Qmedia
1.0.0
Englisch | 简体中文
Änderungsprotokoll – Probleme melden – Funktion anfordern
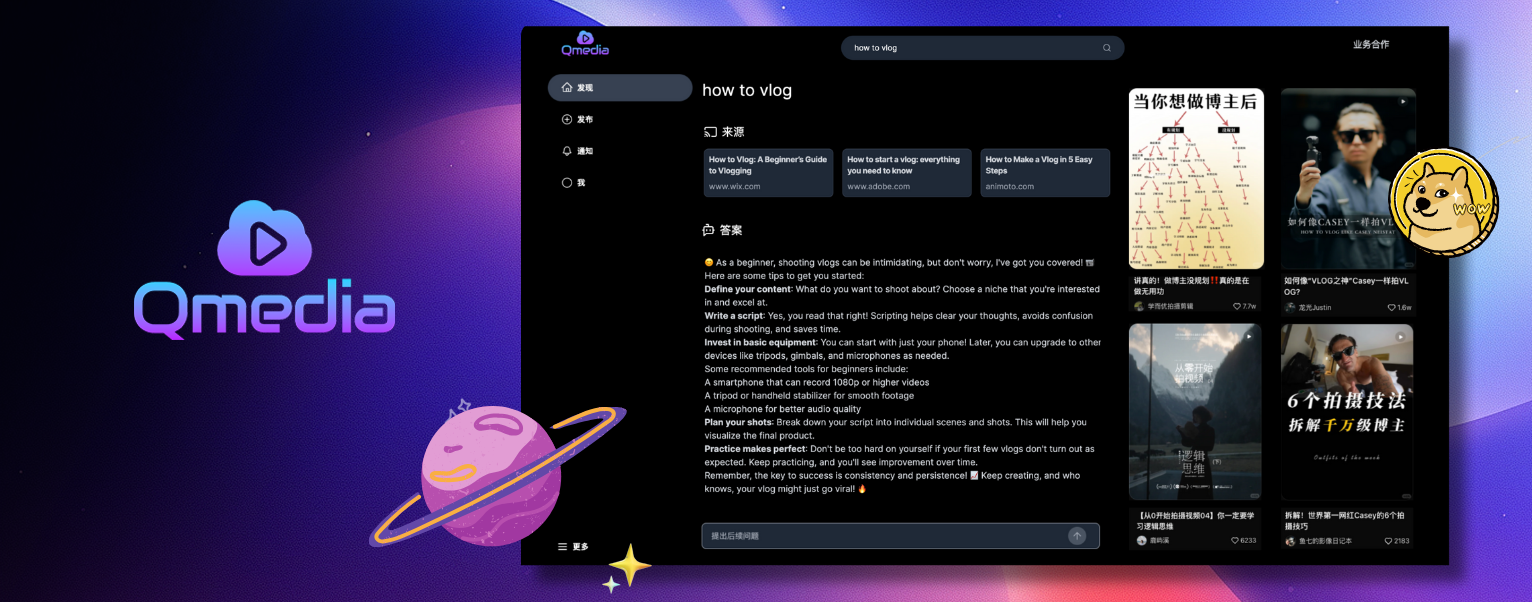
1 Inhaltskarten2 multimodale Content-Rag3 rein lokale multimodale ModelleQMedia ist eine Open-Source-Multimedia-KI-Inhaltssuchmaschine, die umfassende Methoden zur Informationsextraktion für Text/Bild und kurze Videoinhalte bietet. Es integriert unstrukturierten Text/Bild und kurze Videoinformationen, um ein multimodales Q&A-System für RAG-Inhalte aufzubauen. Ziel ist es, Ideen zur Erstellung von KI-Inhalten auf Open-Source-Art zu teilen und auszutauschen. Probleme
Teilen Sie QMedia mit Ihren Freunden.
Bringen Sie neue Ideen für die Erstellung von Inhalten hervor
| Treten Sie unserer Discord-Community bei! | |
|---|---|
 | Treten Sie unserer WeChat-Gruppe bei! |
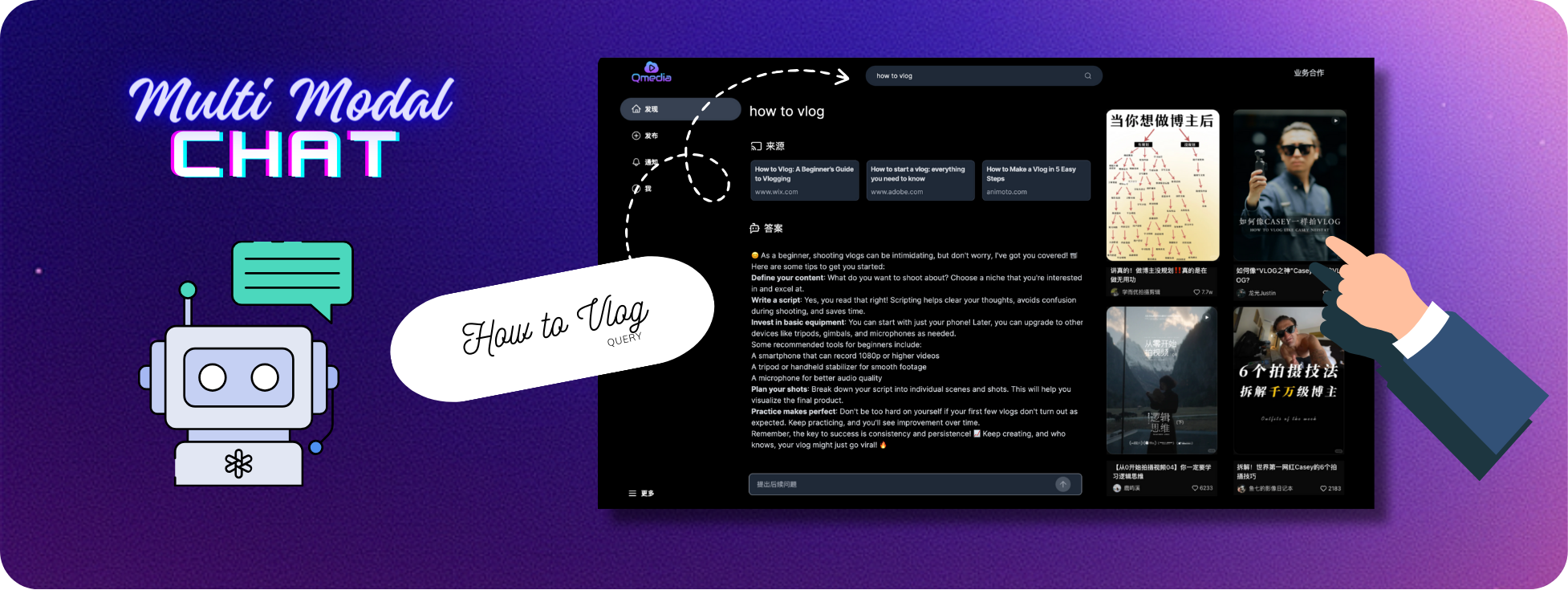
Web Service , implementiert mit dem Technologie-Stack von Typescript, Next.js, TailwindCSS und Shadcn/UIRAG Search/Q&A Service und Image/Text/Video Model Service implementiert mit dem Python-Framework und LlamaIndex-AnwendungenRAG Search/Q&A Service und Image/Text/Video Model Service können für eine flexible Bereitstellung basierend auf Benutzerressourcen separat bereitgestellt und in andere Systeme zur Extraktion von Bild-/Text- und Videoinhalten eingebettet werden. 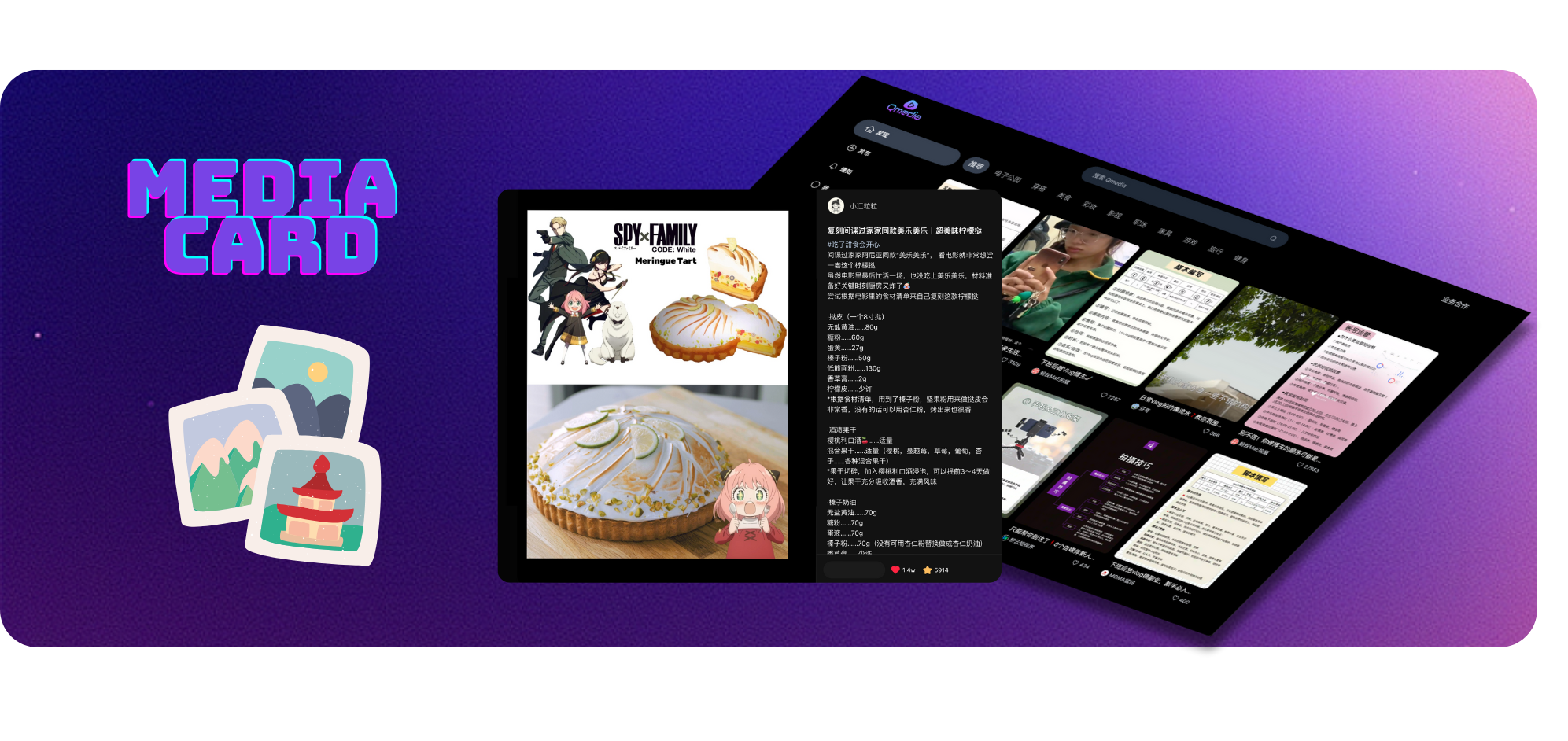
Lokale Bereitstellung verschiedener Modelltypen. Trennung von der RAG-Anwendungsschicht, wodurch es einfach ist, verschiedene Modelle zu ersetzen. Lokale Modelllebenszyklusverwaltung, konfigurierbar für manuelle oder automatische Freigabe, um die Serverlast zu reduzieren
Sprachmodelle :
Feature-Einbettungsmodelle :
Bildmodelle :
Visuelle Verständnismodelle:
Videomodelle
QMedia-Dienste: Je nach Ressourcenverfügbarkeit können sie lokal bereitgestellt werden oder die Modelldienste können in der Cloud bereitgestellt werden
Multimodaler Modelldienst mm_server :
Multimodale Modellbereitstellung und API-Aufrufe
Ollama LLM-Modelle
Bildmodelle
Videomodelle
Feature-Einbettungsmodelle
Inhaltssuche und Q&A-Service mmrag_server :
Anzeige und Abfrage von Inhaltskarten
Service zum Extrahieren, Einbetten und Speichern von Bild-/Text-/Kurzvideoinhalten
Multimodaler Daten-RAG-Abrufdienst
Inhalts-Q&A-Service
qmedia_web : Sprache: TypeScript Framework: Next.js Styling: Tailwind CSS-Komponenten: shadcn/ui mm_server + qmedia_web + mmrag_server Webseiteninhaltsanzeige, Inhalts-RAG-Suche und Fragen und Antworten, Modellservice
# Start mm_server service
cd mm_server
source activate qllm
python main.py
# Start mmrag_server service
cd mmrag_server
source activate qmedia
python main.py
# Start qmedia_web service
cd qmedia_web
pnpm devmmrag_server Pseudodaten aus assets/medias und assets/mm_pseudo_data.json und ruft mm_server auf, um die Informationen aus Text/Bild und kurzen Videos zu extrahieren und in node zu strukturieren, die dann vorliegen in der db gespeichert. Der Abruf und die Fragen und Antworten basieren auf den Daten in der db . # assets file structure
assets
├── mm_pseudo_data.json # Content card data
└── medias # Image/Video files Ersetzen Sie den Inhalt in assets und löschen Sie die historisch gespeicherte db . assets/medias enthält Bild-/Videodateien, die durch Ihre eigenen Bild-/Videodateien ersetzt werden können. assets/mm_pseudo_data.json enthält Inhaltskartendaten, die durch Ihre eigenen Inhaltskartendaten ersetzt werden können. Nach dem Ausführen des Dienstes extrahiert das Modell automatisch die Informationen und speichert sie in der db .
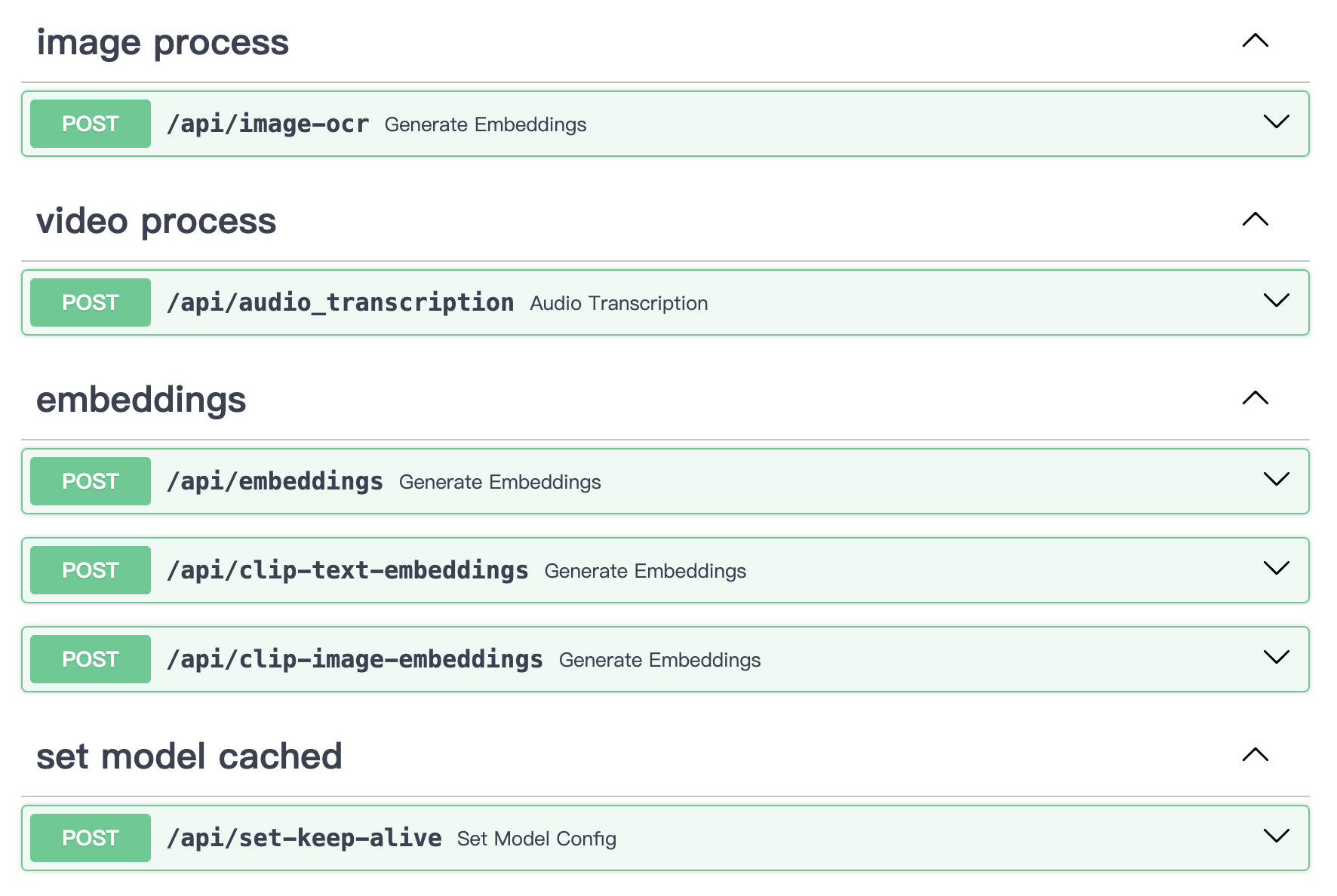
Kann den lokalen Bild-/Text-/Video-Informationsextraktionsdienst mm_server unabhängig nutzen. Es kann als eigenständiger Bildkodierungs-, Textkodierungs-, Videotranskriptionsextraktions- und Bild-OCR-Dienst verwendet werden, auf den in jedem Szenario über die API zugegriffen werden kann.
# Start mm_server service independently
cd mm_server
python main.py
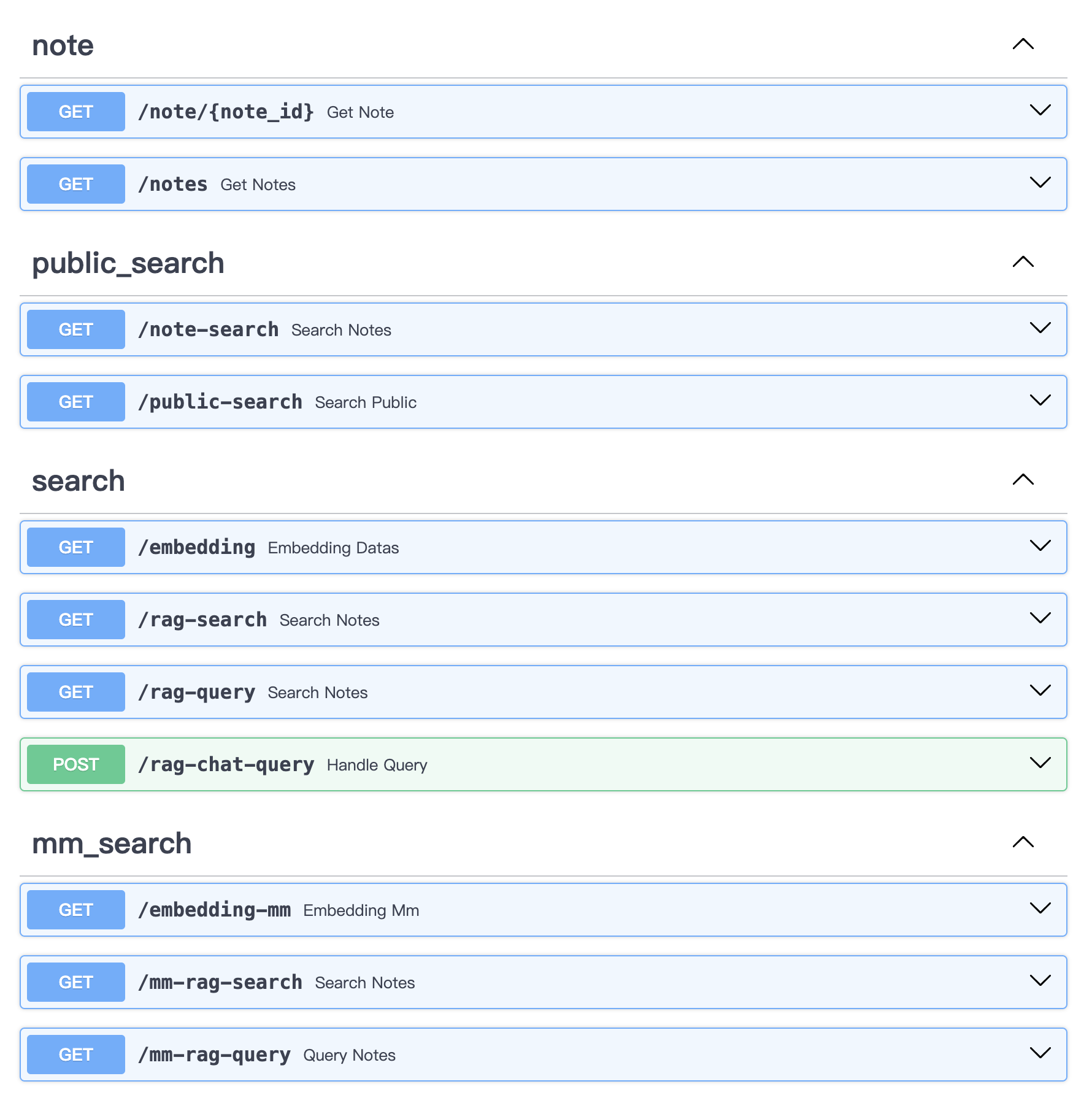
# uvicorn main:app --reload --host localhost --port 50110API-Inhalt:
Kann mm_server + qmedia_web zusammen verwenden, um Inhaltsextraktion und RAG-Abruf in einer reinen Python-Umgebung über APIs durchzuführen.
# Start mmrag_server service independently
cd mmrag_server
python main.py
# uvicorn main:app --reload --host localhost --port 50110API-Inhalt:
QMedia ist unter der MIT-Lizenz lizenziert
Vielen Dank an QAnything für starke OCR-Modelle.
Vielen Dank an llava-llama3 für starke LM-Vision-Modelle.


