rag with human support
1.0.0
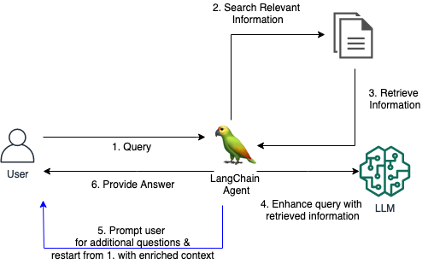
Herkömmliche RAG-Systeme haben oft Schwierigkeiten, zufriedenstellende Antworten zu liefern, wenn Benutzer vage oder mehrdeutige Fragen stellen, ohne ausreichenden Kontext bereitzustellen. Dies führt zu wenig hilfreichen Antworten wie „Ich weiß nicht“ oder falschen, erfundenen Antworten eines LLM. Dieses Repo enthält Code zur Verbesserung herkömmlicher RAG-Agenten.
Wir stellen ein benutzerdefiniertes LangChain-Tool für einen RAG-Agenten vor, das es dem Agenten ermöglicht, einen Dialog mit einem Benutzer zu führen, wenn die anfängliche Frage unklar oder zu vage ist. Indem er klärende Fragen stellt, den Benutzer zu weiteren Details auffordert und kontextbezogene Informationen einbezieht, kann der Agent den notwendigen Kontext sammeln, um eine genaue, hilfreiche Antwort zu geben – selbst bei einer mehrdeutigen anfänglichen Anfrage.
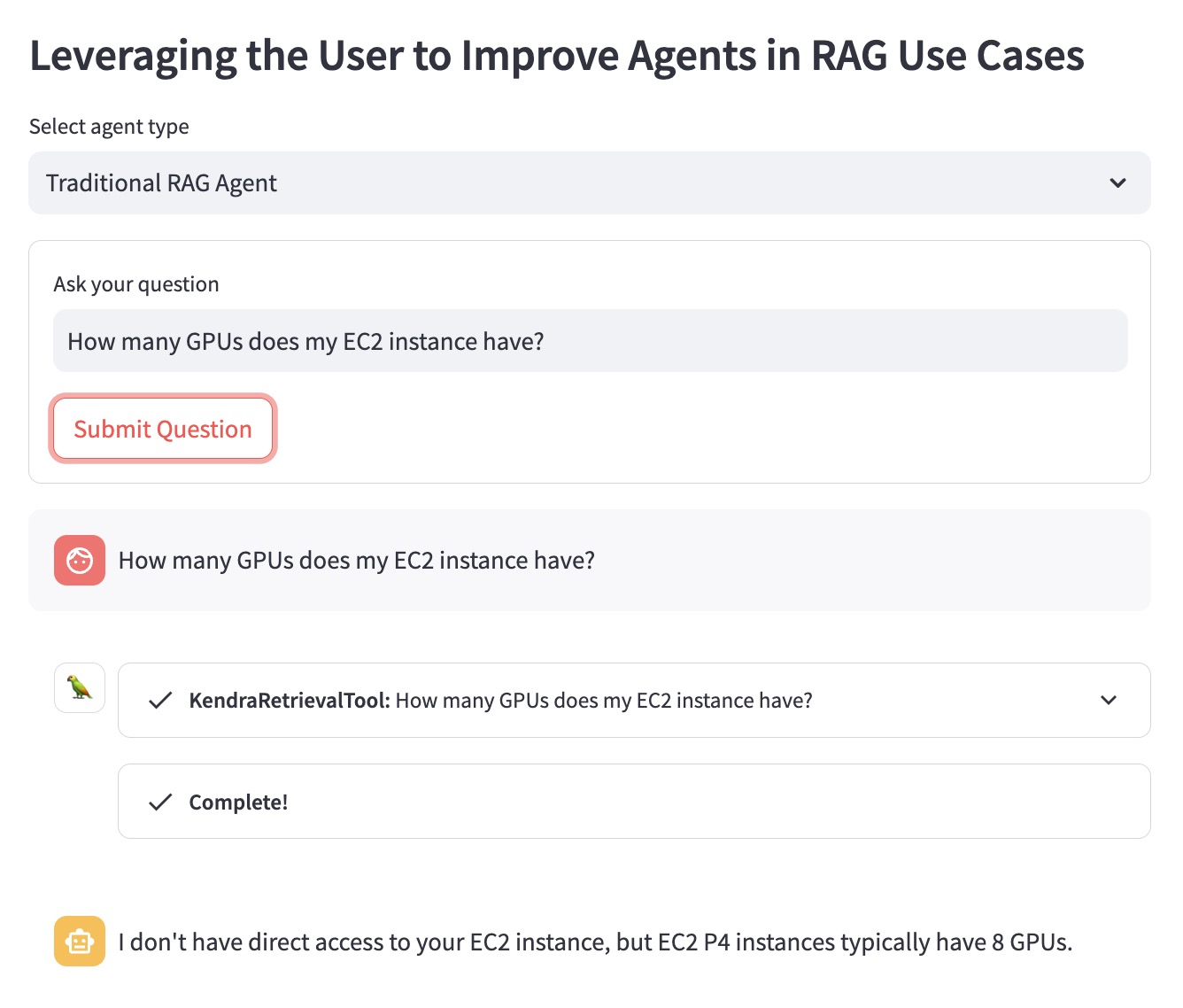
Lassen Sie uns den Vorteil anhand des folgenden Fragebeispiels verdeutlichen: „Wie viele GPUs hat meine EC2-Instanz?“
Der herkömmliche RAG-Agent weiß nicht, welche EC2-Instanz der Benutzer im Sinn hat. Daher gibt es eine Antwort, die nicht sehr hilfreich ist:
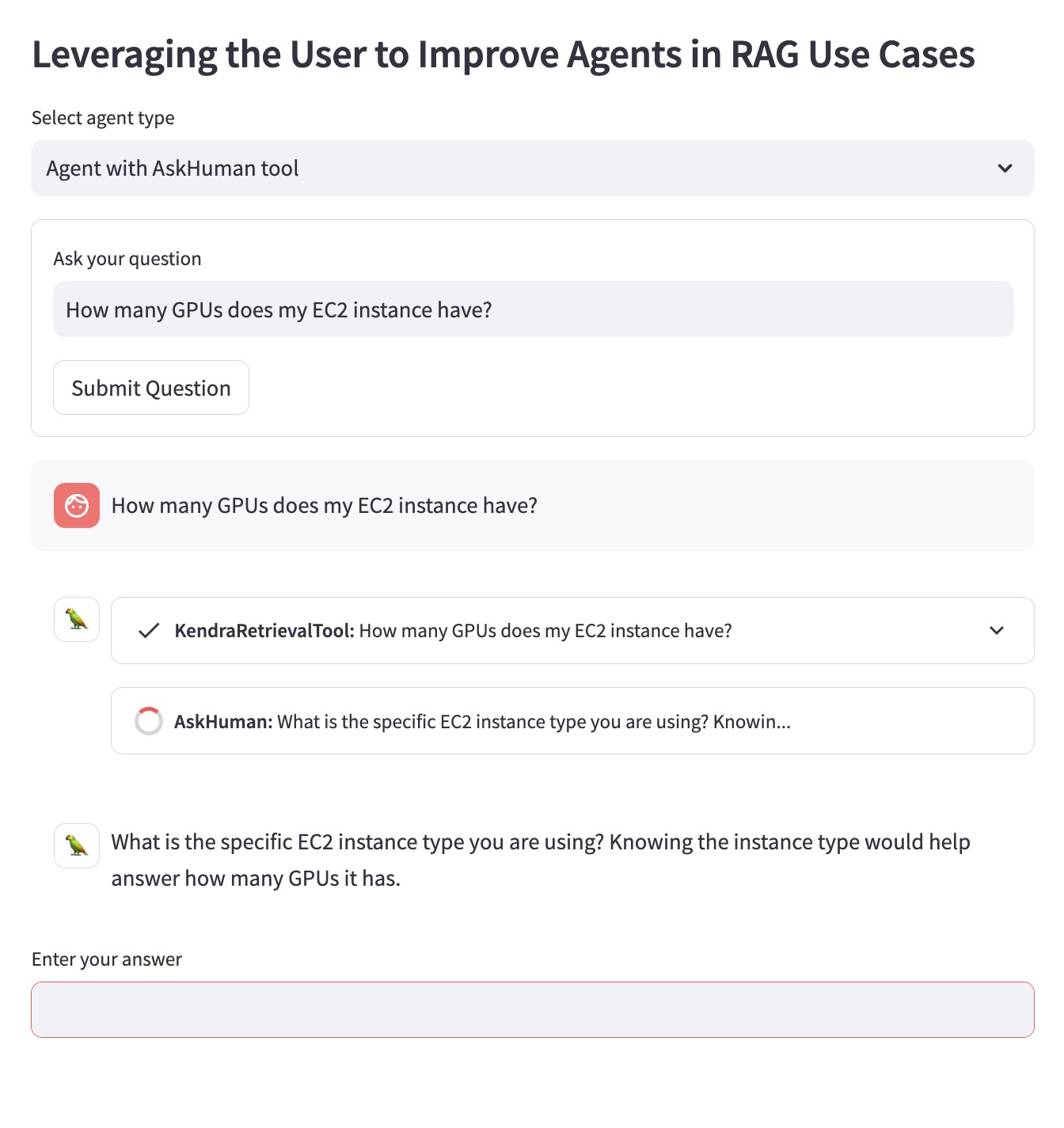
Der verbesserte RAG-Agent mit dem Tool „AskHuman“ führt zwei zusätzliche Schritte aus:
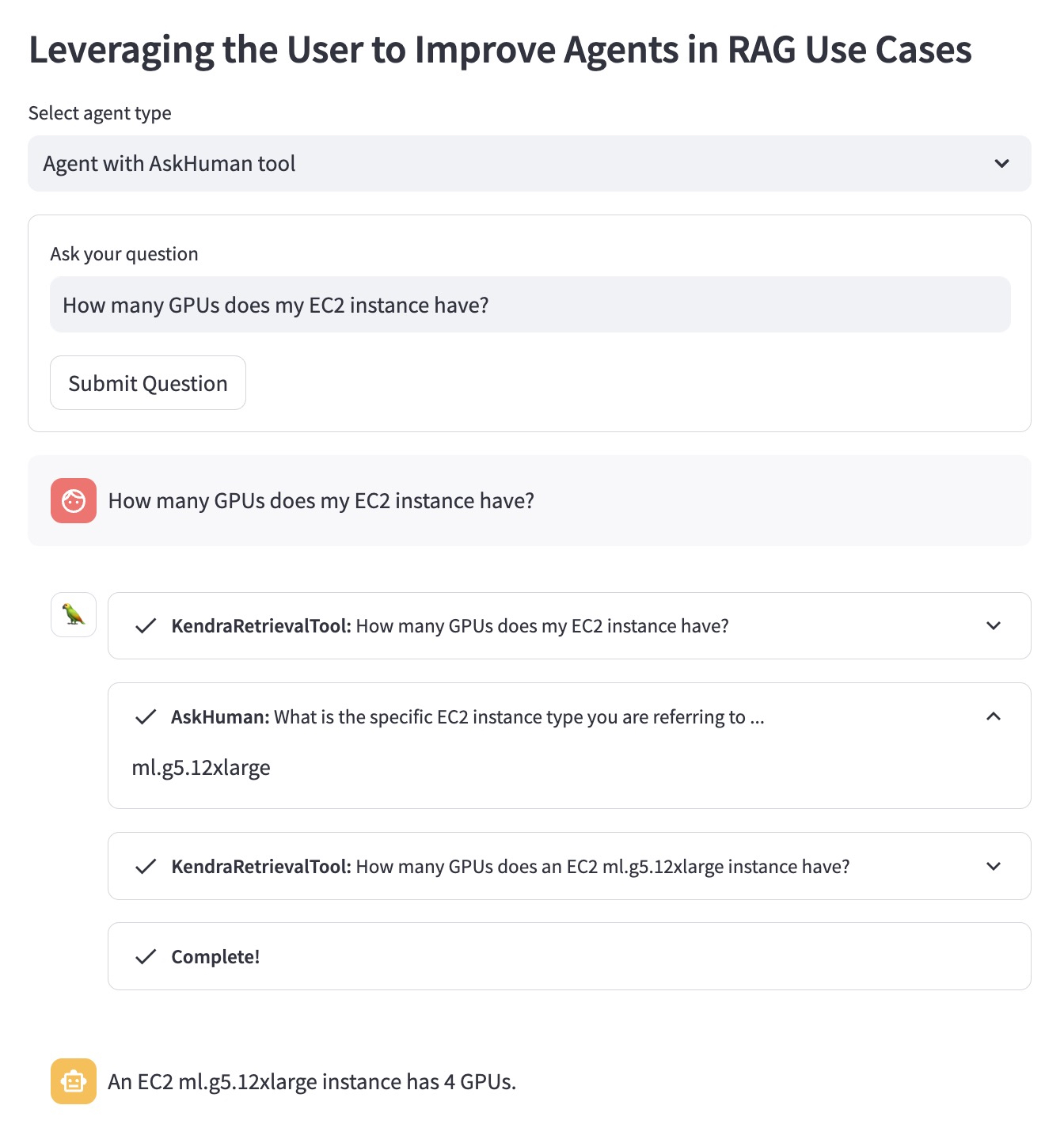
Dies hilft dem verbesserten Agenten, eine spezifische und hilfreiche Antwort zu geben:
Um diese Demo in Ihrem AWS-Konto auszuführen, müssen Sie die folgenden Schritte ausführen:
llm das im LangChain-Agenten in demo.py verwendet wird, durch ein unterstütztes LLM von LangChain.sh dependencies.sh im Terminal ausführen.KENDRA_INDEX_ID in den Retriever-Parametern demo.py an.streamlit run demo.py im Terminal ausführen. Beachten Sie, dass durch die Bereitstellung eines neuen Kendra-Index und die Ausführung der Demo möglicherweise zusätzliche Kosten auf Ihrer Rechnung anfallen. Um unnötige Kosten zu vermeiden, löschen Sie bitte den Amazon Kendra Index, wenn Sie ihn nicht mehr verwenden, und fahren Sie eine SageMaker Studio-Instanz herunter, wenn Sie ihn zum Ausführen der Demo verwendet haben.


