nvidia llm
1.0.0
NVIDIA LLM API ist eine Proxy-KI-Inferenz-Engine, die eine breite Palette von Modellen verschiedener Anbieter bietet.
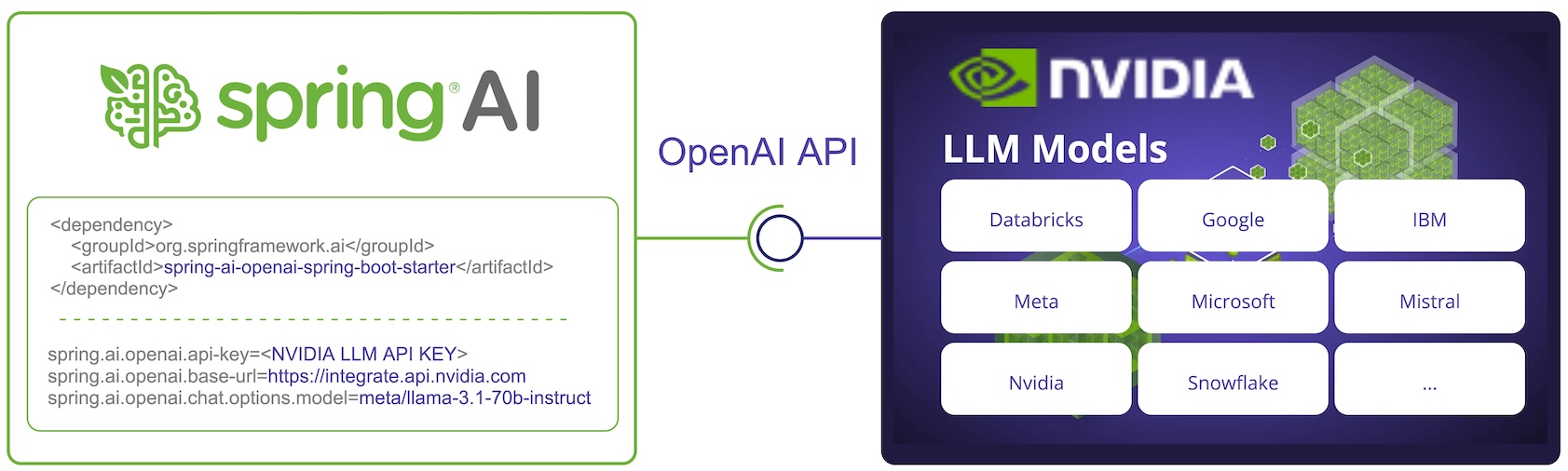
Spring AI lässt sich in die NVIDIA LLM-API integrieren, indem der vorhandene Spring AI OpenAI-Client wiederverwendet wird.
Dazu müssen Sie die Basis-URL auf https://integrate.api.nvidia.com setzen und eine der bereitgestellten https://docs.api.nvidia.com/nim/reference/llm-apis#model[ auswählen. LLM-Modelle] und erhalten Sie einen api-key dafür.
HINWEIS: Für die NVIDIA LLM-API muss der Parameter max-token explizit festgelegt werden, andernfalls wird ein Serverfehler ausgegeben.
Weitere Informationen finden Sie in der SpringAI/NVIDIA-Referenzdokumentation: https://docs.spring.io/spring-ai/reference/api/chat/nvidia-chat.html


