aiwhispr
version 0.941
AIWhispr ist ein No/Low-Code-Tool zur Automatisierung von Vektoreinbettungspipelines für die semantische Suche. Eine einfache Konfiguration steuert die Pipeline zum Lesen von Dateien, zum Extrahieren von Text, zum Erstellen von Vektoreinbettungen und zum Speichern dieser in einer Vektordatenbank.
AIWhispr

AIWhispr verfügt über Konnektoren für die folgenden Vektordatenbanken
1 Qdrant
2 Milvus
3 Weben
4 Schriftsinn
5 MongoDB
6 Postgres - PGVector
Bitte stellen Sie sicher, dass Sie Ihre Vektordatenbank installiert und gestartet haben.
Die Umgebungsvariable AIWHISPR_HOME_DIR sollte der vollständige Pfad zum aiwhispr-Verzeichnis sein.
Die Umgebungsvariable AIWHISPR_LOG_LEVEL kann auf DEBUG / INFO / WARNING / ERROR gesetzt werden
AIWHISPR_HOME=/<...>/aiwhispr
AIWHISPR_LOG_LEVEL=DEBUG
export AIWHISPR_HOME
export AIWHISPR_LOG_LEVEL
Denken Sie daran, die Umgebungsvariablen in Ihrem Shell-Anmeldeskript hinzuzufügen
Führen Sie den folgenden Befehl aus
$AIWHISPR_HOME/shell/install_python_packages.sh
Wenn die Installation von uwsgi fehlschlägt, stellen Sie sicher, dass gcc, python-dev und python3-dev installiert sind.
sudo apt-get install gcc
sudo apt install python-dev
sudo apt install python3-dev
pip3 install uwsgi
AIWhispr wird mit einer Streamlit-App geliefert, die Ihnen den Einstieg erleichtert.
Führen Sie die Streamlit-App aus
cd $AIWHISPR_HOME/python/streamlit
streamlit run ./Configure_Content_Site.py &
Dadurch sollte eine Streamlit-App auf dem Standardport 8501 gestartet und eine Sitzung in Ihrem Webbrowser gestartet werden
Es gibt drei Schritte, um die Pipeline für die Indizierung Ihrer Inhalte für die semantische Suche zu konfigurieren.
1. Konfigurieren Sie, um Dateien von einem Speicherort zu lesen
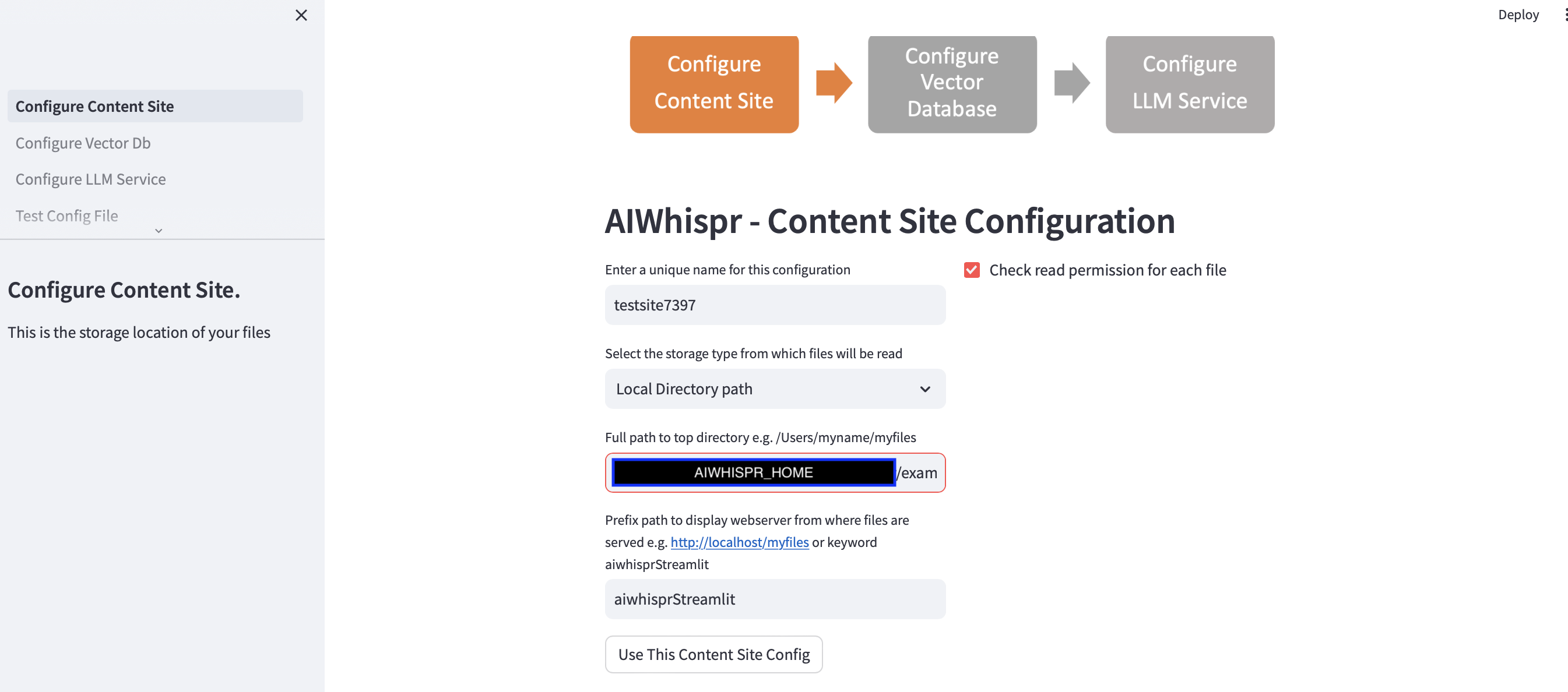
Sie können mit der Standardkonfiguration fortfahren, indem Sie auf die Schaltfläche „Diese Content-Site-Konfiguration verwenden“ klicken.
und fahren Sie mit dem nächsten Schritt fort, um die Vektordatenbankverbindung zu konfigurieren.
Das Standardbeispiel indiziert Nachrichten von BBC für die semantische Suche.
Die Streamlit-App geht davon aus, dass Sie eine neue Konfiguration starten und weist einen zufälligen Konfigurationsnamen zu. Sie können dies überschreiben, um ihm einen aussagekräftigeren Namen zu geben. Der Konfigurationsname sollte eindeutig sein; Es darf keine Leerzeichen oder Sonderzeichen enthalten.
Die Standardkonfiguration liest Inhalte aus dem lokalen Verzeichnispfad $AIWHISPR_HOME/examples/http/bbc
Diese enthält über 2.000 Nachrichtenbeiträge der BBC, die für die semantische Suche indiziert sind.
Sie können Inhalte lesen, die auf AWS S3, Azure Blob oder Google Cloud Storage gespeichert sind.
Die Präfixpfadkonfiguration wird verwendet, um die href-Weblinks für die Suchergebnisse zu erstellen. Sie können mit dem Standardschlüsselwort „aiwhisprStreamlit“ fortfahren.
Klicken Sie auf die Schaltfläche „Diese Content-Site-Konfiguration verwenden“ und fahren Sie mit dem nächsten Schritt zum Konfigurieren der Vektordatenbankverbindung fort, indem Sie in der linken Seitenleiste auf „Vektordatenbank konfigurieren“ klicken.
2. Konfigurieren Sie Vector Db
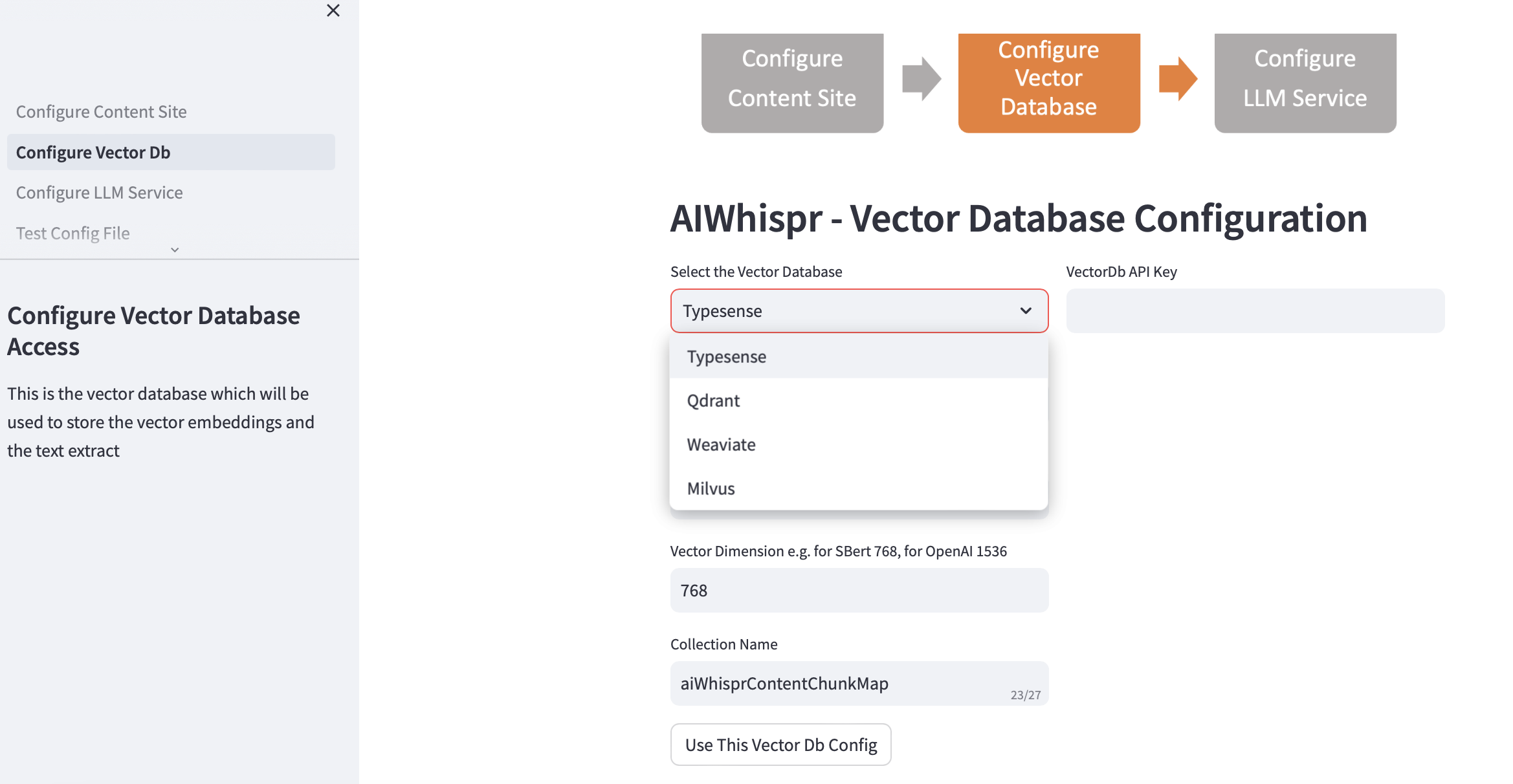
Wählen Sie Ihre Vektordatenbank aus und geben Sie die Verbindungsdetails an.
Wenn Sie die Vektordatenbank auswählen, werden die Vector Db-IP-Adresse und die Portnummern basierend auf den Standardinstallationen ausgefüllt. Sie können dies je nach Ihrem Setup ändern.
Ihre Vektordatenbank sollte für die Authentifizierung konfiguriert sein. Im Fall von Qdrant, Weaviate, Typesense ist ein API-Schlüssel erforderlich. Für Milvus sollte eine Kombination aus Benutzer-ID und Passwort konfiguriert werden.
Die Vektordimensionsgröße sollte basierend auf dem LLM angegeben werden, das Sie zum Kodieren von Text als Vektoreinbettungen verwenden möchten. Beispiel: Für Open AI „text-embedding-ada-002“ sollte dies als 1536 konfiguriert werden, was der Größe des Vektors entspricht, der vom OpenAI-Einbettungsdienst zurückgegeben wird.
Der in der Vektordatenbank erstellte Standardname der Sammlung lautet aiwhisprContentChunkMap. Sie können Ihren eigenen Sammlungsnamen angeben.
Klicken Sie auf die Schaltfläche „Diese Vector Db-Konfiguration verwenden“ und fahren Sie dann mit dem nächsten Schritt fort, indem Sie in der linken Seitenleiste auf „LLM-Dienst konfigurieren“ klicken.
3. Konfigurieren Sie den LLM-Dienst
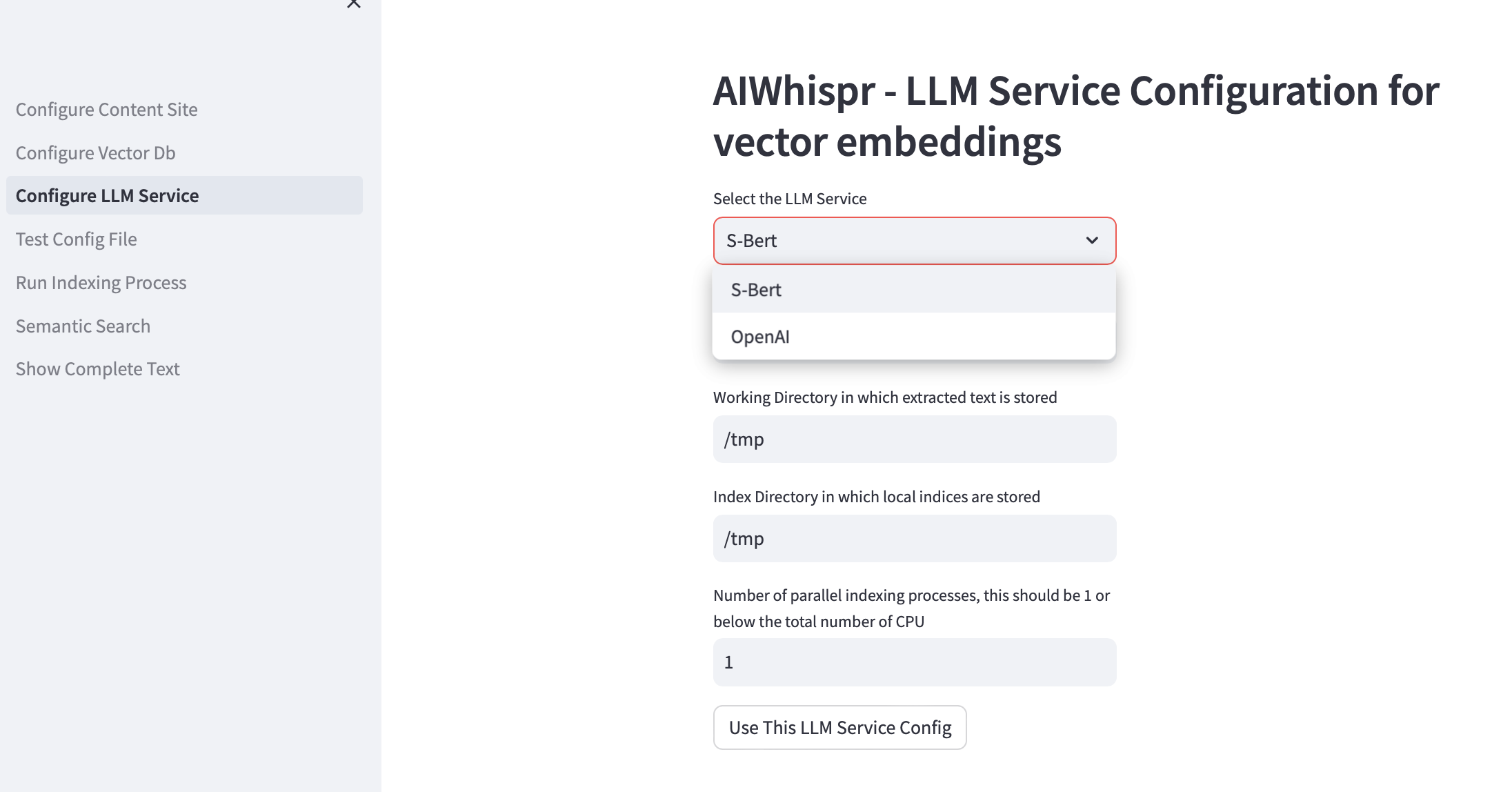
Sie können Vektoreinbettungen mit vorab trainierten Sbert-Modellen erstellen, die lokal ausgeführt werden, oder die OpenAI-API verwenden.
Für die SBert-Modellfamilie ist das verwendete Standardmodell all-mpnet-base-v2. Sie können ein anderes SBert-Modell angeben.
Für OpenAI ist das Standardeinbettungsmodell text-embedding-ada-002
Das Standardarbeitsverzeichnis ist /tmp
Das Arbeitsverzeichnis ist der Speicherort auf dem lokalen Computer, der als Arbeitsverzeichnis zum Verarbeiten der Dateien verwendet wird, die von Ihrem Speicherort gelesen/heruntergeladen werden. Der aus Ihren Dokumenten extrahierte Text wird dann in kleinere Blöcke aufgeteilt, normalerweise 700 Wörter, die dann als Vektoreinbettungen codiert werden. Das Arbeitsverzeichnis wird zum Speichern der Textblöcke verwendet.
Das standardmäßige lokale Indexierungsverzeichnis ist /tmp
Sie können einen dauerhaften lokalen Verzeichnispfad für das Arbeits- und Indexverzeichnis angeben.
Das Indexverzeichnis wird zum Speichern der Indexliste der Inhaltsdateien verwendet, die gelesen werden müssen. AIWhispr unterstützt mehrere Prozesse zur Indizierung. Jeder Prozess verwendet seine eigene Indizierungsliste, sodass Sie mehrere CPUs auf Ihrem Computer nutzen können.
Wenn Sie mehrere CPUs für die Indizierung nutzen möchten (Inhalt lesen, Vektoreinbettung erstellen, in Vektordatenbank speichern), geben Sie dies im Testfeld für die Anzahl paralleler Prozesse an. Wir empfehlen, dass dies 1 oder maximal sein sollte (Anzahl der CPUs/2). Beispiel: Auf einem 8-CPU-Computer sollte dies auf 4 eingestellt werden. AIWhispr verwendet Multiprocessing, um die Python-GIL-Einschränkungen zu umgehen.
Klicken Sie auf „Diese LLM-Dienstkonfiguration verwenden“, um die endgültige Version Ihrer Vektor-Einbettungspipeline-Konfigurationsdatei zu erstellen.
Der Inhalt der Konfigurationsdatei und ihr Speicherort auf Ihrem Computer werden angezeigt.
Sie können diese Konfiguration testen, indem Sie in der linken Seitenleiste auf „Test Config File“ klicken.
4. Testkonfiguration
Sie sollten nun eine Meldung sehen, die den Speicherort Ihrer Vektor-Einbettungspipeline-Konfigurationsdatei und eine Schaltfläche „Konfigurationsdatei testen“ anzeigt.
Durch Klicken auf die Schaltfläche wird der Prozess gestartet, der die Pipeline-Konfiguration testet
Am Ende der Protokolle sollte die Meldung „KEINE FEHLER“ angezeigt werden, die Sie darüber informiert, dass diese Pipeline-Konfiguration verwendet werden kann.
Klicken Sie in der linken Seitenleiste auf „Indizierungsprozess ausführen“, um die Pipeline zu starten.
5. Führen Sie den Indexierungsprozess aus
Sie sollten die Schaltfläche „Indizierung starten“ sehen.
Klicken Sie auf diese Schaltfläche, um die Pipeline zu starten. Die Protokolle werden alle 15 Sekunden aktualisiert.
Das Standardbeispiel indiziert mehr als 2000 BBC-Nachrichtenbeiträge, was etwa 20 Minuten dauert.
Navigieren Sie nicht von dieser Seite weg, während der Indexierungsprozess läuft, dh während der Streamlit-Status „Wird ausgeführt“ oben rechts angezeigt wird.
Sie können auch mithilfe von grep auf Ihrem Computer überprüfen, ob der Indizierungsprozess ausgeführt wird.
ps -ef | grep python3 | grep index_content_site.py
6. Semantische Suche
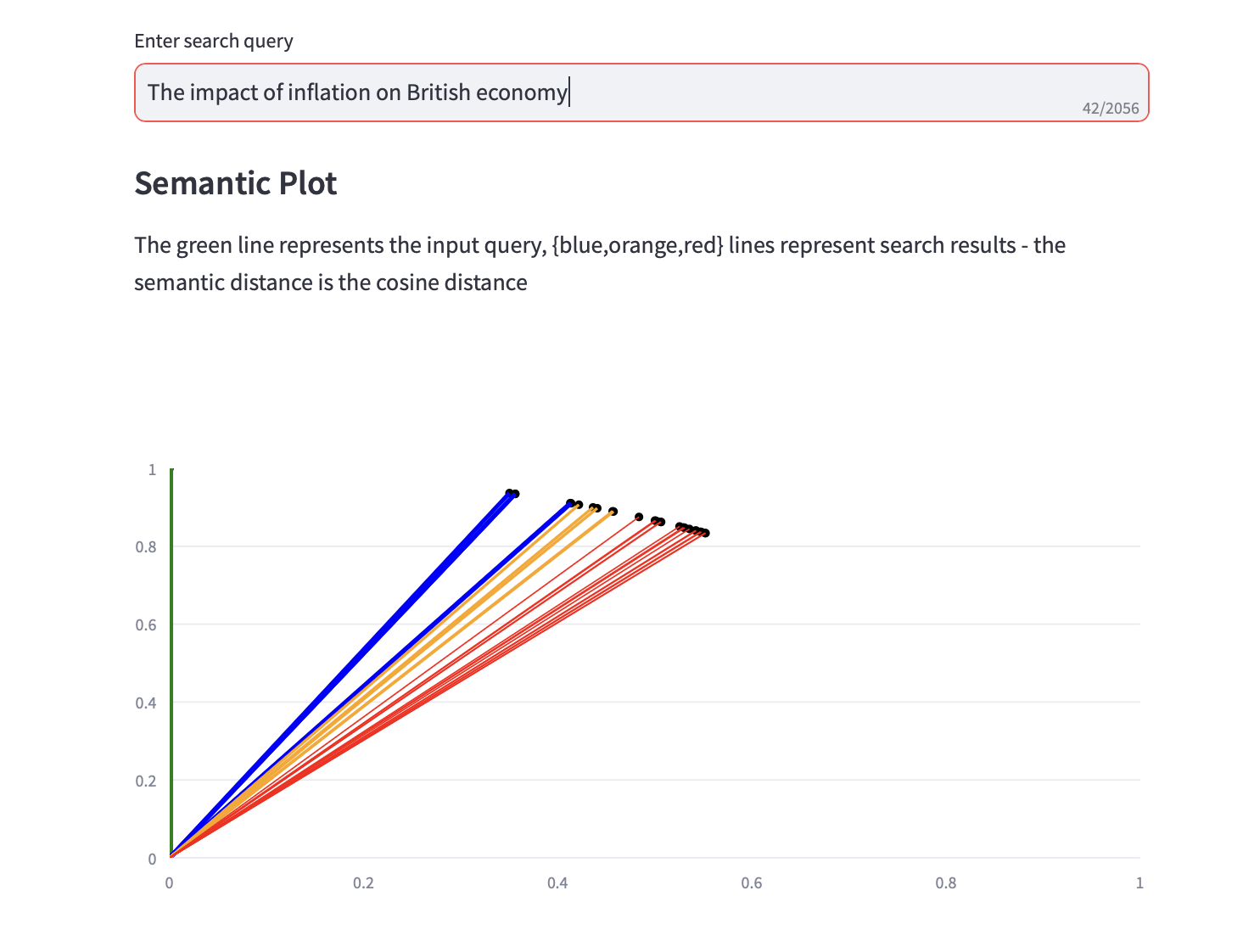
Sie können jetzt semantische Suchanfragen ausführen.
Zusammen mit den Textsuchergebnissen wird auch ein semantisches Diagramm angezeigt, das den Kosinusabstand und eine Top-3-PCA-Analyse für die Suchergebnisse anzeigt.