GenAI GeoGuesser
Erraten Sie den Ländernamen anhand von Treffern, die von der KI generiert wurden
Dieses Projekt ist eine andere Version des beliebten GeoGuessr-Spiels, bei dem Sie auf Google Maps an einem zufälligen Ort auf der Welt platziert werden und den Ort während eines Zeit-Countdowns erraten müssen. Hier müssen Sie den Ländernamen basierend auf multimodalen Hinweisen erraten, die von KI-Modellen generiert wurden. Sie können zwischen drei Modalitäten wählen: Text , der Ihnen eine textliche Beschreibung des Landes gibt, Bild , das Ihnen ein Bild liefert, das dem Land ähnelt, und Audio , das Ihnen eine Beschreibung gibt Ihnen eine Hörprobe mit Bezug zum Land.
Sie können eine Online-Demo dieser App in den HuggingFace-Bereichen ansehen. Diese Demo war aus Leistungsgründen darauf beschränkt, nur Bildhinweise zu generieren.
Wenn Sie mehr darüber erfahren möchten, wie dieses Projekt funktioniert und wie es erstellt wurde, lesen Sie den Artikel „Aufbau eines generativen KI-basierten GeoGuessers“.
Arbeitsablauf
- Wählen Sie die gewünschten Hinweismodalitäten aus.
- Wählen Sie die Anzahl der Hinweise für jede Modalität.
- Klicken Sie auf die Schaltfläche „Spiel starten“.
- Schauen Sie sich alle Hinweise an und geben Sie Ihre Schätzung in das Feld „Länderschätzung“ ein.
- Klicken Sie auf die Schaltfläche „Raten“.
Demo
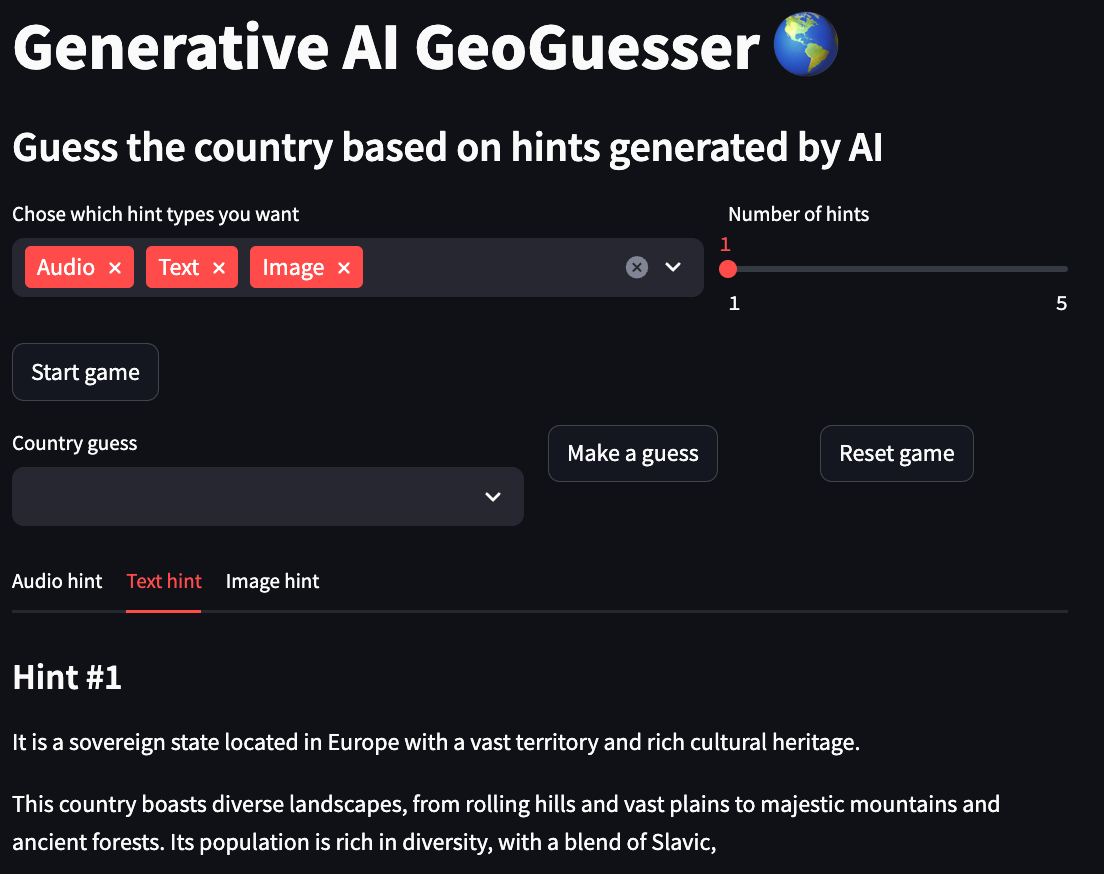
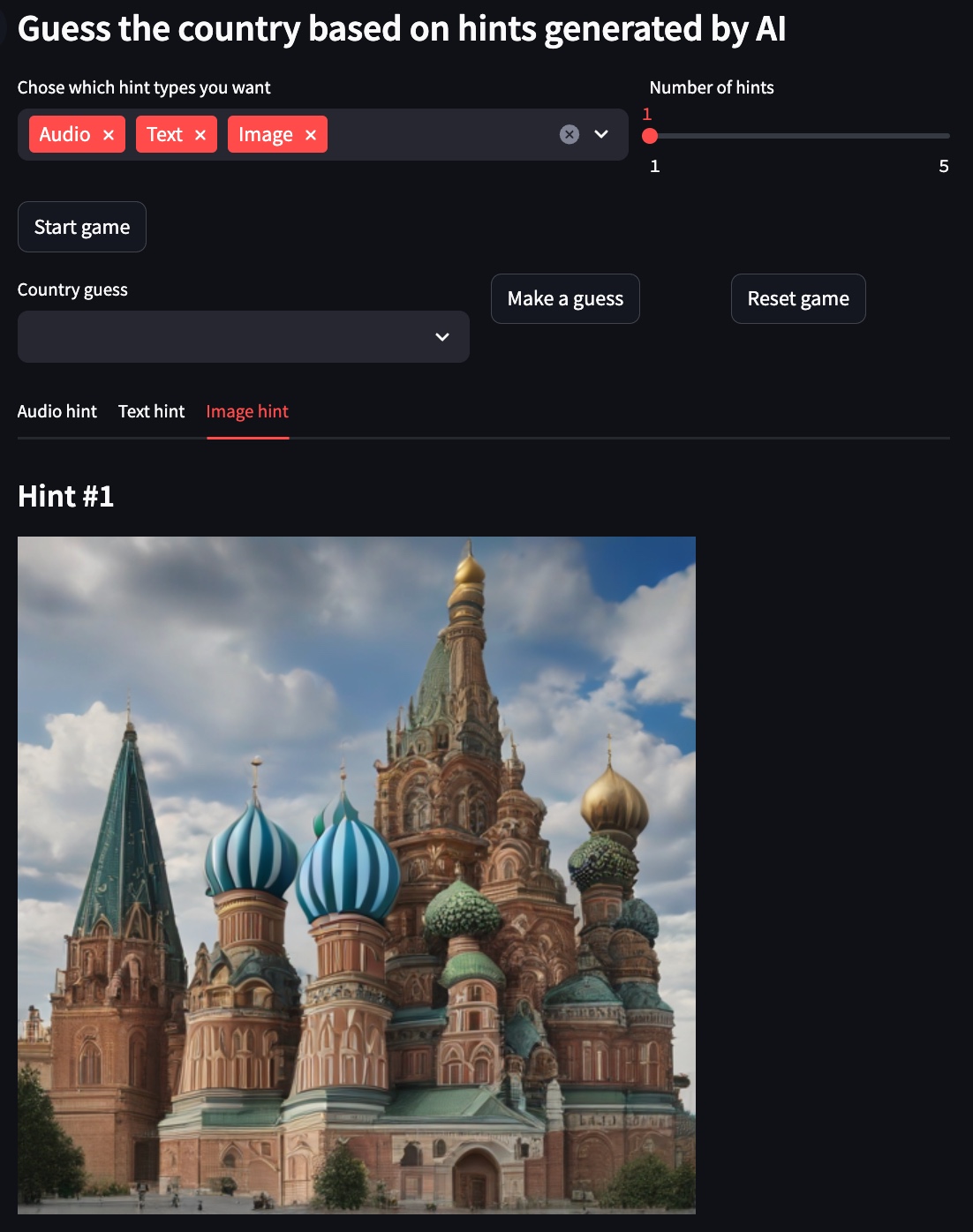
Für die folgenden Beispiele ist Russland das ausgewählte Land.
Texthinweis
Bildhinweis
Audio-Hinweis
Verwendung
Der empfohlene Ansatz zur Verwendung dieses Repositorys ist Docker. Sie können jedoch auch ein benutzerdefiniertes Venv verwenden. Stellen Sie jedoch sicher, dass alle Abhängigkeiten installiert sind.
Konfigurationen
local:
to_use: true
text:
model_id: google/gemma-1.1-2b-it
device: cpu
max_output_tokens: 50
temperature: 1
top_p: 0.95
top_k: 32
image:
model_id: stabilityai/sdxl-turbo
device: mps
num_inference_steps: 1
guidance_scale: 0.0
audio:
model_id: cvssp/audioldm2-music
device: cpu
num_inference_steps: 200
audio_length_in_s: 10
vertex:
to_use: false
project: {VERTEX_AI_PROJECT}
location: {VERTEX_AI_LOCALTION}
text:
model_id: gemini-1.5-pro-preview-0409
max_output_tokens: 50
temperature: 1
top_p: 0.95
top_k: 32
- lokal
- to_use: Wenn das Projekt diese Setup-Konfiguration verwenden soll
- Text
- model_id: Modell, das zum Erstellen der Texthinweise verwendet wird
- Gerät: Vom Modell verwendetes Gerät, normalerweise eines von (CPU, Cuda, MPS)
- max_output_tokens: Maximale Anzahl der vom Modell generierten Token
- Temperatur: Die Temperatur steuert den Grad der Zufälligkeit bei der Token-Auswahl. Niedrigere Temperaturen eignen sich gut für Eingabeaufforderungen, bei denen eine echte oder korrekte Antwort erwartet wird, während höhere Temperaturen zu vielfältigeren oder unerwarteteren Ergebnissen führen können. Bei einer Temperatur von 0 wird immer der Token mit der höchsten Wahrscheinlichkeit ausgewählt
- top_p: Top-p ändert, wie das Modell Token für die Ausgabe auswählt. Token werden vom wahrscheinlichsten zum geringsten Wert ausgewählt, bis die Summe ihrer Wahrscheinlichkeiten dem Top-P-Wert entspricht. Wenn beispielsweise die Token A, B und C eine Wahrscheinlichkeit von 0,3, 0,2 und 0,1 haben und der Top-P-Wert 0,5 beträgt, wählt das Modell entweder A oder B als nächsten Token aus (unter Verwendung der Temperatur). )
- top_k: Top-k ändert, wie das Modell Token für die Ausgabe auswählt. Ein Top-k von 1 bedeutet, dass der ausgewählte Token der wahrscheinlichste unter allen Token im Vokabular des Modells ist (auch als gierige Dekodierung bezeichnet), während ein Top-k von 3 bedeutet, dass der nächste Token aus den 3 wahrscheinlichsten Token ausgewählt wird ( mit Temperatur)
- Bild
- model_id: Modell, das zum Erstellen der Bildhinweise verwendet wird
- Gerät: Vom Modell verwendetes Gerät, normalerweise eines von (CPU, Cuda, MPS)
- num_inference_steps: Anzahl der Inferenzschritte für das Modell
- Guidance_scale: Zwingt die Generierung dazu, der Eingabeaufforderung besser zu entsprechen, möglicherweise auf Kosten der Bildqualität oder -vielfalt
- Audio-
- model_id: Modell, das zum Erstellen der Audiohinweise verwendet wird
- Gerät: Vom Modell verwendetes Gerät, normalerweise eines von (CPU, Cuda, MPS)
- num_inference_steps: Anzahl der Inferenzschritte für das Modell
- audio_length_in_s: Dauer des Audiohinweises
- Scheitel
- to_use: Wenn das Projekt diese Setup-Konfiguration verwenden soll
- Projekt: Von Vertex AI verwendeter Projektname
- Standort: Von Vertex AI verwendeter Projektstandort
- Text
- model_id: Modell, das zum Erstellen der Texthinweise verwendet wird
- max_output_tokens: Maximale Anzahl der vom Modell generierten Token
- Temperatur: Die Temperatur steuert den Grad der Zufälligkeit bei der Token-Auswahl. Niedrigere Temperaturen eignen sich gut für Eingabeaufforderungen, bei denen eine echte oder korrekte Antwort erwartet wird, während höhere Temperaturen zu vielfältigeren oder unerwarteteren Ergebnissen führen können. Bei einer Temperatur von 0 wird immer der Token mit der höchsten Wahrscheinlichkeit ausgewählt
- top_p: Top-p ändert, wie das Modell Token für die Ausgabe auswählt. Token werden vom wahrscheinlichsten zum geringsten Wert ausgewählt, bis die Summe ihrer Wahrscheinlichkeiten dem Top-P-Wert entspricht. Wenn beispielsweise die Token A, B und C eine Wahrscheinlichkeit von 0,3, 0,2 und 0,1 haben und der Top-P-Wert 0,5 beträgt, wählt das Modell entweder A oder B als nächsten Token aus (unter Verwendung der Temperatur). )
- top_k: Top-k ändert, wie das Modell Token für die Ausgabe auswählt. Ein Top-k von 1 bedeutet, dass der ausgewählte Token der wahrscheinlichste unter allen Token im Vokabular des Modells ist (auch als gierige Dekodierung bezeichnet), während ein Top-k von 3 bedeutet, dass der nächste Token aus den drei wahrscheinlichsten Token ausgewählt wird ( mit Temperatur)
Befehle
Starten Sie die Spiel-App.
Erstellen Sie das Docker-Image.
Wenden Sie Flusen und Formatierungen auf den Code an (nur für die Entwicklung erforderlich).


