PersonalAIserver
1.0.0
Richten Sie einen GenAI-Server auf Ihrer eigenen verfügbaren Hardware ein. Dieses Projekt bietet eine Webschnittstelle zur Interaktion mit LLaMA- und Stable Diffusion-Modellen (unter anderem) zur Text-, Bild-, Video- und 3D-Generierung.
Viele Leute haben eine schöne GPU zur Hand und sind bereit, diese zu nutzen, anstatt für Abonnements von OpenAI, Anthropic usw. zu bezahlen. Hier können Sie Ihre eigenen KI-Modelle hosten, wenn auch mit vielen Einschränkungen im Vergleich zu diesen großartigen Diensten. Anschließend können Sie von überall mit einem Webbrowser darauf zugreifen, beispielsweise von Ihrem Telefon oder einem anderen Computer.
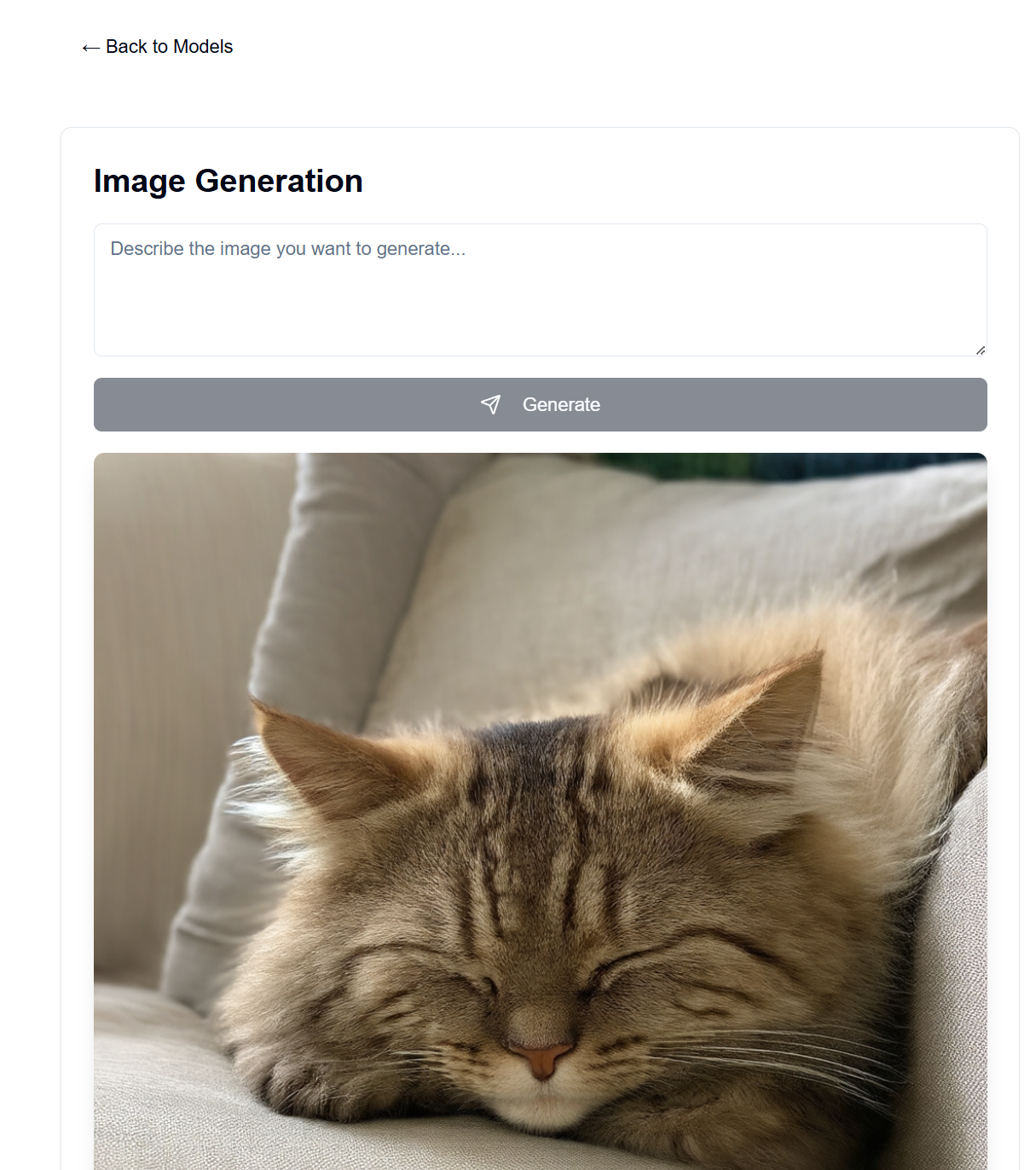
Das Frontend hierfür wird auf GitHub Pages gehostet, während das Backend auf Ihrem verfügbaren Serverrechner gehostet wird.
Nach der Einrichtung ist das Frontend unter https://[username].github.io/PersonalAIserver verfügbar. Befolgen Sie die nachstehenden Anweisungen, um das Backend einzurichten.
Für das Frontend muss lediglich eine GitHub-Aktion eingerichtet werden, um die Projektseite zu erstellen. Navigieren Sie in Ihrem geforkten Repository zu Settings -> Pages -> Source und stellen Sie es auf „GitHub Actions“ ein. Dank der Datei .github/workflows/main.yml wird der Build automatisch ausgeführt, wenn Sie ihn in das Repository übertragen.
Wenn Sie das Frontend lokal ausführen möchten, befolgen Sie die nachstehenden Anweisungen. Erfordert Node.js, installierbar über den Node Version Manager (NVM).
nvm install 20
npm install -D @shadcn/ui
npx shadcn@latest init # Select default style, any color, and dont use css variables.
npx shadcn@latest add alert button card input textarea # Accept defaults
npm install lucide-react
npm install -D @tailwindcss/typography
npm install clsx tailwind-merge
npm install
npm install sharp
npm run dev
Dies sollte das Frontend unter http://localhost:3000 bedienen, auf das Sie mit einem Webbrowser zugreifen können.
Dies nutzt Conda für die Paketverwaltung, Sie können aber auch jeden anderen Paketmanager verwenden.
Führen Sie in Ihrem Terminal im Backend-Verzeichnis die folgenden Befehle aus:
conda create -n personalai python=3.11
conda activate personalai
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
pip install -r requirements.txt
users.json mit dem folgenden Format: {
"username1": {
"username": "username1",
"password": "password1",
"disabled": false
},
"username2": {
"username": "username2",
"password": "password2",
"disabled": false
}
...
}
.secret Datei mit einer zufälligen Zeichenfolge Ihrer Wahl. Dies wird zur Verschlüsselung des JWT-Tokens verwendet. Ich empfehle, eines zu erstellen mit: import secrets
secret_key = secrets.token_hex(32)
print(secret_key)
und dann die Ausgabe kopieren.
Settings -> Secrets and variables -> ActionsNEXT_PUBLIC_API_URL und dem Wert der URL des Backend-Servers hinzu (weitere Details unten). Beispiel: https://api.example.com .backend/backend.py die CORSMiddleware in der Nähe von Zeile 40 an, um die URLs Ihres Frontends einzuschließen.huggingface-cli login bei Hugging Face an und verwenden Sie Ihr oben erstelltes persönliches Zugangstoken als Passwort.python backend/backend.py --public aus oder entfernen Sie --public , wenn Sie den Server nur auf localhost ausführen möchten. Localhost erfordert, dass Sie das Frontend auch lokal ausführen.Es gibt viele Möglichkeiten, das Backend unter einer öffentlichen URL zu hosten, ich empfehle jedoch die Verwendung von Cloudflare Tunnel. Cloudflare Tunnel leitet Datenverkehr aus dem Internet an Ihren Server weiter, ohne einen Port oder Ihre lokale IP preiszugeben. Es unterstützt außerdem HTTPS, SSL-Verschlüsselung und DDoS-Schutz sowie weitere Sicherheitsfunktionen, die Sie sonst selbst einrichten und warten müssten.
Weitere Optionen sind:
Für Cloudflare Tunnel benötigen Sie einen Domänennamen und ein Cloudflare-Konto.
cloudflared tunnel login aus. Dieser Schritt öffnet ein Browserfenster, in dem Sie sich mit Ihrem Cloudflare-Konto anmelden können.cloudflared tunnel create genai-api . Dieser Schritt generiert eine Tunnel-ID. Beachten Sie dies für die nächsten Schritte. tunnel: <your-tunnel-id>
credentials-file: /home/user/.cloudflared/<tunnel-id>.json
ingress:
- hostname: <your-api-url>
service: http://localhost:8000
- service: http_status:404
Die <your-api-url> sollte der Domänenname sein, den Sie bei den Nameservern von Cloudflare registriert haben, und kann eine Subdomäne sein. Wenn Sie beispielsweise example.com besitzen, können Sie genai.example.com oder api.example.com verwenden. 5. Erstellen Sie den DNS-Eintrag cloudflared tunnel route dns <tunnel-id> <your-api-url> . Dadurch wird der Tunnel für Cloudflare erstellt, um Datenverkehr aus dem Internet an Ihren Server weiterzuleiten, ohne einen Port oder Ihre lokale IP preiszugeben.
In backend/backend.py können Sie die verwendeten Modelle ändern. Suchen Sie auf Hugging Face das Modell, das Sie für die Text-/Bildgenerierung verwenden möchten, und passen Sie die ModelManager -Modellkonfigurationen an (Zeile ~127). Standardmäßig wird das LLaMA 3.2-1B-Instruct-Modell für die Textgenerierung und das Stable Diffusion 3.5-Mediummodell für die Bildgenerierung verwendet. Nachfolgend sind die VRAM-Anforderungen für jedes getestete Modell aufgeführt.
| Modelltyp | Modellname | VRAM-Nutzung (GB) | Notizen |
|---|---|---|---|
| Text | meta-llama/Llama-3.2-1B-Instruct | ~8 | Basismodell zur Textgenerierung |
| Bild | Stabilitätai/stable-diffusion-3.5-medium | ~13 | Funktioniert gut auf RTX 4090 |
| Bild | Stabilitätai/stabile Diffusion-3,5-groß | ~20-30 | Übersteigt 4090 VRAM für lange Eingabeaufforderungen |
Hinweis: Die VRAM-Nutzung kann je nach Bildauflösung, Länge der Textaufforderungen und anderen Parametern variieren. Die angezeigten Werte sind ungefähre Werte für die Standardeinstellungen. Quantisierte Transformatormodelle werden unterstützt, um die VRAM-Nutzung weiter zu reduzieren, werden jedoch nicht standardmäßig verwendet (siehe backend/backend.py Zeilen 178–192). Das große stabile Diffusionsmodell passt mit Quantisierung kaum in den VRAM meines 4090. Die Chatbot-Geschwindigkeiten sind auf meinem 4090 extrem hoch, wobei die Bilderzeugung bei 1024x1024-Bildern bis zu 30 Sekunden für 100 Schritte dauert.
Die Systemeingabeaufforderung für das Sprachmodell finden Sie in backend/system_prompt.txt . Derzeit handelt es sich um eine Weiterentwicklung des Claude 3.5 Sonnet-Modells von Anthropic, das am 22. Oktober 2024 veröffentlicht wurde. https://docs.anthropic.com/en/release-notes/system-prompts#claude-3-5-sonnet


