genkitx hnsw
1.0.0

Sie können in diesem Repository zu diesem Plugin beitragen.
HNSW ist Vector Database Hierarchical Navigable Small World (HNSW). Graphen gehören zu den leistungsstärksten Indizes für die Vektorähnlichkeitssuche. HNSW ist eine äußerst beliebte Technologie, die immer wieder Spitzenleistung mit superschnellen Suchgeschwindigkeiten und fantastischem Recall bietet. Erfahren Sie mehr über HNSW.
Wenn Sie möchten, können Sie diese Vektordatenbank bevorzugen
Damit können Sie eine leistungsstarke Retrieval Augmentation Generation (RAG) in der generativen KI erreichen, sodass Sie kein eigenes KI-Modell erstellen oder das KI-Modell neu trainieren müssen, um mehr Kontext oder Wissen zu erhalten, sondern stattdessen eine zusätzliche Kontextebene hinzufügen können Ihr KI-Modell kann mehr Wissen verstehen, als das Basis-KI-Modell weiß. Dies ist nützlich, wenn Sie mehr Kontext oder mehr Wissen auf der Grundlage spezifischer Informationen oder Kenntnisse erhalten möchten, die Sie definieren.
Wenn Sie über eine Restaurantanwendung oder Website verfügen, können Sie spezifische Informationen zu Ihren Restaurants, Ihrer Adresse, der Speisekartenliste mit Preis und anderen spezifischen Dingen hinzufügen, sodass Ihre KI genau antworten kann, wenn Ihr Kunde die KI nach Ihrem Restaurant fragt . Dies kann Ihnen den Aufwand für die Erstellung eines Chatbots ersparen, stattdessen können Sie generative KI verwenden, die mit spezifischem Wissen angereichert ist.
Beispielgespräch:
You : Wie lautet die Preisliste meines Restaurants in Surabaya City?
AI : Preisliste:
Stellen Sie vor der Installation des Plugins sicher, dass die folgenden Voraussetzungen installiert sind:
npm install -g typescript )Um dieses Plugin zu installieren, können Sie diesen Befehl oder Ihren bevorzugten Paketmanager ausführen
npm install genkitx-hnswDieses Plugin verfügt über mehrere Funktionen wie folgt:
HNSW Indexer Wird zum Erstellen eines Vektorindex basierend auf allen von Ihnen bereitgestellten Daten und Informationen verwendet. Dieser Vektorindex wird als Wissensreferenz für HNSW Retriever verwendet.HNSW Retriever Wird verwendet, um generative KI-Antworten mit dem Gemini-Modell als Basis zu erhalten, angereichert mit zusätzlichem Wissen und Kontext basierend auf Ihrem Vektorindex. Dies ist eine Verwendung des Genkit-Plugin-Flows zum Speichern von Daten im Vektorspeicher mit HNSW Vector Store, Gemini Embedder und Gemini LLM.
Bereiten Sie Ihre Daten oder Dokumente in einem Ordner vor
Importieren Sie das Plugin in Ihr Genkit-Projekt
import { hnswIndexer } from " genkitx-hnsw " ;
export default configureGenkit({
plugins: [
hnswIndexer({ apiKey: " GOOGLE_API_KEY " })
]
}) ; Öffnen Sie die Genkit-Benutzeroberfläche und wählen Sie das registrierte Plugin HNSW Indexer aus
Führen Sie den Flow mit den erforderlichen Eingabe- und Ausgabeparametern aus
dataPath : Ihr Daten- und anderer Dokumentenpfad, der von der KI gelernt werden sollindexOutputPath : Ihr erwarteter Ausgabepfad für Ihren Vector Store Index, der basierend auf den von Ihnen bereitgestellten Daten und Dokumenten verarbeitet wird 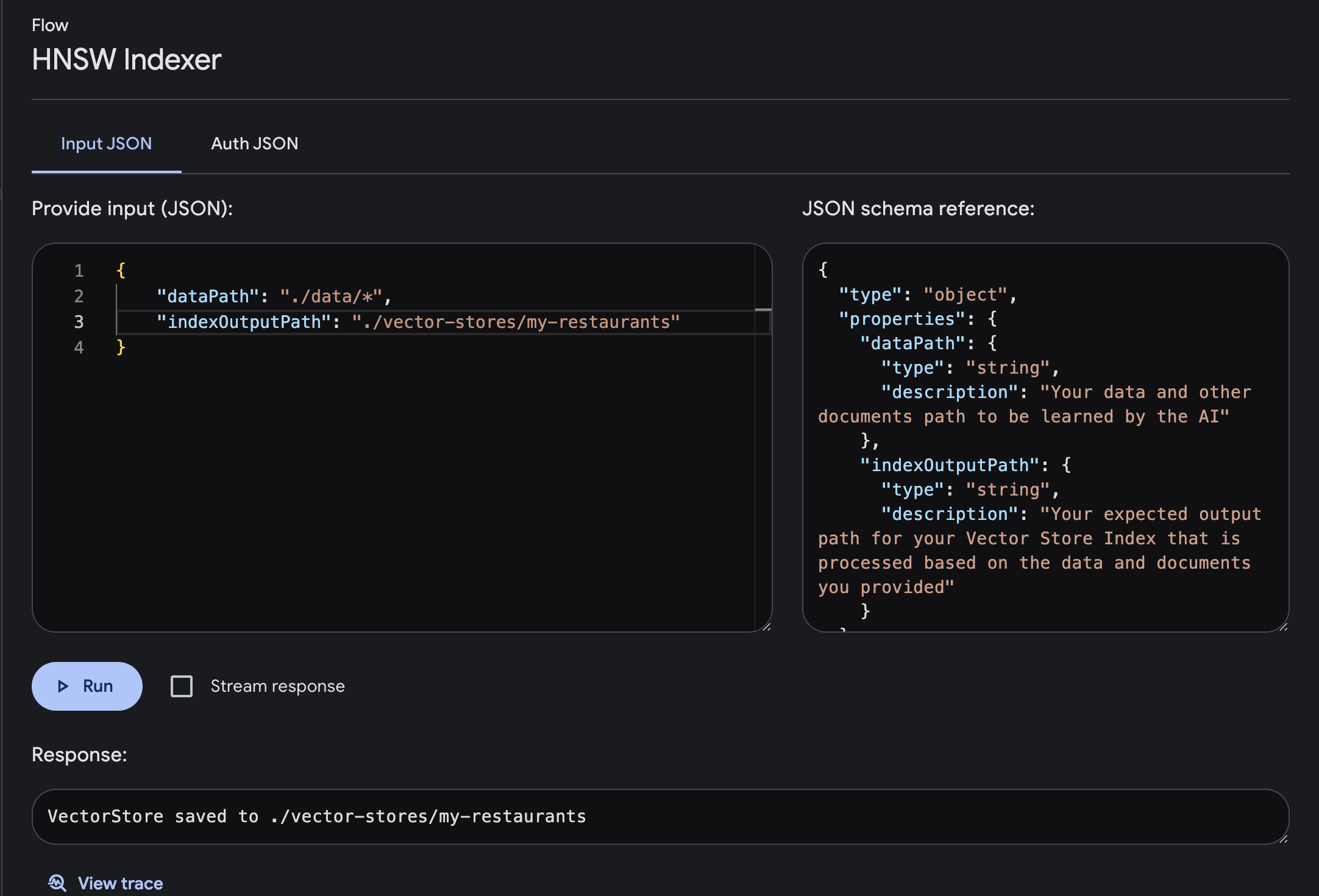
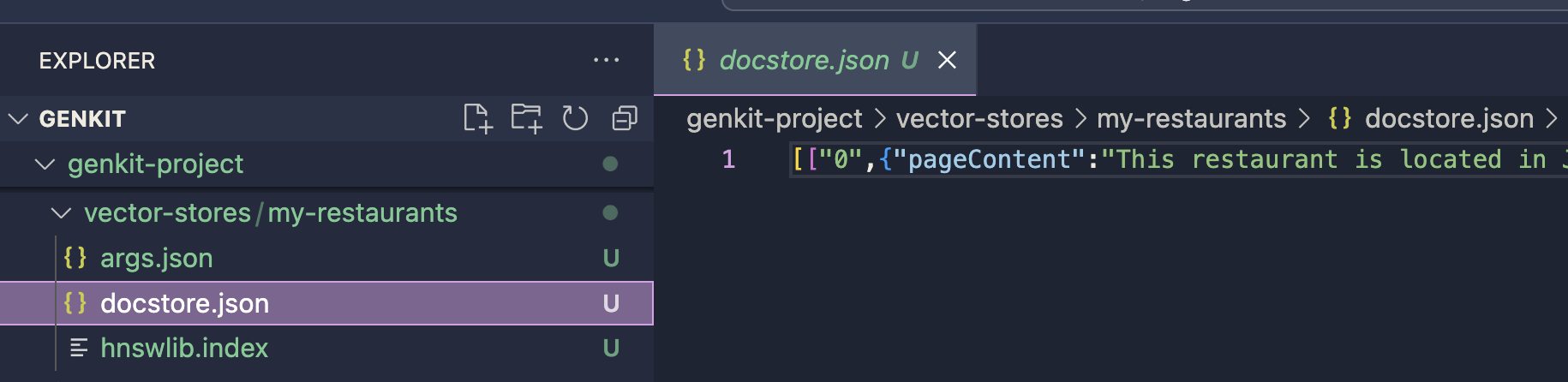 Der Vektorspeicher wird im definierten Ausgabepfad gespeichert. Dieser Index wird für den Eingabeaufforderungsgenerierungsprozess mit dem HNSW Retriever-Plugin verwendet. Sie können die Implementierung mit dem HNSW Retriever-Plugin fortsetzen
Der Vektorspeicher wird im definierten Ausgabepfad gespeichert. Dieser Index wird für den Eingabeaufforderungsgenerierungsprozess mit dem HNSW Retriever-Plugin verwendet. Sie können die Implementierung mit dem HNSW Retriever-Plugin fortsetzen
chunkSize: number wie viele Daten gleichzeitig verarbeitet werden. Es ist, als würde man eine große Aufgabe in kleinere Teile zerlegen, um sie leichter bewältigen zu können. Durch Festlegen der Blockgröße entscheiden wir, wie viele Informationen die KI auf einmal verarbeitet, was sich sowohl auf die Geschwindigkeit als auch auf die Genauigkeit des Lernprozesses der KI auswirken kann.
default value : 12720
separator: string Bei der Erstellung eines Vektorindex wird ein Symbol oder Zeichen verwendet, um verschiedene Informationsteile in den Eingabedaten zu trennen. Es hilft der KI zu verstehen, wo eine Dateneinheit endet und eine andere beginnt, sodass sie die Daten effektiver verarbeiten und daraus lernen kann.
default value : "n"
Dies ist eine Verwendung des Genkit-Plugin-Flows zur Verarbeitung Ihrer Eingabeaufforderung mit dem Gemini-LLM-Modell, angereichert mit zusätzlichen und spezifischen Informationen oder Kenntnissen in der von Ihnen bereitgestellten HNSW-Vektordatenbank. Mit diesem Plugin erhalten Sie eine LLM-Antwort mit zusätzlichem spezifischen Kontext.
Importieren Sie das Plugin in Ihr Genkit-Projekt
import { googleAI } from " @genkit-ai/googleai " ;
import { hnswRetriever } from " genkitx-hnsw " ;
export default configureGenkit({
plugins: [
googleAI (),
hnswRetriever({ apiKey: " GOOGLE_API_KEY " })
]
}) ;Stellen Sie sicher, dass Sie das GoogleAI-Plugin für den Gemini-LLM-Modellanbieter importieren. Derzeit unterstützt dieses Plugin nur Gemini. Weitere Modelle werden in Kürze bereitgestellt!
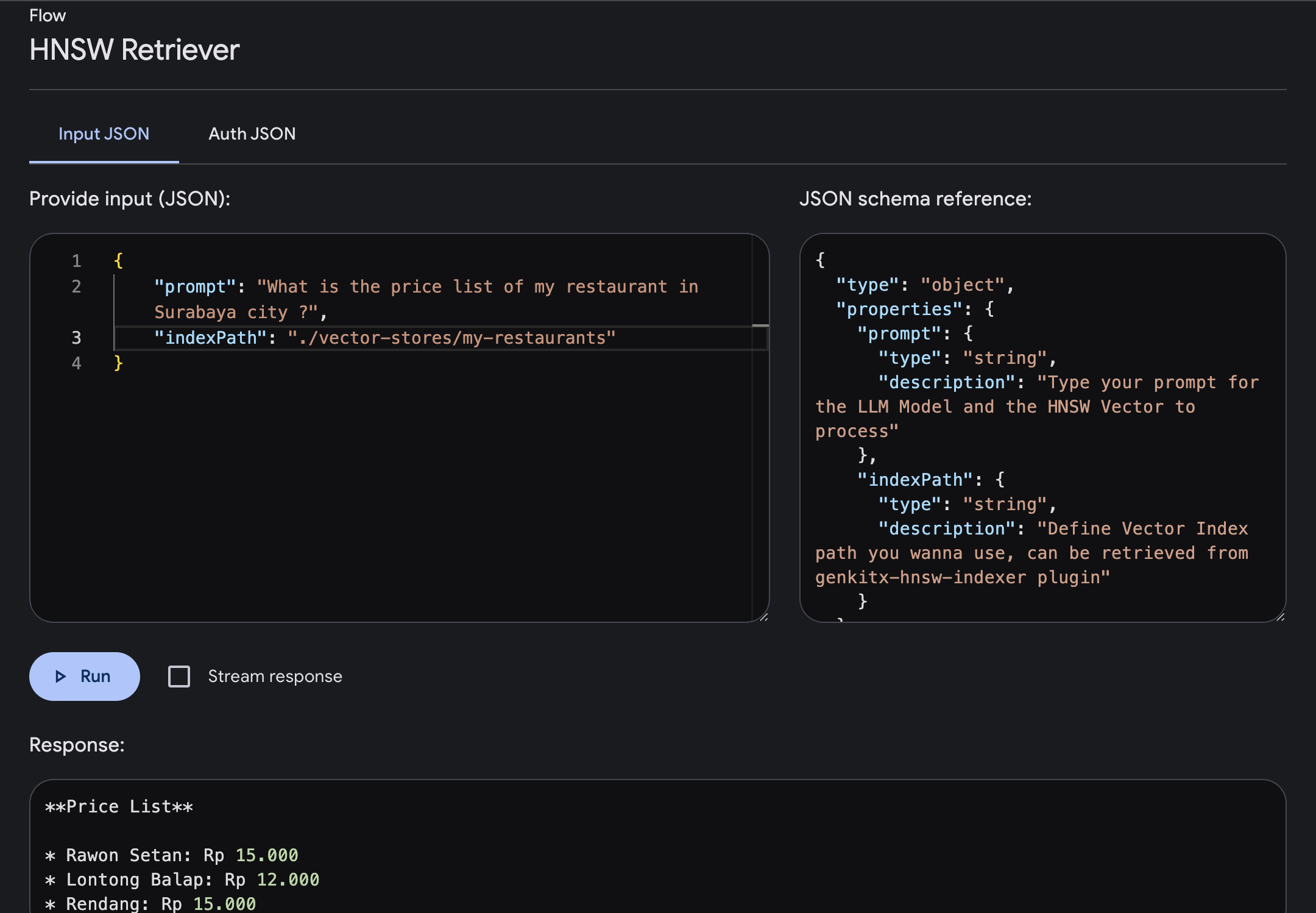
Öffnen Sie die Genkit-Benutzeroberfläche und wählen Sie das registrierte Plugin HNSW Retriever aus. Führen Sie den Flow mit dem erforderlichen Parameter aus
prompt : Geben Sie Ihre Eingabeaufforderung ein, bei der Sie Antworten mit erweitertem Kontext basierend auf dem von Ihnen bereitgestellten Vektor erhalten.indexPath : Definieren Sie den Vektorindexpfad des Ordners, den Sie als Wissensreferenz verwenden möchten. Sie erhalten diesen Dateipfad vom HNSW Indexer-Plugin.In diesem Beispiel versuchen wir, nach den Preislisteninformationen eines Restaurants in der Stadt Surabaya zu fragen, wo diese im Vector Index bereitgestellt wurden.
Wir können die Eingabeaufforderung eingeben und ausführen. Sobald der Ablauf abgeschlossen ist, erhalten Sie eine Antwort, die mit spezifischem Wissen basierend auf Ihrem Vektorindex angereichert ist.
temperature: number Temperatur steuert die Zufälligkeit der generierten Ausgabe. Niedrigere Temperaturen führen zu einer deterministischeren Ausgabe, wobei das Modell bei jedem Schritt den wahrscheinlichsten Token auswählt. Höhere Temperaturen erhöhen die Zufälligkeit und ermöglichen es dem Modell, weniger wahrscheinliche Token zu untersuchen und möglicherweise kreativeren, aber weniger kohärenten Text zu erzeugen.
default value : 0.1
maxOutputTokens: number Dieser Parameter gibt die maximale Anzahl an Token (Wörtern oder Unterwörtern) an, die das Modell in einem einzelnen Inferenzschritt generieren soll. Es hilft, die Länge des generierten Textes zu steuern.
default value : 500
topK: number Top-K-Stichproben beschränkt die Auswahl des Modells bei jedem Schritt auf die obersten K höchstwahrscheinlichen Token. Dadurch wird verhindert, dass das Modell übermäßig seltene oder unwahrscheinliche Token berücksichtigt, wodurch die Kohärenz des generierten Texts verbessert wird.
default value : 1
topP: number Top-P-Sampling, auch als Kernsampling bekannt, berücksichtigt die kumulative Wahrscheinlichkeitsverteilung von Token und wählt die kleinste Menge von Token aus, deren kumulative Wahrscheinlichkeit einen vordefinierten Schwellenwert überschreitet (oft als P bezeichnet). Dies ermöglicht eine dynamische Auswahl der Anzahl der in jedem Schritt berücksichtigten Token, abhängig von der Wahrscheinlichkeit der Token.
default value : 0
stopSequences: string[] Dies sind Sequenzen von Token, die bei ihrer Generierung dem Modell signalisieren, die Textgenerierung zu stoppen. Dies kann nützlich sein, um die Länge oder den Inhalt der generierten Ausgabe zu steuern, z. B. um sicherzustellen, dass das Modell die Generierung stoppt, nachdem das Ende eines Satzes oder Absatzes erreicht ist.
default value : []
Lizenz: Apache 2.0


