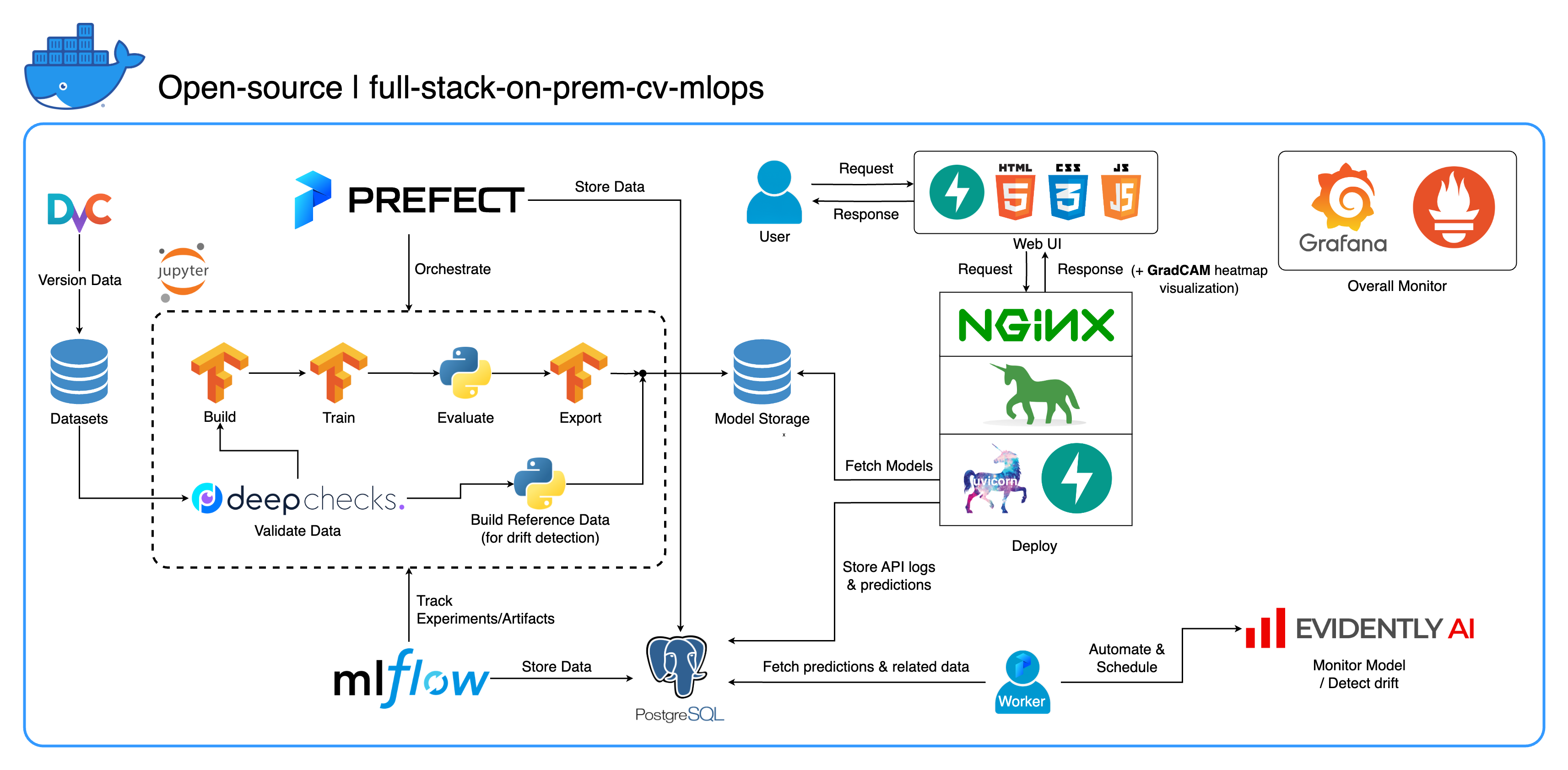
Willkommen in unserem umfassenden lokalen MLOps-Ökosystem, das speziell für Computer Vision-Aufgaben entwickelt wurde und sich vor allem auf die Bildklassifizierung konzentriert. Dieses Repository stattet Sie mit allem aus, was Sie brauchen, von einem Entwicklungsarbeitsbereich in Jupyter Lab/Notebook bis hin zu Diensten auf Produktionsebene. Das Beste daran? Es sind nur „1 Konfiguration und 1 Befehl“ erforderlich, um das gesamte System vom Erstellen des Modells bis zur Bereitstellung auszuführen! Wir haben zahlreiche Best Practices integriert, um Skalierbarkeit und Zuverlässigkeit bei gleichzeitiger Wahrung der Flexibilität zu gewährleisten. Während sich unser Hauptanwendungsfall um die Bildklassifizierung dreht, lässt sich unsere Projektstruktur problemlos an eine Vielzahl von ML/DL-Entwicklungen anpassen, sogar beim Übergang von On-Premises zur Cloud!
Ein weiteres Ziel besteht darin, zu zeigen, wie alle diese Tools integriert und in einem vollständigen System zusammenarbeiten können. Wenn Sie an bestimmten Komponenten oder Werkzeugen interessiert sind, können Sie gerne auswählen, was den Anforderungen Ihres Projekts entspricht.
Das gesamte System ist in einer einzigen Docker Compose-Datei containerisiert. Um es einzurichten, müssen Sie lediglich docker-compose up ausführen! Da es sich um ein vollständig vor Ort installiertes System handelt, ist kein Cloud-Konto erforderlich, und die Nutzung des gesamten Systems kostet Sie keinen Cent !
Wir empfehlen dringend, sich die Demovideos im Abschnitt „Demovideos“ anzusehen, um einen umfassenden Überblick zu erhalten und zu verstehen, wie Sie dieses System auf Ihre Projekte anwenden können. Diese Videos enthalten wichtige Details, die möglicherweise zu lang und nicht klar genug sind, um hier behandelt zu werden.
Demo: https://youtu.be/NKil4uzmmQc
Ausführliche technische Anleitung: https://youtu.be/l1S5tHuGBA8
Ressourcen im Video:
Um dieses Repository nutzen zu können, benötigen Sie lediglich Docker. Als Referenz verwenden wir Docker Version 24.0.6, Build ed223bc und Docker Compose Version v2.21.0-desktop.1 auf Mac M1.
Wir haben in diesem Projekt mehrere Best Practices implementiert:
tf.data für TensorFlowimgaug lib für mehr Flexibilität bei den Erweiterungsoptionen als Kernfunktionen von TensorFlowos.env für wichtige oder Service-Level-Konfigurationenlogging statt print.env für Variablen in docker-compose.ymldefault.conf.template für Nginx, um Umgebungsvariablen in der Nginx-Konfiguration elegant anzuwenden (neue Funktion in Nginx 1.19)Die meisten Ports können in der .env-Datei im Stammverzeichnis dieses Repositorys angepasst werden. Hier sind die Standardeinstellungen:
123456789 )[email protected] , pw: SuperSecurePwdHere )admin , pw: admin ) Sie müssen die Zeilen platform: linux/arm64 in docker-compose.yml kommentieren, wenn Sie keinen ARM-basierten Computer verwenden (wir verwenden Mac M1 für die Entwicklung). Sonst wird dieses System nicht funktionieren.
--recurse-submodules in Ihrem Befehl: git clone --recurse-submodules https://github.com/jomariya23156/full-stack-on-prem-cv-mlopsdeploy unter jupyter service“ in docker-compose.yml auskommentieren und das Basis-Image in services/jupyter/Dockerfile von ubuntu:18.04 in nvidia/cuda:11.4.3-cudnn8-devel-ubuntu20.04 ändern nvidia/cuda:11.4.3-cudnn8-devel-ubuntu20.04 (Der Text ist in der Datei vorhanden, Sie müssen ihn nur kommentieren und Kommentar entfernen), um Ihre GPU(s) zu nutzen. Möglicherweise müssen Sie auch nvidia-container-toolkit auf dem Hostcomputer installieren, damit es funktioniert. Für Windows/WSL2-Benutzer fanden wir diesen Artikel sehr hilfreich.docker-compose up oder docker-compose up -d aus, um das Terminal zu trennen.datasets/animals10-dvc und befolgen Sie die Schritte im Abschnitt „Verwendung“ . http://localhost:8888/labcd ~/workspace/docker-compose.yml konfiguriert werden) conda activate computer-viz-dlpython run_flow.py --config configs/full_flow_config.yaml austasks erstellt werdenflows -Verzeichnis erstellt werdenrun_flow.py im Stammverzeichnis des Repos aufgerufen werden.start(config) in Ihrer Flow-Datei implementieren. Diese Funktion akzeptiert die Konfiguration als Python-Dikt und ruft dann grundsätzlich den spezifischen Ablauf in dieser Datei auf.datasets -Verzeichnis befinden und alle dieselbe Verzeichnisstruktur wie die in diesem Repo haben.central_storage unter ~/ariya/ sollte mindestens zwei Unterverzeichnisse mit den Namen models und ref_data enthalten. Dieser central_storage dient der Objektspeicherung und speichert alle bereitgestellten Dateien, die in Entwicklungs- und Bereitstellungsumgebungen verwendet werden sollen. (Dies ist eines der Dinge, die Sie in Betracht ziehen könnten, auf einen Cloud-Speicherdienst umzusteigen, falls Sie ihn in der Cloud bereitstellen und skalierbarer machen möchten.)WICHTIGE Konventionen, bei denen Sie besonders vorsichtig sein sollten, wenn Sie Änderungen vornehmen möchten (da diese Dinge an verschiedene Teile des Systems gebunden sind und dort verwendet werden):
central_storage -> Darin sollten sich die Unterverzeichnisse models/ ref_data/ befinden<model_name>.yaml , <model_name>_uae , <model_name>_bbsd , <model_name>_ref_data.parquetcurrent_model_metadata_file und monitor_pool_namecomputer-viz-dl (Standardwert) mit allen erforderlichen Paketen für dieses Repository. Alle Python-Befehle/Codes sollen in diesem Jupyter ausgeführt werden.central_storage Volume fungiert als zentraler Dateispeicher, der während der gesamten Entwicklung und Bereitstellung verwendet wird. Es enthält hauptsächlich Modelldateien (einschließlich Driftdetektoren) und Referenzdaten im Parquet-Format. Am Ende des Modelltrainingsschritts werden neue Modelle hier gespeichert und der Bereitstellungsdienst ruft Modelle von diesem Speicherort ab. ( Hinweis : Dies ist ein idealer Ort zum Ersetzen durch Cloud-Speicherdienste aus Gründen der Skalierbarkeit.)model in der Konfiguration, um ein Klassifikatormodell zu erstellen. Das Modell wird mit TensorFlow erstellt und seine Architektur ist unter tasks/model.py:build_model fest codiert.dataset in der Konfiguration, um einen Datensatz für das Training vorzubereiten. In diesem Schritt wird DvC verwendet, um die Konsistenz der Daten auf der Festplatte im Vergleich zur in der Konfiguration angegebenen Version zu überprüfen. Bei Änderungen wird es programmgesteuert wieder in die angegebene Version konvertiert. Wenn Sie die Änderungen beibehalten möchten und mit dem Datensatz experimentieren, können Sie das Feld dvc_checkout in der Konfiguration auf „false“ setzen, damit DvC seine Aufgaben nicht erledigt.train “ in der Konfiguration, um einen Datenlader zu erstellen und den Trainingsprozess zu starten. Experimentinformationen und Artefakte werden mit MLflow verfolgt und protokolliert. Hinweis: Der Ergebnisbericht (in einer .html- Datei) von DeepChecks wird auch zum Trainingsexperiment auf MLflow für die Tagung hochgeladen.model in der Konfiguration.central_storage hoch (in diesem Fall wird lediglich eine Kopie an den Speicherort central_storage erstellt. Dies ist der Schritt, den Sie zum Hochladen von Dateien in den Cloud-Speicher ändern können.)model/drift_detection in der Konfiguration.central_storage hoch.central_storage hoch.central_storage abzurufen. (Dies ist ein Problem, das im Tutorial-Demovideo besprochen wird. Schauen Sie sich das Video genauer an.)current_model_metadata_file , in dem der Name der Modellmetadatendatei mit der Endung .yaml gespeichert wird, und monitor_pool_name in dem der Name des Arbeitspools für die Bereitstellung von Prefect-Workern und -Flows gespeichert wird.cd programmgesteuert in deployments/prefect-deployments und führen Sie prefect --no-prompt deploy --name {deploy_name} aus, indem Sie Eingaben aus dem Abschnitt deploy/prefect in der Konfiguration verwenden. Da in diesem Repo bereits alles dockerisiert und containerisiert ist, ist die Konvertierung des Dienstes von On-Premise zu On-Cloud ziemlich einfach. Wenn Sie mit der Entwicklung und dem Testen Ihrer Service-API fertig sind, können Sie einfach „services/dl_service“ ausgliedern, indem Sie den Container aus seiner Docker-Datei erstellen und ihn an einen Cloud-Container-Registrierungsdienst (z. B. AWS ECR) übertragen. Das ist es!
Hinweis: Es gibt ein potenzielles Problem im Servicecode, wenn Sie ihn in einer echten Produktionsumgebung verwenden möchten. Ich habe es im ausführlichen Video angesprochen und empfehle Ihnen, sich etwas Zeit zu nehmen, um sich das gesamte Video anzusehen. 
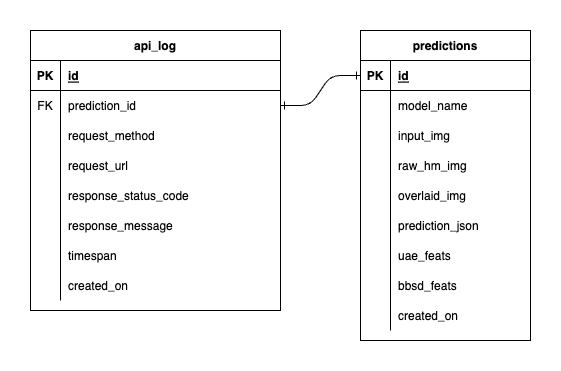
Wir haben drei Datenbanken in PostgreSQL: eine für MLflow, eine für Prefect und eine, die wir für unseren ML-Modelldienst erstellt haben. Auf die ersten beiden gehen wir nicht näher ein, da sie von diesen Tools selbst verwaltet werden. Die Datenbank für unseren ML-Modellservice ist die, die wir selbst entworfen haben.
Um eine überwältigende Komplexität zu vermeiden, haben wir es mit nur zwei Tabellen einfach gehalten. Die Beziehungen und Attribute werden im nachstehenden ERD angezeigt. Im Wesentlichen geht es uns darum, wesentliche Details über eingehende Anfragen und die Antworten unseres Dienstes zu speichern. Alle diese Tabellen werden automatisch erstellt und bearbeitet, sodass Sie sich nicht um die manuelle Einrichtung kümmern müssen.
Bemerkenswert: input_img , raw_hm_img und overlaid_img sind Base64-codierte Bilder, die als Zeichenfolgen gespeichert werden. uae_feats und bbsd_feats sind Arrays von Einbettungsfunktionen für unsere Drifterkennungsalgorithmen.
ImportError: /lib/aarch64-linux-gnu/libGLdispatch.so.0: cannot allocate memory in static TLS block , versuchen Sie es mit export LD_PRELOAD=/lib/aarch64-linux-gnu/libGLdispatch.so.0 und führen Sie dann Ihren Fehler erneut aus Skript.

