opensquare
1.0.0

Open-Source-Social-Media-Intelligence und OSINT
Entdecken Sie die Dokumente »
Demo ansehen · Fehler melden · Funktion anfordern
Zwischen April 2022 und April 2023 gab es 150 Millionen neue Social-Media-Nutzer – das ist ein Anstieg von 3,2 % gegenüber dem Vorjahr gegenüber den derzeit 4,8 Milliarden Social-Media-Nutzern weltweit, was 59,9 % der Weltbevölkerung und 92,7 % aller Internetnutzer entspricht. Unternehmen nutzen soziale Medien, um Erkenntnisse zu verschiedenen Themen zu gewinnen: Benutzerstimmung zu Produkten, starke und schwache Produkte, Veranstaltungen und alles, was auf ihre Kunden zugeschnitten ist. Wer sind die Kunden von Geheimdienstanalysten und Sozialwissenschaftlern? Politische Entscheidungsträger, der normale Bürger, jeder in der Gesellschaft. Der Benutzer und Kunde dieses Projekts sind Analysten und Forscher aus den Bereichen Intelligenz und Sozialwissenschaften. Während die Innovationskurve der Technologie immer weiter ansteigt und die Gesellschaft soziale Medien zunehmend als öffentlichen Raum nutzt, können Forscher diese verfügbaren Daten für gute Zwecke nutzen, um Erkenntnisse zu gewinnen, schädliche Vorfälle zu verlangsamen oder zu stoppen, der Gesellschaft zu helfen und Pläne zu entwickeln Auf der Grundlage eines öffentlichen Konsenses können politische Entscheidungsträger besser darüber informiert werden, was ihre Wähler brauchen und wollen (und bessere Lösungen planen, die die Zufriedenheit ihrer Kunden erhöhen). Da es für Regierungen immer schwieriger wird, Lösungen zu verstehen und umzusetzen, die ihren Wählern besser dienen, wird die Idee einer adaptiven Governance, die sich auf dezentrale Entscheidungsstrukturen konzentriert, unumgänglich. Erkenntnisse aus sozialen Medien können nicht nur politischen Entscheidungsträgern helfen, sondern auch adaptive Governance-Einheiten und -Gruppen dabei unterstützen, ihre Bevölkerung besser zu versorgen. Dieses Produkt richtet sich an Geheimdienstanalysten, Sozialwissenschaftler, Datenwissenschaftler und alle, die daran interessiert sind, die Qualität unserer menschlichen Existenz durch tiefgreifende öffentliche Analysen und datengesteuerte Lösungen zu verbessern.
(zurück nach oben)
(zurück nach oben)
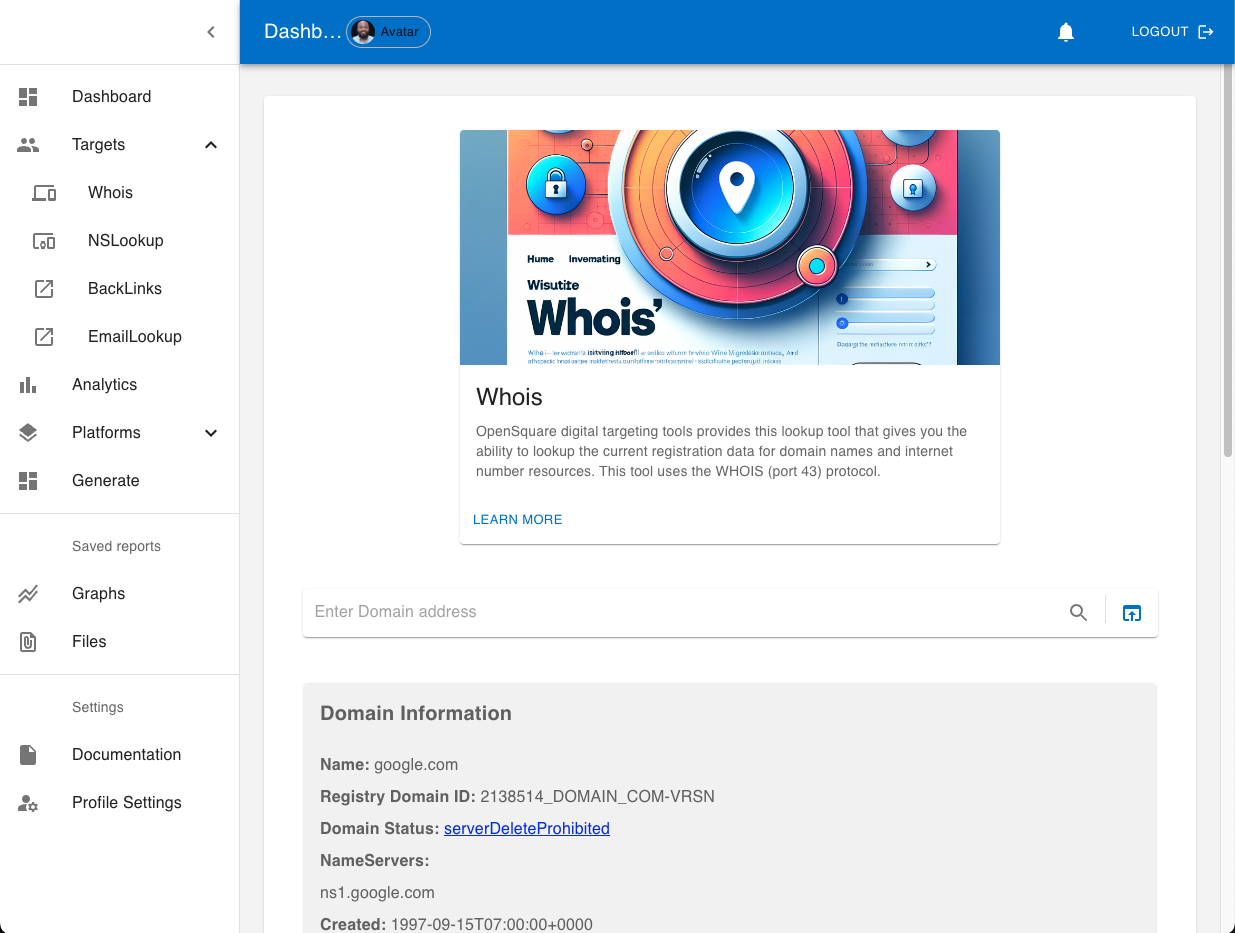
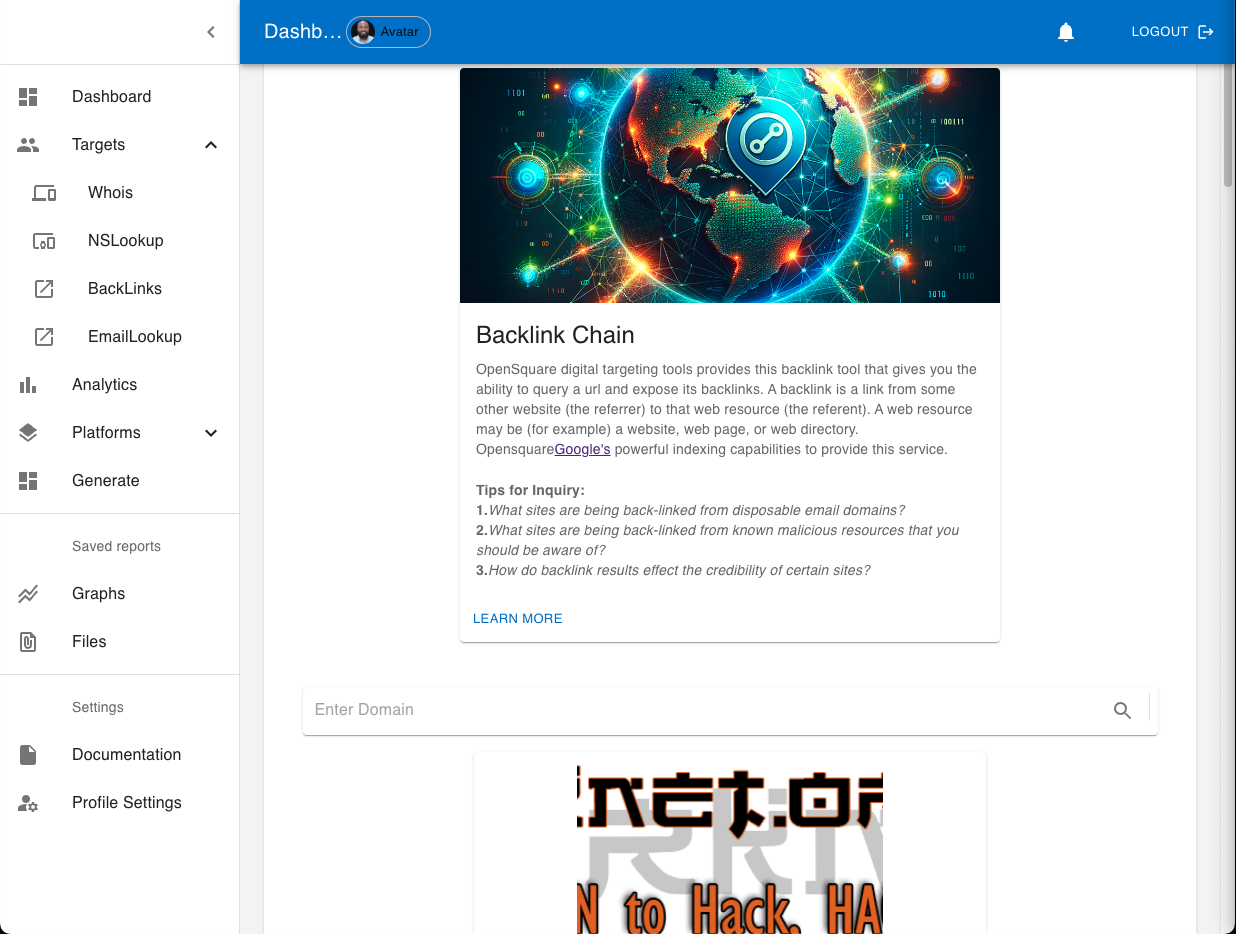
Neben anderen Funktionen bietet OpenSquare Targeting-Tools für den digitalen Fußabdruck, von denen einige bekannte OSINT-Methoden wie Backlinks, NSLookup und Whois verwenden. Durch die Bereitstellung einer allgemeinen Suite von Tools an einem einzigen Ort kann die Benutzerproduktivität gesteigert werden. Navigieren Sie einfach zwischen Dashboard-Arbeitsbereichen und verwenden Sie die Ausgabe eines Tools als Eingabe für ein anderes.
Experimentieren Sie mit der Erstellung von Berichten und Dokumenten mit GenAI. Nutzen Sie die von Ihnen gesammelten Informationen und Bilder, um Berichte zu erstellen, die zu Entscheidungsvorteilen führen. Bitten Sie unser KI-System, Bilder basierend auf dem Informationskontext für Sie zu generieren und wichtige Details zusammenzufassen. Steigern Sie die Produktivität und reduzieren Sie die Geschwindigkeit bei der Bereitstellung wichtiger Erkenntnisse für Entscheidungsträger mithilfe von Click-and-Point- und Draggable-Oberflächen drastisch.
Opensquare nutzt Whisper: ein Allzweck-Spracherkennungsmodell. Es wird auf einem großen Datensatz unterschiedlicher Audiodaten trainiert und ist außerdem ein Multitasking-Modell, das mehrsprachige Spracherkennung, Sprachübersetzung und Sprachidentifizierung durchführen kann.
Mithilfe der verfügbaren APIs von Opensquare können Sie YouTube-Videos abfragen und transkribieren. Transkripte geben Zeit- und Texteigenschaften an. Diese API wird zum Erstellen von Funktionen auf Opensquare verwendet, wird aber auch der Öffentlichkeit als benutzerfreundliche API zur Verfügung stehen.
opensquare/api/youtube/en/transcribe?videoId=l9AzO1FMgM8
produziert:
[ { "time": "0.0", "text": "Java, a high-level multi-paradigm programming language famous for its ability to compile" }, { "time": "5.2", "text": "to platform independent bytecode." }, { "time": "7.44", "text": "It was designed by James Gosling in 1990 at Sun Microsystems." }, { "time": "11.700000000000001", "text": "One of its first demonstrations was the Star 7 PDA, which gave birth to the Java mascot" },... ]
Um eine lokale Kopie zum Laufen zu bringen, befolgen Sie diese einfachen Beispielschritte.
Linux
Java 17
java --versionMaven 3.9 oder höher
mvn --versionKlonen Sie das Repo
git git clone https://[email protected]/intelligence-opensent/opensentop.gitInstallieren Sie das Standardprofil für Abhängigkeiten (einschließlich NPM).
mvn clean installFühren Sie Webpack im Entwicklungsmodus aus
npm run watch
Es gibt einige Konfigurationsdateien, die Sie benötigen – Sie können mich gerne anpingen, um diese zu erhalten.
(zurück nach oben)
Dieses Projekt verwendet das Frontend-Maven-Plugin von Eirik Sletteberg, das es unserem Team ermöglicht, ein einziges Plugin für Frontend- und Backend-Builds in einem einzigen Repo zu verwenden. Dieses Plugin ist für verschiedene Konfigurationen geeignet, aber die in diesem Projekt verwendete Konfiguration beschränkt sich auf die Verwendung von Webpack und wenigen Konfigurationen zur Installation von Node und NPM. Der Kern dieser Verwendung stammt aus der Erstellung des Projektpakets, das mithilfe eines <script> im Stammverzeichnis der React-Anwendung (typische React-Methode) integriert wird und in der Datei index.html im Springboot-Ressourcenordner verfügbar gemacht wird.
<body>
<div id='root'>
</div>
<script src="built/bundle.js"></script>
</body>
Webpack erstellt ein Build-Bundle, das die Quelle für den React-Anwendungseintrag in app.js unter dem js -Paket dieses Projekts enthält.
entry: path.resolve(__dirname, "/src/main/js/app.js"),
devtool: 'inline-source-map',
cache: true,
mode: 'development',
output: {
path: __dirname,
filename: 'src/main/resources/static/built/bundle.js'
},
(zurück nach oben)
Wenn Sie Kafka ausführen, sollten Sie die Dokumente lesen. Stellen Sie zunächst sicher, dass der Zoo-Keeper-Server ausgeführt wird, bevor Sie den Kafka-Server ausführen. Manchmal ist der Zookeeper-Konfigurationsordner /config nicht richtig eingerichtet. Stellen Sie bei Bedarf sicher, dass clientPort=2181 in zookeeper.properties festgelegt ist, und stellen Sie sicher, dass in derselben Datei admin.serverPort=8083 festgelegt ist, um sicherzustellen, dass Ports nicht miteinander in Konflikt stehen. Wir möchten auch sicherstellen, dass bootstrap.servers=9092 in producer.properties konfiguriert ist: Dies ist eine Liste von Brokern, die zum Bootstrapping von Wissen über den Rest des Clusterformats verwendet werden, das für die folgende Springboot-Konfiguration dieses Projekts wichtig ist:
@Bean
public ConsumerFactory<String, OpenSentTaskStatus> consumerFactory() {
Map<String, Object> configurationProperties = new HashMap<>();
configurationProperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
configurationProperties.put(ConsumerConfig.GROUP_ID_CONFIG, "group_id");
configurationProperties.put(JsonDeserializer.TRUSTED_PACKAGES, "*");
configurationProperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configurationProperties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
configurationProperties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
return new DefaultKafkaConsumerFactory<>(configurationProperties);
}
@Bean
public ProducerFactory<String, OpenSentTaskStatus> producerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return new DefaultKafkaProducerFactory<>(props);
}
Eine vollständige Liste der vorgeschlagenen Funktionen (und bekannten Probleme) finden Sie in den offenen Problemen.
(zurück nach oben)
(zurück nach oben)
Wali Morris – @LinkedIn – [email protected]
Projektlink: GitHub
(zurück nach oben)
(zurück nach oben)


