ustore
v0.13.12
![]()
![]()
![]()
![]()
![]()
![]()
Youtube-Intro • Discord-Chat • Vollständige Dokumentation
Die Installation von UStore ist ein Kinderspiel und die Verwendung ist ungefähr so einfach wie ein Python- dict .
$ pip install ukv
$ python
from ukv import umem
db = umem . DataBase ()
db . main [ 42 ] = 'Hi' Wir haben gerade eine im Arbeitsspeicher eingebettete Transaktionsdatenbank erstellt und einen Eintrag zu ihrer main hinzugefügt. Möchten Sie die Daten lieber auf der Festplatte haben? Ändern Sie eine Zeile.
from ukv import rocksdb
db = rocksdb . DataBase ( '/some-folder/' )Möchten Sie lieber eine Verbindung zu einem Remote-UStore-Server herstellen? UStore verfügt über eine Apache Arrow Flight RPC-Schnittstelle!
from ukv import flight_client
db = flight_client . DataBase ( 'grpc://0.0.0.0:38709' ) Speichern Sie NetworkX-ähnliches MultiDiGraph ? Oder Pandas-ähnlicher DataFrame ?
db = rocksdb . DataBase ()
users_table = db [ 'users' ]. table
users_table . merge ( pd . DataFrame ([
{ 'id' : 1 , 'name' : 'Lex' , 'lastname' : 'Fridman' },
{ 'id' : 2 , 'name' : 'Joe' , 'lastname' : 'Rogan' },
]))
friends_graph = db [ 'friends' ]. graph
friends_graph . add_edge ( 1 , 2 )
assert friends_graph . has_edge ( 1 , 2 ) and
friends_graph . has_node ( 1 ) and
friends_graph . number_of_edges ( 1 , 2 ) == 1Funktionsaufrufe sehen möglicherweise identisch aus, aber die zugrunde liegende Implementierung kann Hunderte von Terabyte an Daten adressieren, die irgendwo im persistenten Speicher auf einem Remote-Computer abgelegt sind.
Aktualisiert jemand anderes gleichzeitig diese Sammlungen? Bündeln Sie Ihre Abläufe, um Konsistenz zu gewährleisten!
db = rocksdb . DataBase ()
with db . transact () as txn :
txn [ 'users' ]. table . merge (...)
txn [ 'friends' ]. graph . add_edge ( 1 , 2 )Bisher haben wir nur die Spitze des UStore abgedeckt. Sie können es verwenden, um...
Aber UStore kann mehr. Hier ist die Karte:
## Grundlegende Verwendung
UStore ist nicht nur als Datenbank gedacht, sondern als Toolkit zum Erstellen Ihrer Datenbank und als offener Standard für potenziell transaktionale NoSQL-Datenbanken, der Nullkopie-Binärschnittstellen für „Erstellen, Lesen, Aktualisieren, Löschen“-Operationen, kurz CRUD, definiert.
Ein paar einfache C99-Header können fast jede zugrunde liegende Speicher-Engine mit zahlreichen Hochsprachentreibern verknüpfen und ihre Unterstützung für binäre Zeichenfolgenwerte auf Diagramme, flexible Schemadokumente und andere Modalitäten erweitern, um MongoDB, Neo4J, Pinecone und ElasticSearch zu ersetzen mit einem einzigen ACID-Transaktionssystem.
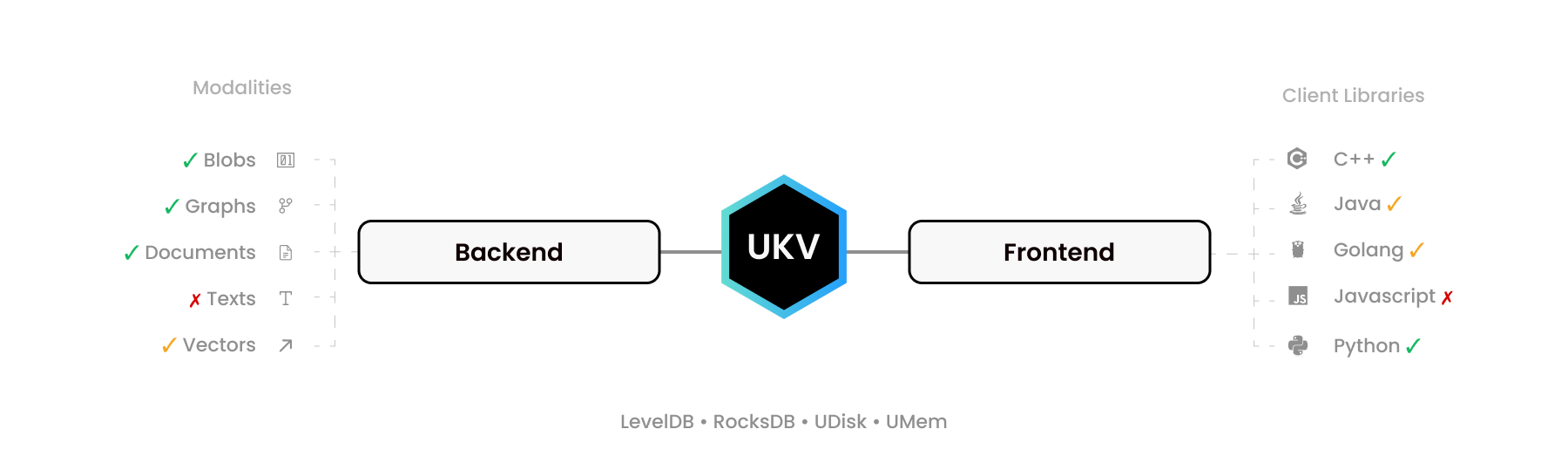
Redis bietet beispielsweise RediSearch, RedisJSON und RedisGraph mit ähnlichen Zielen. UStore macht es besser und ermöglicht Ihnen das Hinzufügen Ihrer bevorzugten Schlüsselwertspeicher (KVS), eingebettet, eigenständig oder fragmentiert, wie z. B. FoundationDB, und vervielfacht so die Funktionalität.
Binäre große Objekte können in UStore platziert werden. Die Leistung variiert stark je nach verwendeter zugrunde liegender Technologie. Das In-Memory-UCSet ist am schnellsten, eignet sich jedoch am wenigsten für größere Objekte. Bei richtiger Konfiguration kann die persistente UDisk den Linux-Kernel, einschließlich der Dateisystemschicht, vollständig umgehen und Blockgeräte direkt ansprechen.
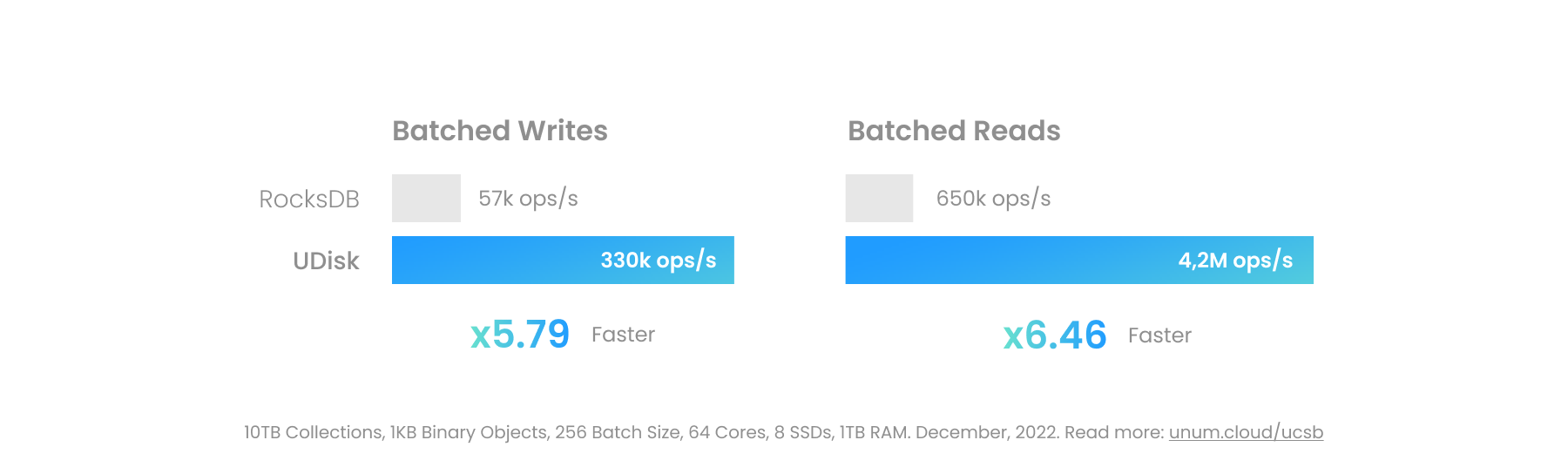
Moderne persistente E/A auf High-End-Servern können 100 GB/s pro Socket überschreiten, wenn sie auf User-Space-Treibern wie SPDK basieren. Dies kommt dem realen Durchsatz von High-End-RAM nahe und erschließt neue, für Datenbanken ungewöhnliche Anwendungsfälle. Man kann jetzt eine Gigabyte-große Videodatei direkt neben ihren Metadaten in einer ACID-Transaktionsdatenbank ablegen, anstatt einen separaten Objektspeicher wie MinIO zu verwenden.
JSON ist heutzutage das am häufigsten verwendete Dokumentformat. UStore-Dokumentsammlungen unterstützen JSON sowie MessagePack und BSON, die von MongoDB verwendet werden.

UStore skaliert noch nicht horizontal, bietet aber eine viel höhere Einzelknotenleistung und verfügt dank der Open-Source-Bibliotheken simdjson und yyjson über eine nahezu lineare vertikale Skalierbarkeit auf Systemen mit vielen Kernen. Darüber hinaus benötigen Sie für die Interaktion mit Daten keine benutzerdefinierte Abfragesprache wie MQL. Stattdessen priorisieren wir offene RFC-Standards, um Anbietersperren wirklich zu vermeiden:
Moderne Graphdatenbanken wie Neo4J haben mit großen Arbeitslasten zu kämpfen. Sie benötigen zu viel RAM und ihre Algorithmen überwachen die Daten jeweils einzeln. Wir optimieren an beiden Fronten:
Feature Stores und Vektordatenbanken wie Pinecone, Milvus und USearch bieten eigenständige Indizes für die Vektorsuche. UStore implementiert es als separate Modalität, gleichwertig mit Dokumenten und Diagrammen. Merkmale:
UStore für Python und für C++ sehen sehr unterschiedlich aus. Unser Python SDK ahmt andere Python-Bibliotheken nach – Pandas und NetworkX. Ebenso stellt die C++-Bibliothek die Schnittstelle bereit, die C++-Entwickler erwarten.
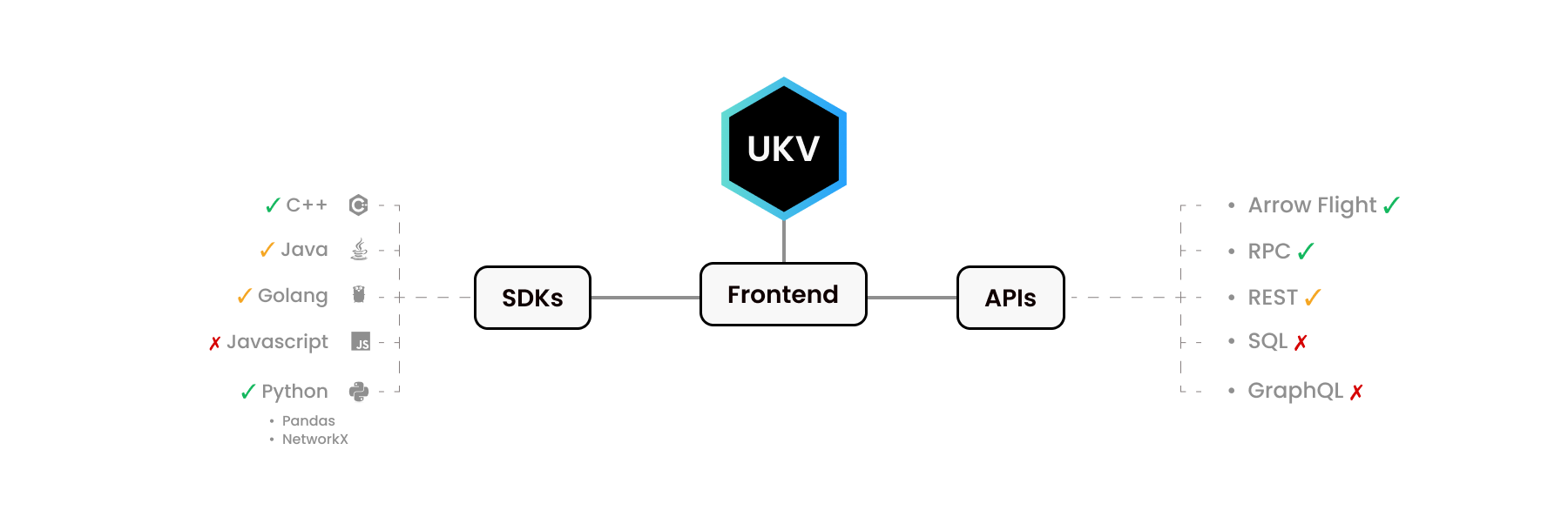
Wie wir wissen, verwenden Menschen unterschiedliche Sprachen für unterschiedliche Zwecke. Einige C-Level-Funktionen sind für einige Sprachen nicht implementiert. Entweder weil es keine Nachfrage gab oder weil wir noch nicht dazu gekommen sind.
| Name | Tätigen | Sammlungen | Chargen | Dokumente | Grafiken | Kopien |
|---|---|---|---|---|---|---|
| C99-Standard | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| C++ SDK | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| Python-SDK | ✓ | ✓ | ✓ | ✓ | ✓ | 0-1 |
| GoLang SDK | ✓ | ✓ | ✓ | ✗ | ✗ | 1 |
| Java SDK | ✓ | ✓ | ✗ | ✗ | ✗ | 1 |
| Arrow Flight API | ✓ | ✓ | ✓ | ✓ | ✓ | 0-2 |
Einige Frontends hier haben ganze Ökosysteme um sich herum! Die Apache Arrow Flight API verfügt beispielsweise über eigene Treiber für C, C++, C#, Go, Java, JavaScript, Julia, MATLAB, Python, R, Ruby und Rust.
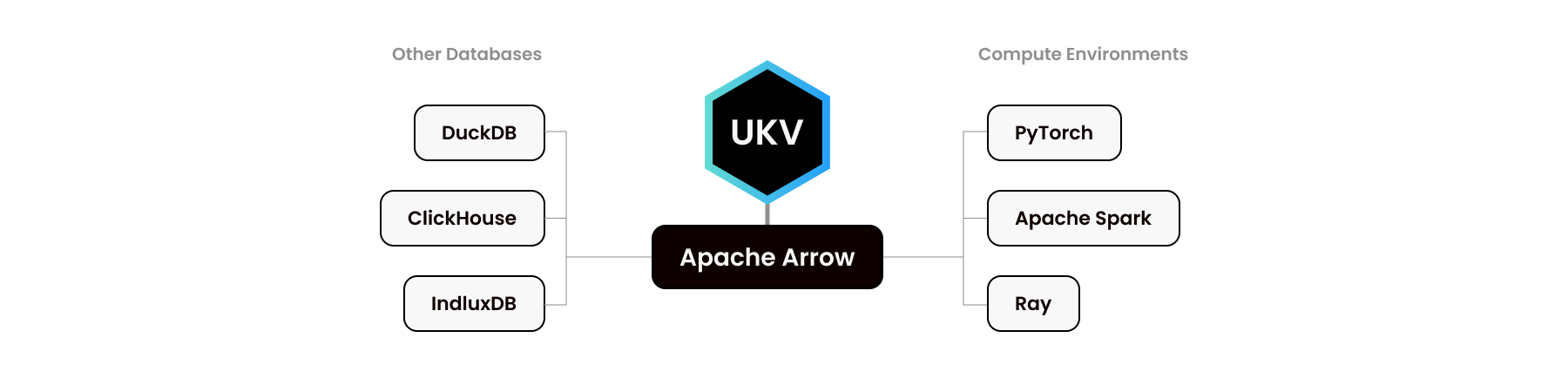
Die folgenden Motoren können nahezu austauschbar verwendet werden. Historisch gesehen war LevelDB das erste. RocksDB verbesserte dann die Funktionalität und Leistung. Mittlerweile dient es als Grundlage für die Hälfte der DBMS-Startups.
| LevelDB | RocksDB | UDisk | UCSet | |
|---|---|---|---|---|
| Geschwindigkeit | 1x | 2x | 10x | 30x |
| Hartnäckig | ✓ | ✓ | ✓ | ✗ |
| Transaktional | ✗ | ✓ | ✓ | ✓ |
| Blockgeräteunterstützung | ✗ | ✗ | ✓ | ✗ |
| Verschlüsselung | ✗ | ✗ | ✓ | ✗ |
| Uhren | ✗ | ✓ | ✓ | ✓ |
| Schnappschüsse | ✓ | ✓ | ✓ | ✗ |
| Zufallsstichprobe | ✗ | ✗ | ✓ | ✓ |
| Massenaufzählung | ✗ | ✗ | ✓ | ✓ |
| Benannte Sammlungen | ✗ | ✓ | ✓ | ✓ |
| Open-Source | ✓ | ✓ | ✗ | ✓ |
| Kompatibilität | Beliebig | Beliebig | Linux | Beliebig |
| Betreuer | Unum | Unum |
UCSet und UDisk werden beide von Unum entwickelt und verwaltet. Beide verfügen über umfassende Funktionen, aber das wichtigste Merkmal unserer Alternativen ist die Leistung. Schnell im Gedächtnis zu sein ist einfach. Die Kernlogik von UCSet befindet sich in der ucset -Bibliothek, die nur auf Vorlagen-Headern basiert.
Das Entwerfen von UDisk war ein viel anspruchsvolleres, siebenjähriges Unterfangen. Dazu gehörte die Erfindung neuer baumartiger Strukturen, die Implementierung einer teilweisen Kernel-Umgehung mit io_uring , einer vollständigen Umgehung mit SPDK , CUDA-GPU-Beschleunigung und sogar eines benutzerdefinierten internen Dateisystems. UDisk ist die erste Engine, die von Grund auf unter Berücksichtigung paralleler Architekturen und Kernel-Bypass entwickelt wurde .
Atomarität ist immer gewährleistet. Selbst bei nicht transaktionalen Schreibvorgängen sind entweder alle Aktualisierungen erfolgreich oder alle schlagen fehl.
Konsistenz wird in der strengsten möglichen Form implementiert – „strenge Serialisierbarkeit“, was bedeutet, dass:
Das Standardverhalten kann jedoch auf der Ebene bestimmter Vorgänge angepasst werden. Dazu kann ::ustore_option_transaction_dont_watch_k an ustore_transaction_init() oder eine beliebige transaktionale Lese-/Schreiboperation übergeben werden, um die Konsistenzprüfungen während des Stagings zu steuern.
| Liest | Schreibt | |
|---|---|---|
| Kopf | Strenge Seriennummer | Strenge Seriennummer |
| Transaktionen über Snapshots | Seriell | Strenge Seriennummer |
| Transaktionen ohne Snapshots | Strenge Seriennummer | Strenge Seriennummer |
| Transaktionen ohne Uhren | Strenge Seriennummer | Sequentiell |
Wenn dieses Thema für Sie neu ist, schauen Sie sich bitte den Jepsen.io-Blog zum Thema Konsistenz an.
| Liest | Schreibt | |
|---|---|---|
| Transaktionen über Snapshots | ✓ | ✓ |
| Transaktionen ohne Snapshots | ✗ | ✓ |
Haltbarkeit gilt per Definition nicht für In-Memory-Systeme. In hybriden oder persistenten Systemen bevorzugen wir es, es standardmäßig zu deaktivieren. Fast jedes DBMS, das auf KVS aufbaut, bevorzugt die Implementierung eines eigenen Haltbarkeitsmechanismus. Dies gilt umso mehr in verteilten Datenbanken, in denen drei separate Write-Ahead-Protokolle vorhanden sein können:
Wenn Sie weiterhin Haltbarkeit benötigen, leeren Sie Schreibvorgänge bei Commits mit einem optionalen Flag. Im C-Treiber würden Sie ustore_transaction_commit() mit dem Flag ::ustore_option_write_flush_k aufrufen.
Das gesamte DBMS passt in ein Docker-Image mit weniger als 100 MB. Führen Sie das folgende Skript aus, um den Container abzurufen und auszuführen und den Apache Arrow Flight-Server auf dem Port 38709 verfügbar zu machen. Client-SDKs kommunizieren standardmäßig auch über denselben Port.
docker run -d --rm --name ustore-test -p 38709:38709 unum/ustoreDie Standardkonfigurationsdatei kann wie folgt abgerufen werden:
cat /var/lib/ustore/config.jsonDer einfachste Weg, eine Verbindung herzustellen und zu testen, wäre der folgende Befehl:
python ...Vorgefertigte UStore-Images sind auf mehreren Plattformen verfügbar:
Zögern Sie nicht, UStore zu kommerzialisieren und weiterzuverbreiten.
Das Optimieren von Datenbanken ist ebenso Kunst wie Wissenschaft. Projekte wie RocksDB bieten Dutzende Regler zur Optimierung des Verhaltens. Wir ermöglichen die Weiterleitung spezieller Konfigurationsdateien an die zugrunde liegende Engine.
{
"version" : " 1.0 " ,
"directory" : " ./tmp/ "
}Wir haben auch ein einfacheres Verfahren, das für 80 % der Benutzer ausreichen würde. Dies kann erweitert werden, um mehrere Geräte oder Verzeichnisse zu nutzen oder eine spezielle Engine-Konfiguration weiterzuleiten.
{
"version" : " 1.0 " ,
"directory" : " /var/lib/ustore " ,
"data_directories" : [
{
"path" : " /dev/nvme0p0/ " ,
"max_size" : " 100GB "
},
{
"path" : " /dev/nvme1p0/ " ,
"max_size" : " 100GB "
}
],
"engine" : {
"config_file_path" : " ./engine_rocksdb.ini " ,
}
}Datenbanksammlungen können auch mit JSON-Dateien konfiguriert werden.
Ab der aktuellen Version werden 64-Bit-Ganzzahlen mit Vorzeichen verwendet. Es erlaubt eindeutige Schlüssel im Bereich von [0, 2^63) . Es kommen 128-Bit-Builds mit UUIDs, von Schlüsseln variabler Länge wird jedoch dringend abgeraten. Warum so?
Die Verwendung von Schlüsseln variabler Länge führt zu zahlreichen Einschränkungen beim Design eines Schlüsselwertspeichers. Erstens impliziert es langsame Zeichenvergleiche – ein Leistungskiller auf modernen hyperskalaren CPUs. Zweitens wird die Zusammenführung von Schlüsseln und Werten auf einer Festplatte erzwungen, um die für die Navigation erforderlichen Metadaten zu minimieren. Schließlich verstößt es gegen unsere einfache logische Sichtweise von KVS als „persistenter Speicherzuordner“ und überträgt ihm viel mehr Verantwortung.
Der empfohlene Ansatz für den Umgang mit Zeichenfolgenschlüsseln ist:
Dies führt zu einem einzigen Konvertierungspunkt von String- in Integer-Darstellungen und sorgt dafür, dass der Großteil des Systems schnell und die C-Level-Schnittstellen einfacher bleiben, als sie hätten sein können.
Derzeit können wir nur Werte von 4 GB oder weniger ansprechen. Warum? Schlüsselwertspeicher sind im Allgemeinen für Hochfrequenzvorgänge gedacht. Häufig (tausende Male pro Sekunde) ist der Zugriff auf und die Änderung von 4 GB und größeren Dateien auf moderner Hardware unmöglich. Deshalb bleiben wir bei Typen mit kleinerer Länge, was die Verwendung der Apache Arrow-Darstellung etwas einfacher macht und es dem KVS ermöglicht, Indizes besser zu komprimieren.
Unsere Entwicklungs-Roadmap ist öffentlich und wird im GitHub-Repository gehostet. Zu den bevorstehenden Aufgaben gehören:
Die vollständige Roadmap finden Sie hier in unseren Dokumenten.


