cassandra lucene index
2.1.20.0
Der Cassandra Lucene Index von Stratio, abgeleitet von Stratio Cassandra, ist ein Plugin für Apache Cassandra, das seine Indexfunktionalität erweitert, um nahezu Echtzeitsuche wie ElasticSearch oder Solr bereitzustellen, einschließlich Volltextsuchfunktionen und kostenloser multivariabler, raumbezogener und bitemporaler Suche. Dies wird durch eine auf Apache Lucene basierende Implementierung von Cassandra-Sekundärindizes erreicht, bei der jeder Knoten des Clusters seine eigenen Daten indiziert. Die Cassandra-Indizes von Stratio sind eines der Kernmodule, auf denen die BigData-Plattform von Stratio basiert.
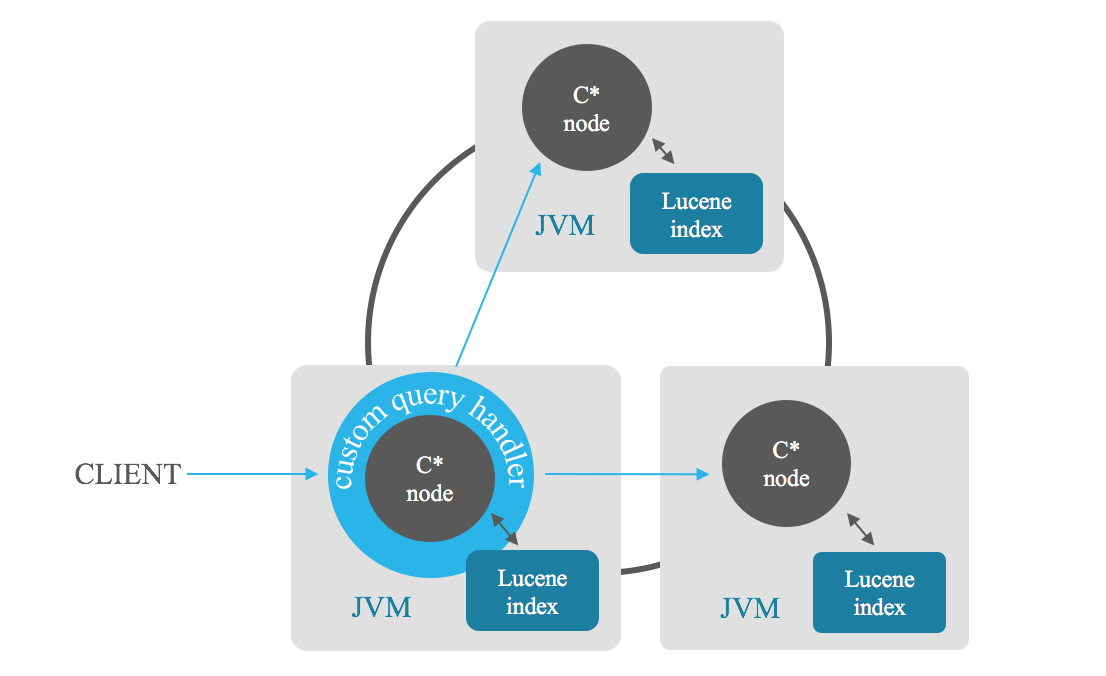
Mit Indexrelevanzsuchen können Sie die n relevanteren Ergebnisse abrufen, die einer Suche entsprechen. Der Koordinatorknoten sendet die Suche an jeden Knoten im Cluster, jeder Knoten gibt seine n besten Ergebnisse zurück und dann kombiniert der Koordinator diese Teilergebnisse und gibt Ihnen die n besten davon aus, wodurch ein vollständiger Scan vermieden wird. Sie können die Sortierung auch auf einer Kombination von Feldern basieren lassen.
Jede Zelle in den Tabellen kann indiziert werden, einschließlich der Zellen im Primärschlüssel und in Sammlungen. Auch breite Zeilen werden unterstützt. Sie können Token-/Schlüsselbereiche scannen, zusätzliche CQL3-Klauseln anwenden und die gefilterten Ergebnisse durchblättern.
Indexgefilterte Suchen sind eine leistungsstarke Hilfe bei der Analyse der in Cassandra gespeicherten Daten mit MapReduce-Frameworks wie Apache Hadoop oder, noch besser, Apache Spark. Durch das Hinzufügen von Lucene-Filtern zur Auftragseingabe kann die zu verarbeitende Datenmenge drastisch reduziert und ein vollständiger Scan vermieden werden.
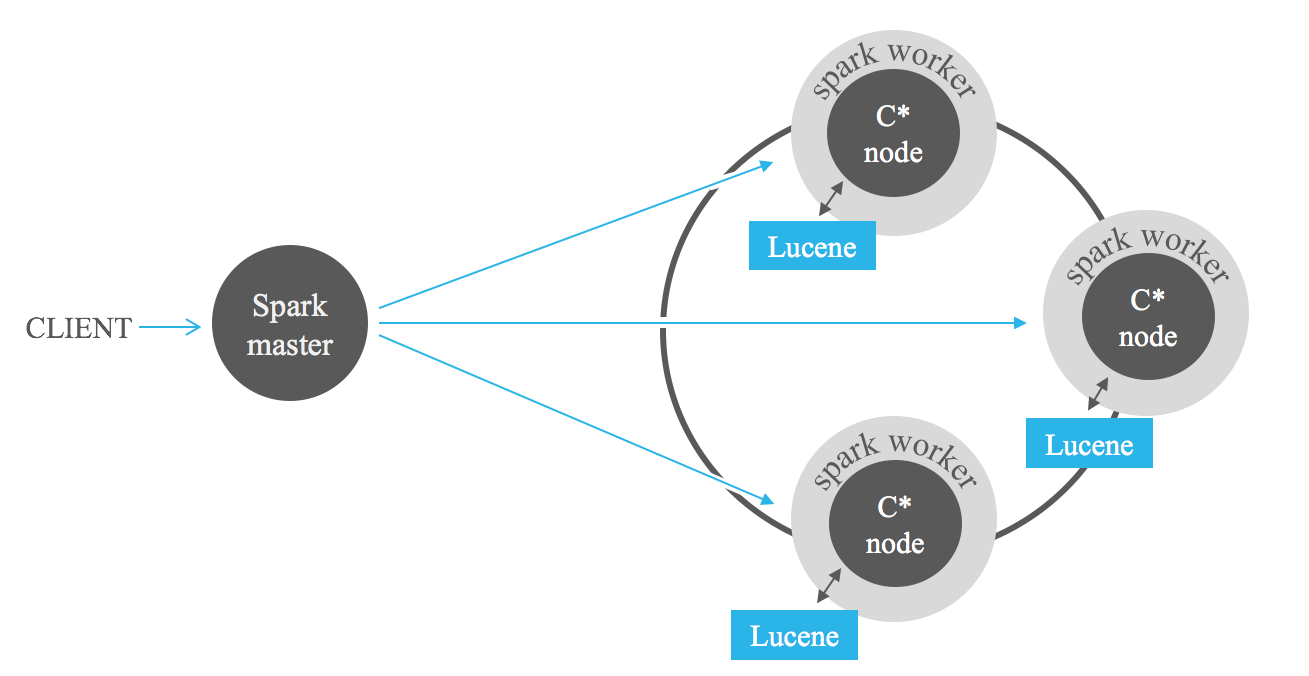
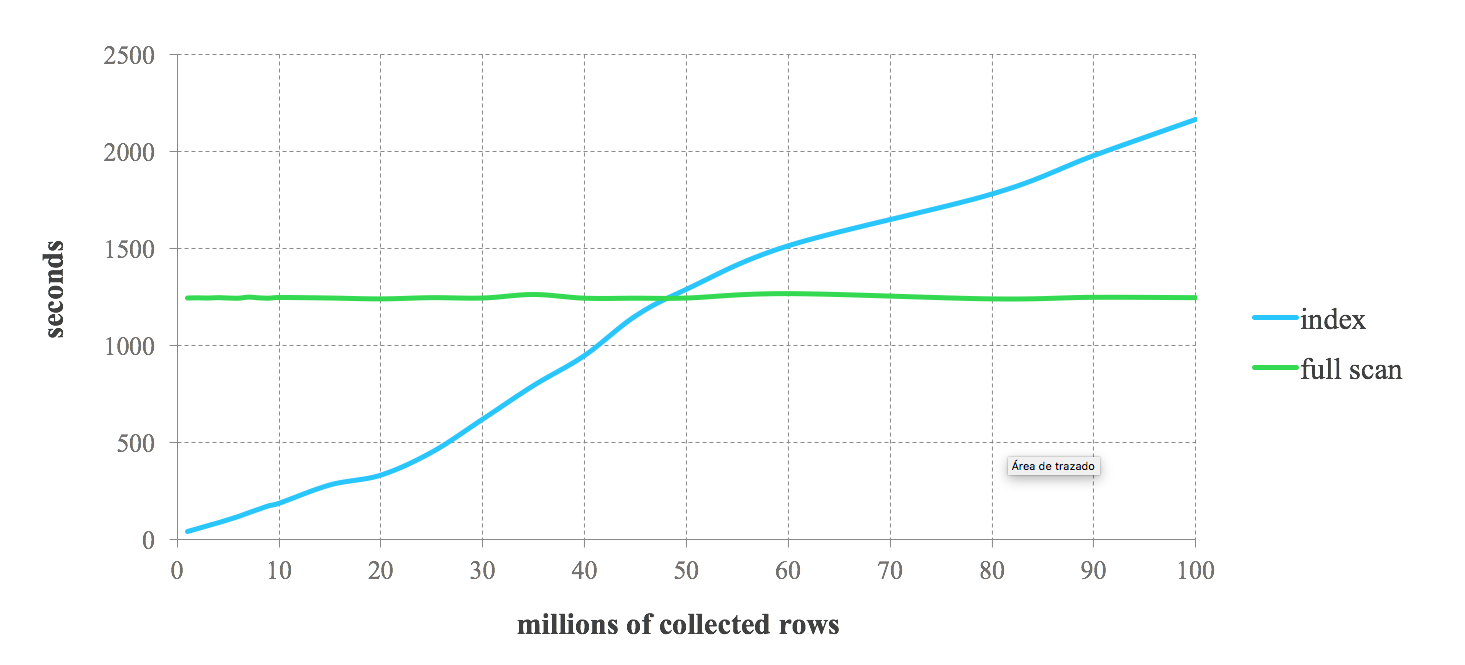
Das folgende Benchmark-Ergebnis kann Ihnen einen Eindruck von der erwarteten Leistung bei der Kombination von Lucene-Indizes mit Spark geben. Wir führen aufeinanderfolgende Abfragen durch und fordern 1 % bis 100 % der gespeicherten Daten an. Wir können eine hohe Leistung des Index bei Abfragen feststellen, die stark gefilterte Daten anfordern. Bei weniger restriktiven Abfragen nimmt die Leistung jedoch ab. Wenn die Anzahl der von der Abfrage zurückgegebenen Datensätze zunimmt, erreichen wir einen Punkt, an dem der Index langsamer wird als der vollständige Scan. Die Entscheidung, Indizes in Ihren Spark-Jobs zu verwenden, hängt also von der Abfrageselektivität ab. Der Kompromiss zwischen beiden Ansätzen hängt vom jeweiligen Anwendungsfall ab. Im Allgemeinen wird die Kombination von Lucene-Indizes mit Spark für Jobs empfohlen, die nicht mehr als 25 % der gespeicherten Daten abrufen.
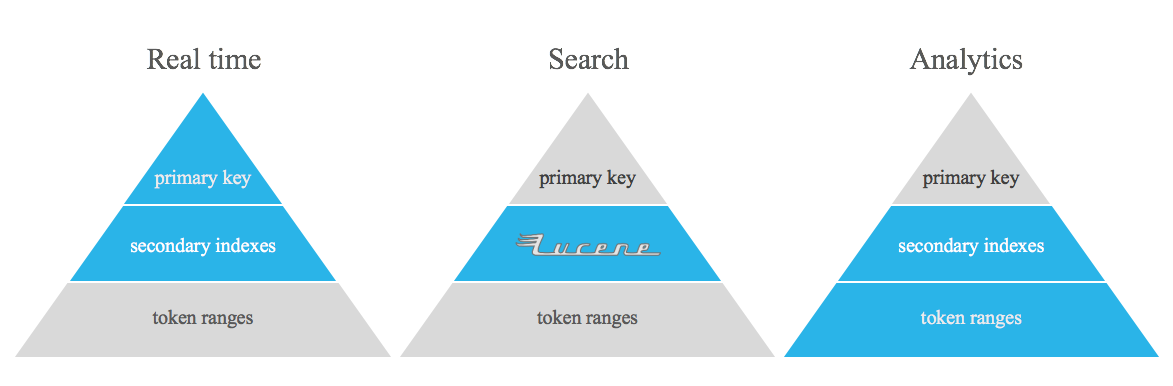
Dieses Projekt ist nicht dazu gedacht, denormalisierte Apache Cassandra-Tabellen, invertierte Indizes und/oder sekundäre Indizes zu ersetzen. Es handelt sich lediglich um ein Tool zum Durchführen bestimmter Abfragen, die mit den sofort einsatzbereiten Funktionen von Apache Cassandra nur schwer zu beantworten sind und die Lücke zwischen Echtzeit und Analyse schließen.
Ausführlichere Informationen finden Sie in der Dokumentation zum Cassandra Lucene Index von Stratio.
Die Integration der Lucene-Suchtechnologie in Cassandra bietet:
Der Cassandra Lucene Index von Stratio und seine Integration mit der Lucene-Suchtechnologie bieten:
Noch nicht unterstützt:
counterDer Cassandra Lucene Index von Stratio wird als Plugin für Apache Cassandra vertrieben. Sie müssen also nur ein JAR erstellen, das das Plugin enthält, und es zum Klassenpfad von Cassandra hinzufügen:
git clone http://github.com/Stratio/cassandra-lucene-indexcd cassandra-lucene-indexgit checkout ABCXmvn clean packagecp plugin/target/cassandra-lucene-index-plugin-*.jar <CASSANDRA_HOME>/lib/Bestimmte Cassandra Lucene-Indexversionen sind auf bestimmte Apache Cassandra-Versionen ausgerichtet. Daher soll cassandra-lucene-index ABCX mit Apache Cassandra ABC verwendet werden, z. B. cassandra-lucene-index:3.0.7.1 für cassandra:3.0.7. Bitte beachten Sie, dass es sich bei produktionsbereiten Releases um Versions-Tags handelt (z. B. 3.0.6.3). Verwenden Sie weder Branch-X noch Master-Branches in der Produktion.
Alternativ kann das Patchen auch mit diesem Maven-Profil durchgeführt werden, indem Sie den Pfad Ihrer Cassandra-Installation angeben. Diese Aufgabe löscht auch die JAR-Versionen früherer Plugins im Verzeichnis CASSANDRA_HOME/lib/:
mvn clean package -Ppatch -Dcassandra_home= < CASSANDRA_HOME >Wenn Sie keine installierte Version von Cassandra haben, gibt es auch ein alternatives Profil, mit dem Maven die richtige Version von Apache Cassandra herunterladen und patchen kann:
mvn clean package -Pdownload_and_patch -Dcassandra_home= < CASSANDRA_HOME >Jetzt können Sie Cassandra ausführen und einige Tests mit der Cassandra Query Language durchführen:
< CASSANDRA_HOME > /bin/cassandra -f
< CASSANDRA_HOME > /bin/cqlsh Die Indexdateien von Lucene werden in denselben Verzeichnissen gespeichert wie die von Cassandra. Das Standarddatenverzeichnis ist /var/lib/cassandra/data und jeder Index wird neben den SSTables seiner indizierten Spaltenfamilie platziert.
Denken Sie daran, dass Sie bei Verwendung der Geo-Shape-Suche das JTS-JAR einbeziehen müssen.
Weitere Informationen zu Apache Cassandra finden Sie in der Dokumentation.
Wir erstellen die folgende Tabelle zum Speichern von Tweets:
CREATE KEYSPACE demo
WITH REPLICATION = { ' class ' : ' SimpleStrategy ' , ' replication_factor ' : 1 };
USE demo;
CREATE TABLE tweets (
id INT PRIMARY KEY ,
user TEXT ,
body TEXT ,
time TIMESTAMP ,
latitude FLOAT,
longitude FLOAT
);Jetzt können Sie mit der folgenden Anweisung einen benutzerdefinierten Lucene-Index dafür erstellen:
CREATE CUSTOM INDEX tweets_index ON tweets ()
USING ' com.stratio.cassandra.lucene.Index '
WITH OPTIONS = {
' refresh_seconds ' : ' 1 ' ,
' schema ' : ' {
fields: {
id: {type: "integer"},
user: {type: "string"},
body: {type: "text", analyzer: "english"},
time: {type: "date", pattern: "yyyy/MM/dd"},
place: {type: "geo_point", latitude: "latitude", longitude: "longitude"}
}
} '
}; Dadurch werden alle Spalten in der Tabelle mit den angegebenen Typen indiziert und einmal pro Sekunde aktualisiert. Alternativ können Sie alle Index-Shards explizit mit einer leeren Suche mit der Konsistenz ALL aktualisieren:
CONSISTENCY ALL
SELECT * FROM tweets WHERE expr(tweets_index, ' {refresh:true} ' );
CONSISTENCY QUORUMSo suchen Sie nun nach Tweets innerhalb eines bestimmten Datumsbereichs:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"}
} ' );Die gleiche Suche kann durchgeführt werden, um eine explizite Aktualisierung der beteiligten Index-Shards zu erzwingen:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
refresh: true
} ' ) limit 100 ;Um nun die 100 relevanteren Tweets zu durchsuchen, in denen das Textfeld den Ausdruck „Big Data gibt Organisationen“ innerhalb des oben genannten Zeitraums enthält:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;So verfeinern Sie die Suche, um nur die Tweets zu erhalten, die von Benutzern geschrieben wurden, deren Namen mit „a“ beginnen:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;Um die 100 neueren gefilterten Ergebnisse zu erhalten, können Sie die Sortieroption verwenden:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;Die bisherige Suche kann auf Tweets eingeschränkt werden, die in der Nähe einer geografischen Position erstellt wurden:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;Es ist auch möglich, die Ergebnisse nach der Entfernung zu einer geografischen Position zu sortieren:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) limit 100 ;Zu guter Letzt können Sie jede Suche an einen bestimmten Tokenbereich oder eine bestimmte Partition weiterleiten, sodass nur eine Teilmenge der Clusterknoten getroffen wird, wodurch wertvolle Ressourcen gespart werden:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) AND TOKEN(id) >= TOKEN( 0 ) AND TOKEN(id) < TOKEN( 10000000 ) limit 100 ;Letzteres ist die Grundlage für die Unterstützung von Hadoop, Spark und anderen MapReduce-Frameworks.
Weitere Informationen finden Sie in der umfassenden Dokumentation zum Cassandra Lucene Index von Stratio.


