doc genius ai
v1.0

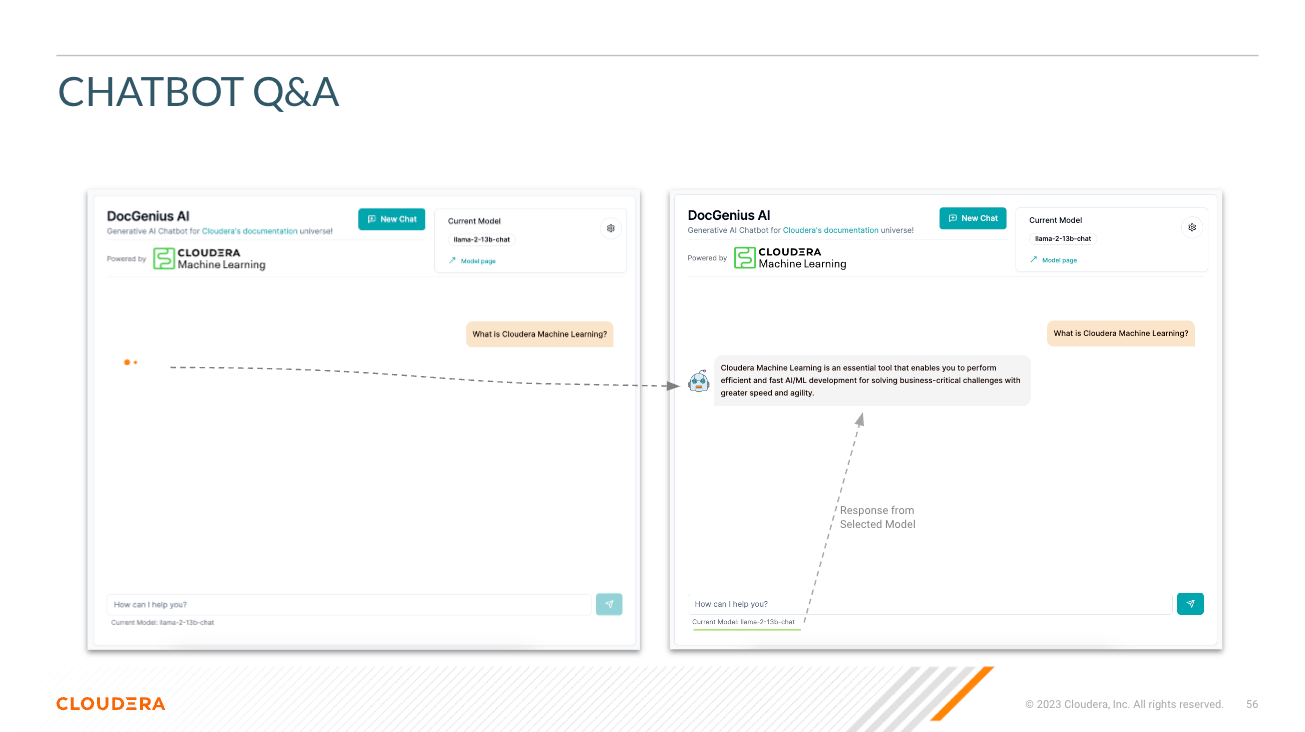
Modell auswählen – Hier kann der Benutzer das Parameter-Chat-Modell Llama3 70B ( llama-3-70b ) auswählen.
Wählen Sie Temperatur (Zufälligkeit der Reaktion) – Hier kann der Benutzer die Zufälligkeit der Reaktion des Modells skalieren. Niedrigere Zahlen sorgen für eine näherungsweisere, objektivere Antwort, während höhere Zahlen die Kreativität des Modells fördern.
Wählen Sie die Anzahl der Token (Länge der Antwort) – Hier wurden mehrere Optionen bereitgestellt. Die Anzahl der vom Benutzer verwendeten Token korreliert direkt mit der Länge der Antwort, die das Modell zurückgibt.
Frage – So wie es sich anhört; Hier kann der Benutzer dem Modell eine Frage stellen
Antwort – Dies ist die vom Modell generierte Antwort angesichts des Kontexts in Ihrer Vektordatenbank. Beachten Sie, dass Sie möglicherweise halluzinierte Antworten erhalten, wenn die Frage keinen Bezug zum Inhalt Ihrer Wissensdatenbank hat.
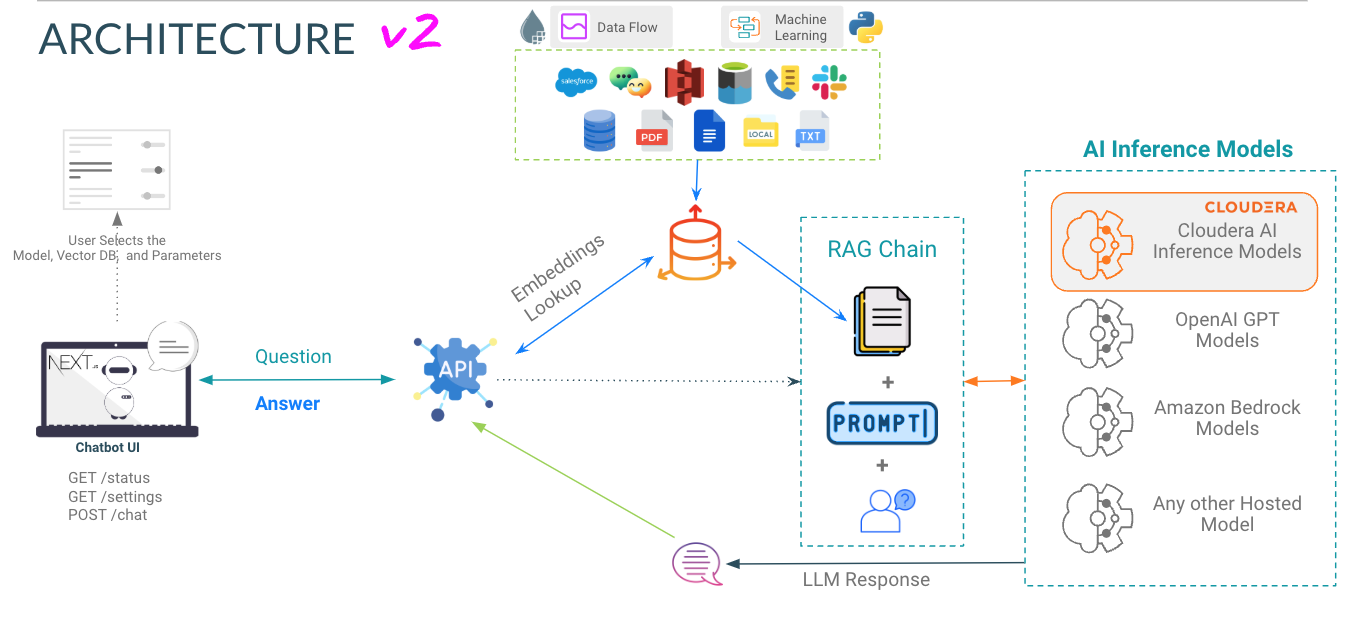
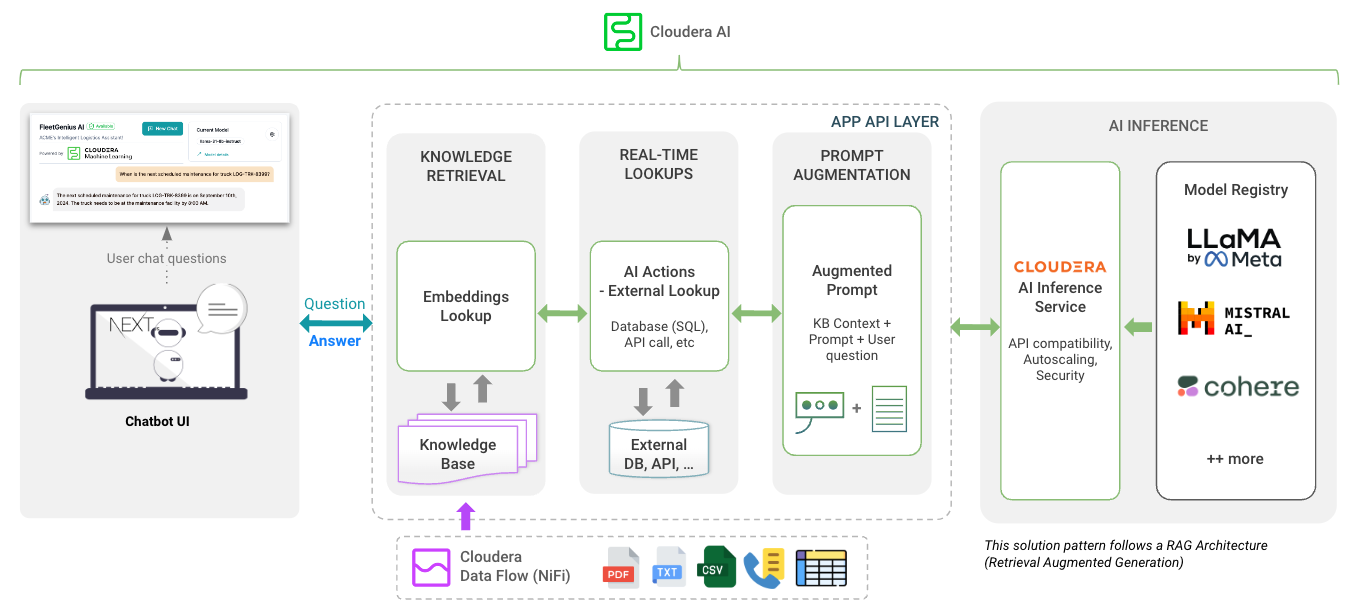
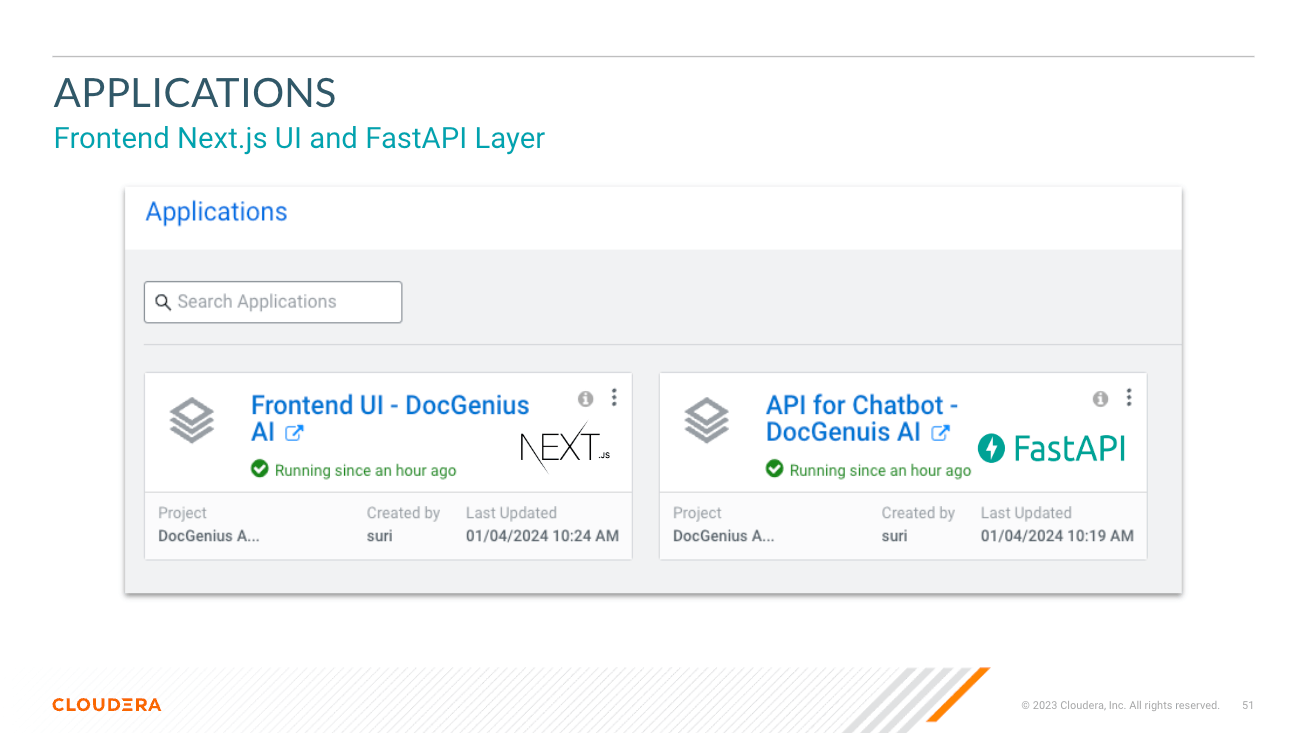
app Verzeichnis hostet die FastAPI für Ihre LLMs
chat-ui Verzeichnis hostet den Code für die Chatbot-Benutzeroberfläche.
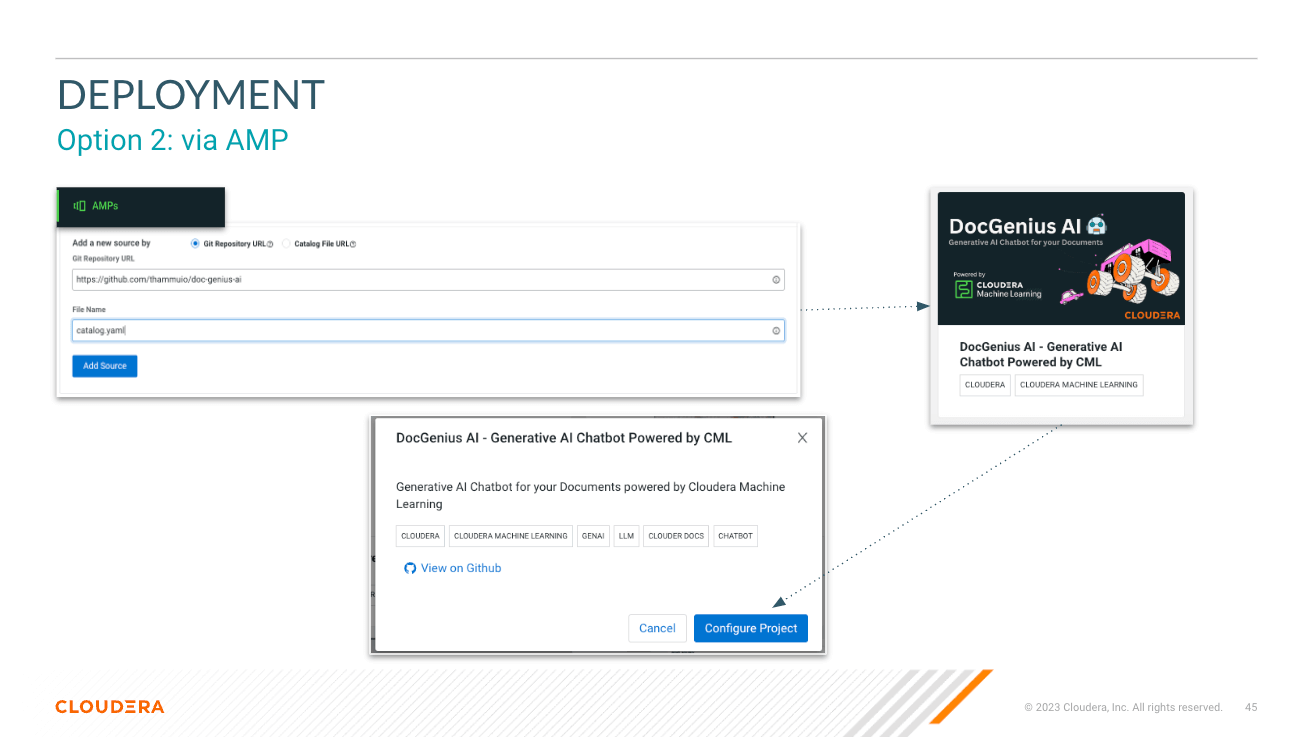
Achten Sie bei der Bereitstellung des AMP auf Variablen. Informationen zum Abrufen des Inferenzendpunkts und -schlüssels finden Sie in den AI-Inferenzdokumenten von Cloduera.
JupyterLab – Python 3.11 – Nvidia-GPU
https://docs.cloudera.com/machine-learning/cloud/applied-ml-prototypes/topics/ml-amp-project-spec.html
Dadurch entstehen folgende Workloads mit Ressourcenbedarf:
2 CPU, 16GB MEM2 CPU, 8GB MEM2 CPU, 1 GPU, 16GB MEM doc-genius-ai/
├── app/ # Application directory for API and Model Serving
│ └── [..subdirs..]
│ └── chatbot/ # has the model serving python files for RAG, Prompt, Fine-tuning models
│ └── main.py # main.py file to start the API
├── chat-ui/ # Directory for the chatbot UI in Next.js
│ └── [..subdirs..]
│ └── app.py # app.py file to serve build files in .next directory via Flask
├── pipeline/ # Pipeline directory for data processing or workflow pipelines and vector load
├── data/ # Data directory for storing datasets or data files or RAG KB
├── models/ # Models directory for LLMs / ML models
├── session/ # Scripts for CML Sessions and Validation Tasks
├── images/ # Directory for storing project related images
├── api.md # Documentation for the APIs
├── README.md # Detailed description of the project
├── .gitignore # Specifies intentionally untracked files to ignore
├── catalog.yaml # YAML file that contains descriptive information and metadata for the displaying the AMP projects in the CML Project Catalog.
├─ .project-metadata.yaml # Project metadata file that provides configuration and setup details
├── cdsw-build.sh # Script for building the Model dependencies
└── requirements.txt # Python dependencies for Model Serving
WICHTIG: Bitte lesen Sie Folgendes, bevor Sie fortfahren. Dieses AMP umfasst bestimmte Softwarepakete von Drittanbietern oder ist anderweitig von diesen abhängig. Informationen zu solchen Softwarepaketen von Drittanbietern werden in der mit diesem AMP verknüpften Hinweisdatei zur Verfügung gestellt. Durch die Konfiguration und den Start dieses AMP veranlassen Sie, dass solche Softwarepakete von Drittanbietern heruntergeladen und in Ihrer Umgebung installiert werden, in einigen Fällen auch von Websites Dritter. Weitere Informationen zu jedem Drittanbieter-Softwarepaket finden Sie in der Hinweisdatei und auf den entsprechenden Websites, einschließlich der geltenden Lizenzbedingungen.
Wenn Sie die Softwarepakete von Drittanbietern nicht herunterladen und installieren möchten, dürfen Sie diesen AMP nicht konfigurieren, starten oder anderweitig verwenden. Durch die Konfiguration, den Start oder die anderweitige Nutzung des AMP erkennen Sie die vorstehende Erklärung an und stimmen zu, dass Cloudera in keiner Weise für die Softwarepakete Dritter verantwortlich oder haftbar ist.
Copyright (c) 2024 – Cloudera, Inc. Alle Rechte vorbehalten.


