content dicovery platform gcp
1.0.0
Dieses Repository enthält den Code und die Automatisierung, die zum Aufbau einer einfachen Content-Discovery-Plattform erforderlich sind, die auf den VertexAI-Grundmodellen basiert. Diese Plattform sollte in der Lage sein, Dokumentinhalte (zunächst Google Docs) zu erfassen und mit diesen Inhalten Einbettungsvektoren zu generieren, die in einer von der VertexAI Matching Engine betriebenen Vektordatenbank gespeichert werden. Später können diese Einbettungen verwendet werden, um eine allgemeine Frage eines externen Verbrauchers zu kontextualisieren und mit Dieser Kontext fordert eine Antwort auf ein VertexAI-Grundmodell an, um eine Antwort zu erhalten.
Die Plattform kann in vier Hauptkomponenten unterteilt werden: Zugriffsdienstschicht, Content-Capture-Pipeline, Content-Speicher und LLMs. Die Dienstschicht ermöglicht es externen Verbrauchern, Anfragen zur Dokumentenaufnahme zu senden und später Anfragen zu den Inhalten zu senden, die in den zuvor aufgenommenen Dokumenten enthalten sind. Die Content-Capture-Pipeline ist dafür verantwortlich, den Inhalt des Dokuments in NRT zu erfassen, Einbettungen zu extrahieren und diese Einbettungen mit echtem Inhalt abzubilden, der später zur Kontextualisierung der Fragen externer Benutzer an ein LLM verwendet werden kann. Die Inhaltsspeicherung ist in drei verschiedene Zwecke unterteilt: LLM-Feinabstimmung, Online-Einbettungsabgleich und Chunked Content, die jeweils von einem speziellen Speichersystem verwaltet werden und dem allgemeinen Zweck dienen, die Informationen zu speichern, die von den Plattformkomponenten zur Implementierung der Aufnahme und Abfrage benötigt werden verwendet Fälle. Zu guter Letzt nutzt die Plattform zwei spezialisierte LLMs, um Echtzeit-Einbettungen aus den aufgenommenen Dokumentinhalten zu erstellen, und ein weiteres LLM, das für die Generierung der von den Plattformbenutzern angeforderten Antworten zuständig ist.
Alle zuvor beschriebenen Komponenten werden mithilfe öffentlich verfügbarer GCP-Dienste implementiert. Um sie aufzuzählen: Cloud Build, Cloud Run, Cloud Dataflow, Cloud Pubsub, Cloud Storage, Cloud Bigtable, Vertex AI Matching Engine, Vertex AI Fundamental-Modelle (Einbettungen und Text-Bison) sowie Google Docs und Google Drive als Inhaltsinformationen Quellen.
Das nächste Bild zeigt, wie die verschiedenen Komponenten der Architektur und Technologien miteinander interagieren.
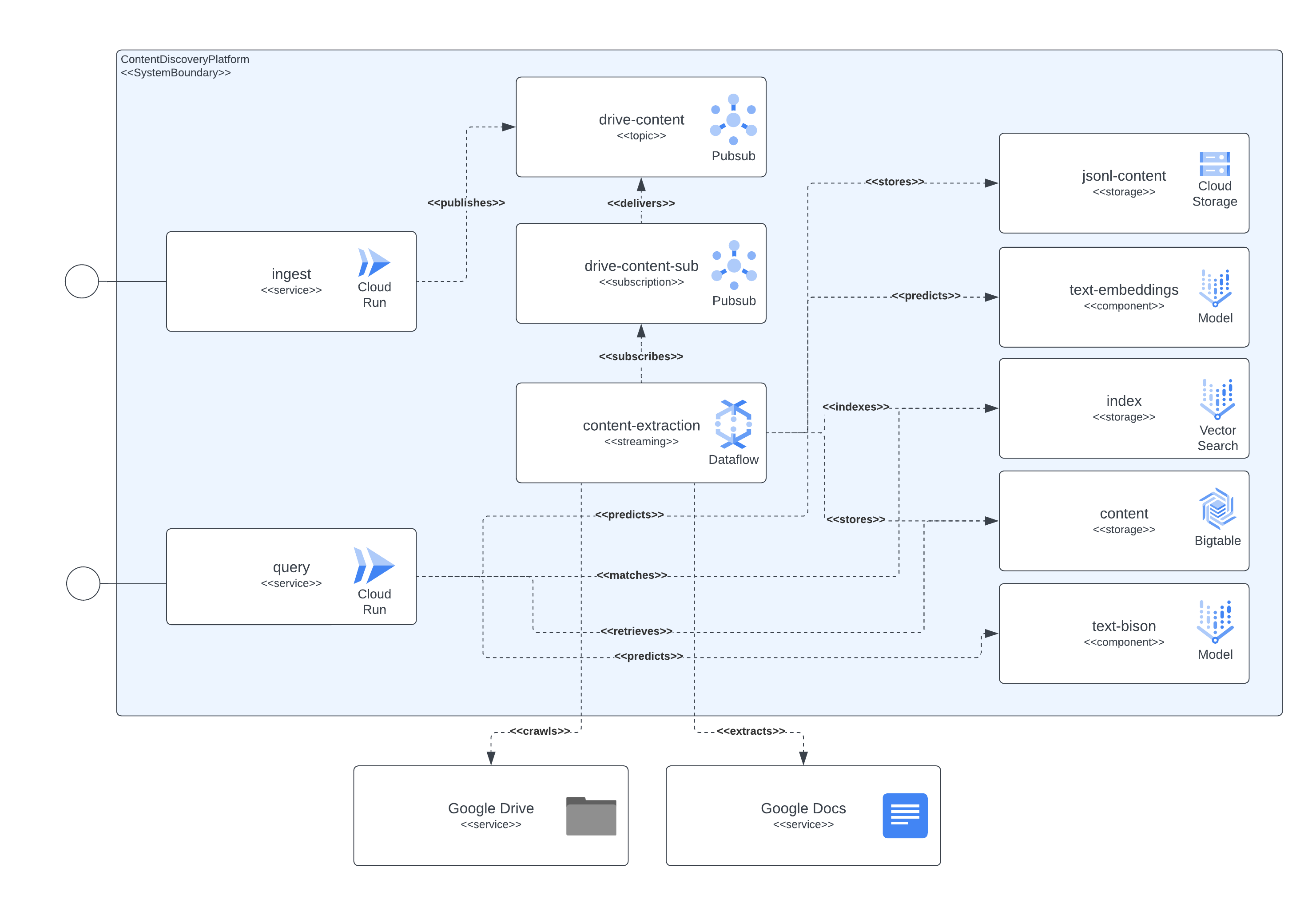
Diese Plattform verwendet Terraform für die Einrichtung aller ihrer Komponenten. Für diejenigen, die derzeit keine native Unterstützung haben, haben wir null_resource-Wrapper erstellt. Dies sind gute Workarounds, aber sie neigen dazu, sehr Ecken und Kanten zu haben, also seien Sie sich möglicher Fehler bewusst.
Die vollständige Bereitstellung ab heute (Juni 2023) kann bis zu 90 Minuten dauern. Der größte Übeltäter sind die Matching Engine-bezogenen Komponenten, deren Erstellung und sofortige Verfügbarkeit den größten Teil dieser Zeit in Anspruch nimmt. Mit der Zeit werden sich diese verlängerten Laufzeiten nur verbessern.
Das Setup sollte über die im Repository enthaltenen Skripte ausführbar sein.
Für die Bereitstellung dieser Plattform müssen einige Voraussetzungen erfüllt sein:
Damit alle Komponenten in der GCP bereitgestellt werden können, müssen wir die Infrastruktur aufbauen und später die Dienste und Pipelines bereitstellen.
Um dies zu erreichen, haben wir das Skript start.sh eingefügt, das im Grunde die anderen enthaltenen Skripte orchestriert, um das vollständige Bereitstellungsziel zu erreichen.
Außerdem haben wir ein cleanup.sh -Skript eingefügt, das für die Zerstörung der Infrastruktur und die Bereinigung der gesammelten Daten verantwortlich ist.
Im Normalfall werden die Google Workspace-Dokumente in derselben Organisation erstellt, die das Projekt hostet, in dem die Inhaltsaufnahme-Pipeline ausgeführt wird. Um Berechtigungen für diese Dokumente zu erteilen, fügen Sie den Dokumenten oder Dokumentenordnern das Dienstkonto hinzu, das die Pipeline ausführt , sollte ausreichen.
Falls Sie auf Dokumente oder Ordner zugreifen müssen, die außerhalb der Projektorganisation vorhanden sind, sollte ein zusätzlicher Schritt durchgeführt werden. Sobald die Infrastruktur eingerichtet ist, druckt der Bereitstellungsprozess Anweisungen aus, um dem Dienstkonto, das die Inhaltsextraktionspipeline ausführt, Berechtigungen zu erteilen, um durch domänenweite Delegation den Zugriff auf Google Workspace-Dokumente zu imitieren. Die Informationen zum Ausführen der Schritte finden Sie hier: https://developers.google.com/workspace/guides/create-credentials#optional_set_up_domain-wide_delegation_for_a_service_account
Die Lösung stellt über GCP CloudRun und API Gateway eine Reihe von Ressourcen bereit, die zur Interaktion für Inhaltsaufnahme- und Inhaltserkennungsabfragen verwendet werden können. In allen Beispielen verwenden wir die symbolische Zeichenfolge <service-address> , die nach Abschluss der Dienstbereitstellung durch die von CloudRun ( backend_service_url aus der Terraform-Ausgabe) oder API Gateway ( sevice_url aus der Terraform-Ausgabe) bereitgestellte URL ersetzt werden sollte.
Wenn CORS-Interaktionen erforderlich sind, können die API-Gateway-Endpunkte verwendet werden, um ein Preflight-Protokoll abzuschließen. CloudRun unterstützt derzeit keine nicht authentifizierten OPTIONS -Befehle, aber die über API Gateway bereitgestellten Pfade unterstützen sie.
Dieser Dienst ist in der Lage, Daten aus in Google Drive gehosteten Dokumenten oder eigenständigen mehrteiligen Anfragen aufzunehmen, die eine Dokumentkennung und den binär codierten Inhalt des Dokuments enthalten.
Die Google Drive-Aufnahme erfolgt durch Senden einer HTTP-Anfrage ähnlich dem nächsten Beispiel
$ > curl -X POST -H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /ingest/content/gdrive
-d $' {"url":"https://docs.google.com/document/d/somevalid-googledocid"} ' Diese Anfrage gibt an, dass die Plattform das Dokument von der bereitgestellten url abrufen soll. Falls das Dienstkonto, das die Aufnahme ausführt, über Zugriffsberechtigungen für das Dokument verfügt, extrahiert es den Inhalt daraus und speichert die Informationen zur Indizierung, späteren Erkennung und zum Abruf.
Die Anfrage kann die URL eines Google-Dokuments oder eines Google Drive-Ordners enthalten. Im letzten Fall wird bei der Aufnahme der Ordner nach zu verarbeitenden Dokumenten durchsucht. Es ist auch möglich, die Eigenschafts urls zu verwenden, die ein JSONArray mit string erwarten, von denen jeder eine gültige Google-Dokument-URL ist.
Wenn Sie den Inhalt eines Artikels, Dokuments oder einer Seite einbinden möchten, auf die der Aufnahme-Client lokal zugreifen kann, sollte die Verwendung des Multipart-Endpunkts für die Aufnahme des Dokuments ausreichen. Sehen Sie sich den nächsten curl -Befehl als Beispiel an. Der Dienst erwartet, dass das Formularfeld documentId festgelegt ist, um den Inhalt zu identifizieren und eindeutig zu indizieren:
$ > curl -H " Authorization: Bearer $( gcloud auth print-identity-token ) "
-F documentId= < somedocid >
-F documentContent=@ < /some/local/directory/file/to/upload >
https:// < service-address > /ingest/content/multipartDieser Dienst stellt den Benutzern der Plattform die Abfragefunktion zur Verfügung, indem er natürliche Textabfragen an die Dienste sendet. Sofern nach der Aufnahme in die Plattform bereits Inhaltsindizes vorhanden sind, stellt der Dienst Informationen zur Verfügung, die durch das LLM-Modell zusammengefasst wurden.
Die Interaktion mit dem Dienst kann über einen REST-Austausch erfolgen, ähnlich wie für den Aufnahmeteil, wie im nächsten Beispiel dargestellt.
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": ""} '
| jq .
# response from service
{
"content": "VertexAI foundational models are a set of pre-trained models that can be used to build and deploy machine learning applications. They are available in a variety of languages and frameworks, and can be used for a variety of tasks, including natural language processing, computer vision, and recommendation systems.nnVertexAI foundational models are a good choice for Generative AI applications because they provide a starting point for building these types of applications. They can be used to quickly and easily create models that can generate text, images, and other types of content.nnIn addition, VertexAI foundational models are scalable and can be used to process large amounts of data. They are also reliable and can be used to create applications that are available 24/7.nnOverall, VertexAI foundational models are a powerful tool for building Generative AI applications. They provide a starting point for building these types of applications, and they can be used to quickly and easily create models that can generate text, images, and other types of content.",
" sourceLinks " : [
]
}Hier gibt es einen Sonderfall, bei dem für ein bestimmtes Thema noch keine Informationen gespeichert sind. Wenn dieses Thema in die GCP-Landschaft fällt, fungiert das Modell als Experte, da wir eine Eingabeaufforderung einrichten, die dies der Modellanfrage mitteilt.
Wenn Sie eine kontextbezogenere Art des Austauschs mit dem Dienst wünschen, sollte eine Sitzungskennung ( sessionId Eigenschaft in der JSON-Anfrage) bereitgestellt werden, die der Dienst als Konversationsaustauschschlüssel verwenden kann. Dieser Konversationsschlüssel wird verwendet, um den richtigen Kontext für das Modell einzurichten (durch Zusammenfassung früherer Austausche) und um (mindestens) die letzten fünf Austausche zu verfolgen. Beachten Sie auch, dass der Austauschverlauf 24 Stunden lang gespeichert wird. Dies kann im Rahmen der GC-Richtlinien des BigTable-Speichers auf der Plattform geändert werden.
Als nächstes ein Beispiel für ein kontextbezogenes Gespräch:
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " VertexAI Foundational Models are a suite of pre-trained models that can be used to accelerate the development of Generative AI applications. These models are available in a variety of languages and domains, and they can be used to generate text, images, audio, and other types of content.nnUsing VertexAI Foundational Models can help you to:nn* Reduce the time and effort required to develop Generative AI applicationsn* Improve the accuracy and quality of your modelsn* Access the latest research and development in Generative AInnVertexAI Foundational Models are a powerful tool for developers who want to create innovative and engaging Generative AI applications. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"describe the available LLM models?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models suite includes a variety of LLM models, including:nn* Text-to-text LLMs: These models can generate text based on a given prompt. They can be used for tasks such as summarization, translation, and question answering.n* Image-to-text LLMs: These models can generate text based on an image. They can be used for tasks such as image captioning and description generation.n* Audio-to-text LLMs: These models can generate text based on an audio clip. They can be used for tasks such as speech recognition and transcription.nnThese models are available in a variety of languages, including English, Spanish, French, German, and Japanese. They can be used to create a wide range of Generative AI applications, such as chatbots, customer service applications, and creative writing tools. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"do rate limit apply for those LLMs?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " Yes, there are rate limits for the VertexAI Foundational Models. The rate limits are based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models documentation](https://cloud.google.com/vertex-ai/docs/foundational-models#rate-limits). " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"care to share the price?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models are priced based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models pricing page](https://cloud.google.com/vertex-ai/pricing#foundational-models). " ,
" sourceLinks " : [
]
}

