elassandra
v6.2.3.38

Elassandra ist eine Apache-Cassandra-Distribution inklusive einer Elasticsearch-Suchmaschine. Elassandra ist eine Multi-Master-Multi-Cloud-Datenbank und Suchmaschine mit Unterstützung für die Replikation über mehrere Rechenzentren im Aktiv/Aktiv-Modus.
Der Elasticsearch-Code ist in Cassanda-Knoten eingebettet und bietet erweiterte Suchfunktionen für Cassandra-Tabellen. Cassandra dient als Elasticsearch-Daten- und Konfigurationsspeicher.
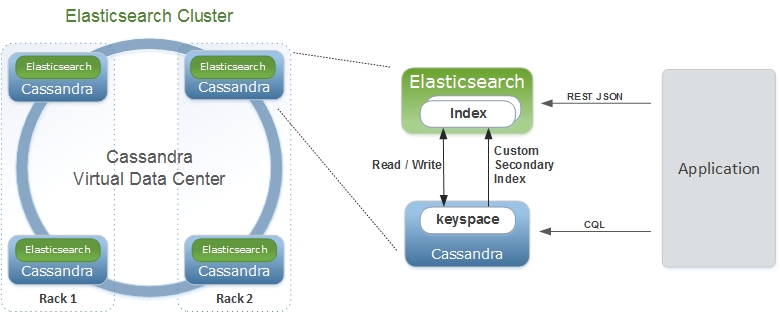
Elassandra unterstützt Cassandra-V-Knoten und skaliert horizontal durch das Hinzufügen weiterer Knoten, ohne dass ein Resharding der Indizes erforderlich ist.
Die Projektdokumentation ist unter doc.elassandra.io verfügbar.
Für Cassandra-Benutzer bietet elassandra Elasticsearch-Funktionen:
Für Elasticsearch-Benutzer bietet elassandra nützliche Funktionen:
Kurzanleitung zum Ausführen eines Elassandra-Clusters mit einem einzelnen Knoten in Docker.
Stellen Sie Elassandra bereit, indem Sie eine Google Kubernetes Engine starten:
<<<<<<< HEAD Seit Version 6.8.4.2 kann der Gossip-X1-Anwendungsstatus mithilfe einer Systemeigenschaft komprimiert werden. Durch die Aktivierung dieser Einstellungen können viele virtuelle Indizes erstellt werden. Bevor Sie diese Einstellung aktivieren, aktualisieren Sie alle 6.8.4.x-Knoten auf 6.8.4.2 (oder höher). Sobald sich alle Knoten in 6.8.4.2 befinden, können sie den Anwendungsstatus dekomprimieren, auch wenn die Einstellungen noch nicht lokal konfiguriert sind.
Elassandra verwendet das Cassandra-GOSSIP-Protokoll zur Verwaltung der Elasticsearch-Routing-Tabelle und Elassandra 6.8.4.2+ bietet Unterstützung für die Komprimierung des X1-Anwendungsstatus, um die maximale Anzahl von Elasticsearch-Indizes zu erhöhen. Aus Gründen der Abwärtskompatibilität ist die Komprimierung standardmäßig deaktiviert, aber sobald alle Ihre Knoten auf Version 6.8.4.2+ aktualisiert wurden, sollten Sie die X1-Komprimierung aktivieren, indem Sie -Des.compress_x1=true in Ihre conf/jvm.options hinzufügen und alle neu starten Knoten. Knoten mit Version 6.8.4.2+ können komprimiertes und nicht komprimiertes X1 lesen.
Vor Version 6.2.3.21 wurde der Cassandra-Replikationsfaktor für den Schlüsselraum elasic_admin (und elastic_admin_[datacenter.group]) automatisch an die Anzahl der Knoten des Datencenters angepasst. Seit Version 6.2.3.21 und da diese Auswirkungen auf die Leistung großer Cluster hat, liegt es nun an Ihrem Elassandra-Administrator, den Replikationsfaktor für diesen Schlüsselraum richtig anzupassen. Beachten Sie, dass Elasticsearch-Zuordnungsaktualisierungen auf einer PAXOS-Transaktion basieren, für deren Erfolg QUORUM-Knoten erforderlich sind. Daher sollte der Replikationsfaktor in jedem Rechenzentrum mindestens 3 betragen.
Die Metadatenversion von Elassandra 6.2.3.19 verlässt sich jetzt auf die Cassandra-Tabelle elastic_admin.metadata_log (von 6.2.3.8 bis 6.2.3.18 war es elastic_admin.metadata ), um den Aktualisierungsverlauf der Elasticsearch-Zuordnung zu behalten und nach einem möglichen PAXOS-Schreibzeitüberschreitungsproblem automatisch wiederherzustellen.
Beim Upgrade des ersten Knotens eines Clusters kopiert Elassandra automatisch die aktuelle metadata.version in die neue Tabelle elastic_admin.metadata_log . Um Inkonsistenzen bei der Elasticsearch-Zuordnung zu vermeiden, müssen Sie eine Zuordnungsaktualisierung vermeiden, während das fortlaufende Upgrade ausgeführt wird. Sobald alle Knoten aktualisiert wurden, werden die Elastic_admin.metadata nicht mehr verwendet und können entfernt werden. Anschließend können Sie den Zuordnungsaktualisierungsverlauf aus dem neuen elastischen_admin.metadata_log abrufen und wissen, welcher Knoten die Zuordnung wann und aus welchem Grund aktualisiert hat.
Elassandra 6.2.3.8+ verwaltet jetzt vollständig die Elasticsearch-Zuordnung im CQL-Schema durch die Verwendung von CQL-Schemaerweiterungen (siehe system_schema.tables , Spaltenerweiterungen ). Diese Tabellenerweiterungen und die CQL-Schemaaktualisierungen, die sich aus der Erstellung/Änderung des Elasticsearch-Index ergeben, werden in gestapelten atomaren Schemaaktualisierungen aktualisiert, um die Konsistenz bei gleichzeitigen Aktualisierungen sicherzustellen. Darüber hinaus werden diese Erweiterungen im Binärformat gespeichert und unterstützen Teilaktualisierungen, um effizienter zu sein. Dies hat zur Folge, dass die Elasticsearch-Zuordnung nicht mehr in der Tabelle „Elastic_admin.metadata“ gespeichert wird.
WARNUNG: Während des fortlaufenden Upgrades werden Elasticserach-Zuordnungsänderungen nicht zwischen Knoten weitergegeben, auf denen die neue und die alte Version ausgeführt werden. Ändern Sie Ihre Zuordnung daher während des Upgrades nicht. Sobald alle Ihre Knoten auf 6.2.3.8+ aktualisiert und validiert wurden, wenden Sie die folgenden CQL-Anweisungen an, um nutzlose Elasticsearch-Metadaten zu entfernen:
ALTER TABLE elastic_admin.metadata DROP metadata ;
ALTER TABLE elastic_admin.metadata WITH comment = ' ' ;WARNUNG: Aufgrund der von Elassandra verwendeten CQL-Tabellenerweiterungen können einige alte Versionen von cqlsh zu der folgenden Fehlermeldung führen : „Das ‚Modul‘-Objekt hat kein Attribut ‚Viewkeys‘.“ . Dies stammt vom alten Python-Cassandra-Treiber, der in Cassandra eingebettet ist, und wurde in CASSANDRA-14942 gemeldet. Mögliche Problemumgehungen:
docker run -it --rm strapdata/cqlsh:0.1 node.example.com Stellen Sie sicher, dass Java 8 installiert ist und JAVA_HOME auf den richtigen Speicherort verweist.
export CASSANDRA_HOME=<extracted_directory>bin/cassandra -e ausbin/nodetool status ausführencurl -XGET localhost:9200/_cluster/state aus Versuchen Sie, ein Dokument in einem nicht vorhandenen Index zu indizieren:
curl -XPUT ' http://localhost:9200/twitter/_doc/1?pretty ' -H ' Content-Type: application/json ' -d ' {
"user": "Poulpy",
"post_date": "2017-10-04T13:12:00Z",
"message": "Elassandra adds dynamic mapping to Cassandra"
} 'Dann schauen Sie in Cassandra nach:
bin/cqlsh -e " SELECT * from twitter. " _doc " " Hinter den Kulissen hat Elassandra einen neuen Keyspace twitter und eine neue Tabelle _doc erstellt.
admin@cqlsh > DESC KEYSPACE twitter;
CREATE KEYSPACE twitter WITH replication = { ' class ' : ' NetworkTopologyStrategy ' , ' DC1 ' : ' 1 ' } AND durable_writes = true;
CREATE TABLE twitter . " _doc " (
" _id " text PRIMARY KEY ,
message list < text > ,
post_date list < timestamp > ,
user list < text >
) WITH bloom_filter_fp_chance = 0 . 01
AND caching = { ' keys ' : ' ALL ' , ' rows_per_partition ' : ' NONE ' }
AND comment = ' '
AND compaction = { ' class ' : ' org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy ' , ' max_threshold ' : ' 32 ' , ' min_threshold ' : ' 4 ' }
AND compression = { ' chunk_length_in_kb ' : ' 64 ' , ' class ' : ' org.apache.cassandra.io.compress.LZ4Compressor ' }
AND crc_check_chance = 1 . 0
AND dclocal_read_repair_chance = 0 . 1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0 . 0
AND speculative_retry = ' 99PERCENTILE ' ;
CREATE CUSTOM INDEX elastic__doc_idx ON twitter. " _doc " () USING ' org.elassandra.index.ExtendedElasticSecondaryIndex ' ;Standardmäßig werden mehrwertige Elasticsearch-Felder der Cassandra-Liste zugeordnet. Fügen Sie nun eine Zeile mit CQL ein:
INSERT INTO twitter. " _doc " ( " _id " , user, post_date, message)
VALUES ( ' 2 ' , [ ' Jimmy ' ], [dateof(now())], [ ' New data is indexed automatically ' ]);
SELECT * FROM twitter. " _doc " ;
_id | message | post_date | user
-- ---+--------------------------------------------------+-------------------------------------+------------
2 | [ ' New data is indexed automatically ' ] | [ ' 2019-07-04 06:00:21.893000+0000 ' ] | [ ' Jimmy ' ]
1 | [ ' Elassandra adds dynamic mapping to Cassandra ' ] | [ ' 2017-10-04 13:12:00.000000+0000 ' ] | [ ' Poulpy ' ]
( 2 rows)Suchen Sie dann mit der Elasticsearch-API danach:
curl " localhost:9200/twitter/_search?q=user:Jimmy&pretty "Und hier ist eine Beispielantwort:
{
"took" : 3 ,
"timed_out" : false ,
"_shards" : {
"total" : 1 ,
"successful" : 1 ,
"skipped" : 0 ,
"failed" : 0
},
"hits" : {
"total" : 1 ,
"max_score" : 0.6931472 ,
"hits" : [
{
"_index" : " twitter " ,
"_type" : " _doc " ,
"_id" : " 2 " ,
"_score" : 0.6931472 ,
"_source" : {
"post_date" : " 2019-07-04T06:00:21.893Z " ,
"message" : " New data is indexed automatically " ,
"user" : " Jimmy "
}
}
]
}
} This software is licensed under the Apache License, version 2 ("ALv2"), quoted below.
Copyright 2015-2018, Strapdata ([email protected]).
Licensed under the Apache License, Version 2.0 (the "License"); you may not
use this file except in compliance with the License. You may obtain a copy of
the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
License for the specific language governing permissions and limitations under
the License.


