lnx
v0.9.0 Master

Funktionsreich | ⚡ Wahnsinnig schnell
Eine ultraschnelle, anpassbare Bereitstellung der Tantivy-Suchmaschine über REST.
lnx wurde entwickelt, um das Rad nicht neu zu erfinden, sondern basiert auf der arbeitsraubenden Laufzeitumgebung von tokio-rs , einem Hyper -Web-Framework, kombiniert mit der reinen Rechenleistung der Tantivy-Suchmaschine .
Zusammen ermöglicht dies, dass lnx eine Millisekunden-Indizierung für Zehntausende von Dokumenteneinfügungen auf einmal anbieten kann (kein Warten mehr auf die Indizierung von Dingen!), Transaktionen pro Index und die Möglichkeit, Suchvorgänge so zu verarbeiten, als wäre es nur eine weitere Suche in der Hashtabelle?
Obwohl lnx noch sehr neu ist, bietet es dank des Ökosystems, auf dem es basiert, eine breite Palette an Funktionen.
Hier können Sie sehen, wie lnx eine Suche durchführt, während Sie einen Datensatz mit 27 Millionen Dokumenten eingeben, der nach der Indizierung eine angemessene Größe von 18 GB hat und auf meinem i7-8700k mit ca. 3 GB RAM und unserem Fast-Fuzzy-System ausgeführt wird. Wollen wir einen größeren Datensatz ausprobieren? Eröffnen Sie ein Problem!
lnx bietet die Möglichkeit, das System genau an Ihren speziellen Anwendungsfall anzupassen. Sie können die asynchronen Laufzeitthreads anpassen. Der Parallelitäts-Thread-Pool, Threads pro Leser und Writer-Threads, alle pro Index.
Dies gibt Ihnen die Möglichkeit, im Detail zu steuern, wohin Ihre Computerressourcen fließen. Sie haben einen großen Datensatz, aber weniger gleichzeitige Lesevorgänge? Erhöhen Sie die Leser-Threads im Austausch für eine geringere maximale Parallelität.
Die folgenden Zahlen wurden von unserem lnx-cli für den kleinen Datensatz movies.json ermittelt. Wir haben es nicht mit höheren Werten versucht, da Meilisearch unglaublich lange braucht, um Millionen von Dokumenten zu indizieren, obwohl die neue Meilisearch-Engine dies etwas verbessert hat.
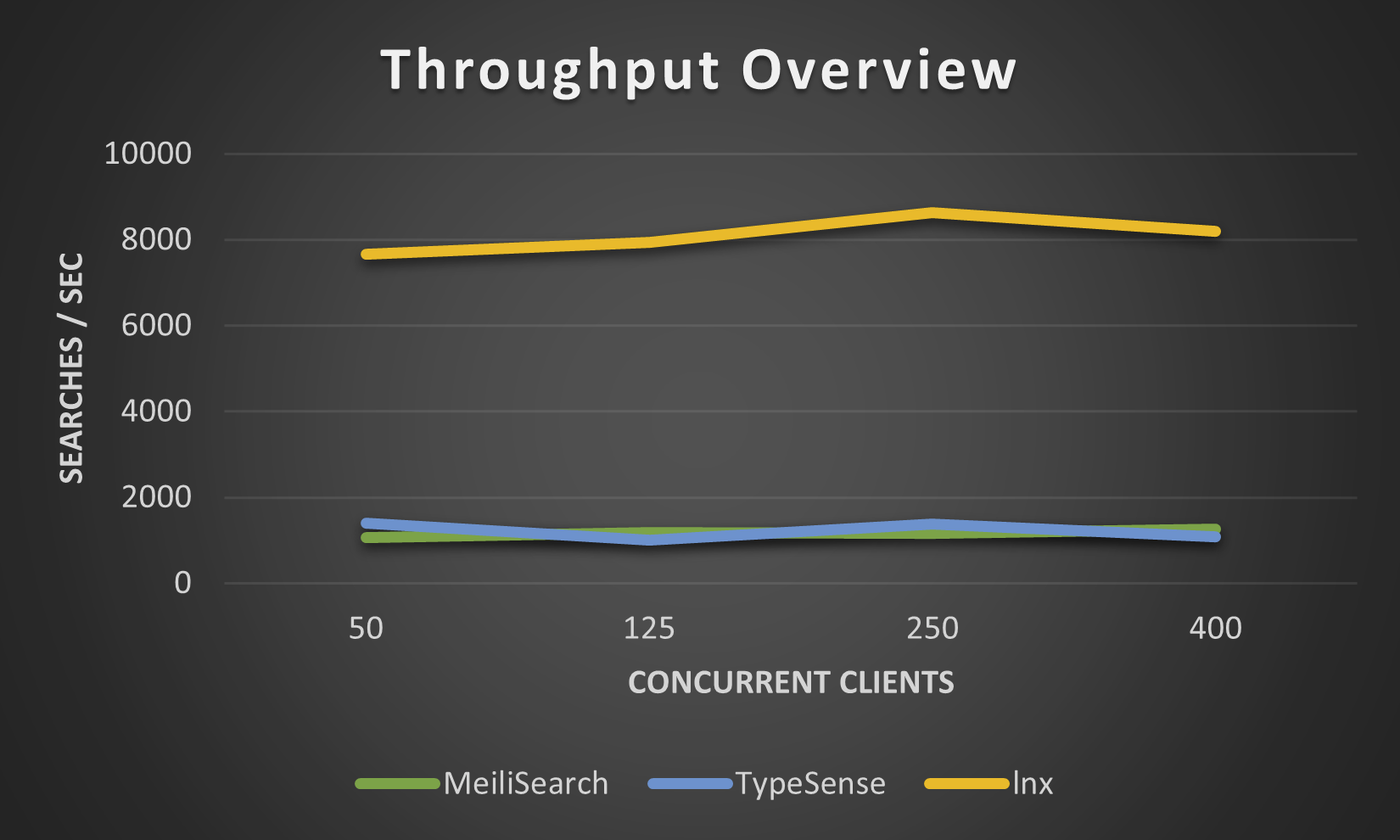
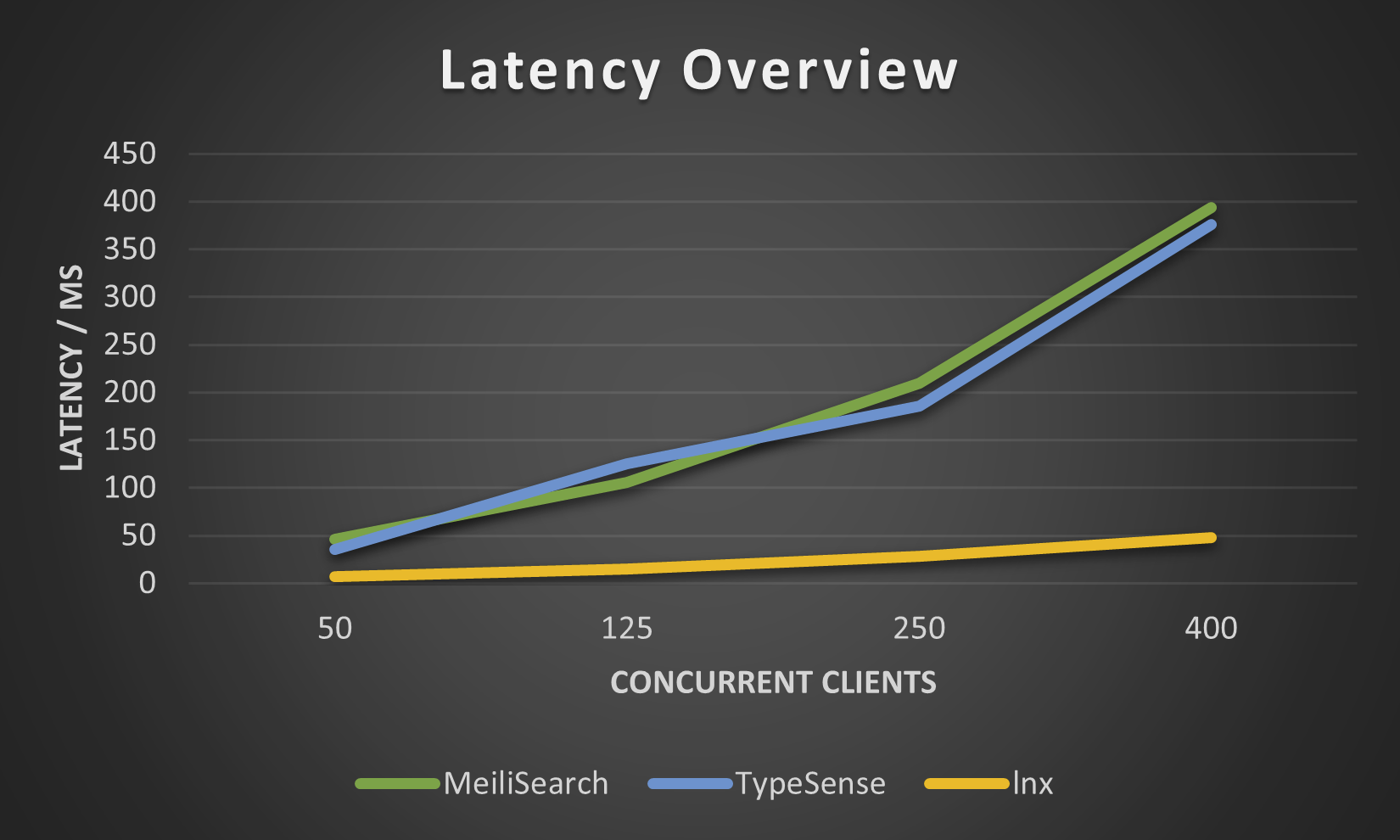
Obwohl LNX eine große Bandbreite an Funktionen bietet, kann es als so junges System noch nicht alles. Natürlich gibt es einige Einschränkungen:


