wagtail_textract
1.0.0
Dieses Paket wird nicht gepflegt und wir haben nicht vor, es zu pflegen.
Wir empfehlen Ihnen, es als Beispiel zu verwenden, den Code vielleicht in Ihr eigenes Projekt zu kopieren, aber das Paket nicht zu installieren.
Dieses Paket dient zum Ersetzen der Document-Klasse von Wagtail durch eine Klasse, die die Suche im Inhalt von Dokumentdateien mithilfe von Texttract ermöglicht.
Textract kann Text (unter anderem) aus PDF-, Excel- und Word-Dateien extrahieren.
Das Paket wurde durch das Problem „Suche: Text aus Dokumenten extrahieren“ in Wagtail inspiriert.
Dokumente funktionieren wie zuvor, mit der Ausnahme, dass die Dokumentensuche in der Admin-Oberfläche von Wagtail auch Suchbegriffe im Inhalt der Dateien findet.
Einige Screenshots zur Veranschaulichung.
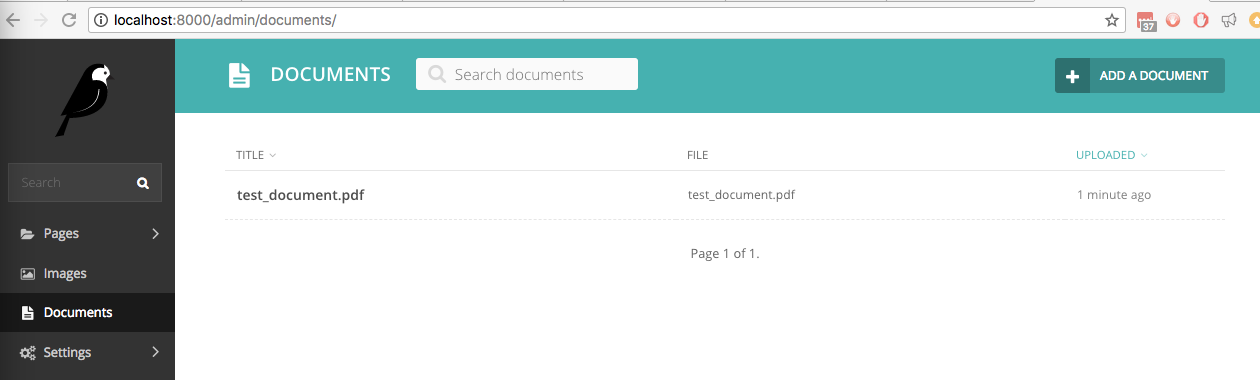
Auf unserer neuen Wagtail-Site mit installiertem wagtail_textract haben wir eine Datei namens test_document.pdf mit handgeschriebenem Text hochgeladen. Es wird in der Admin-Oberfläche unter Dokumente aufgeführt:
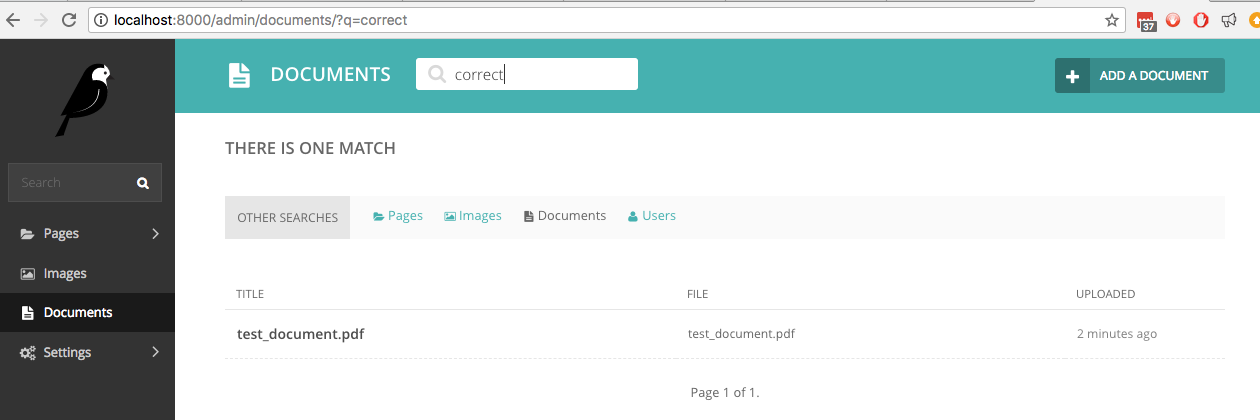
Wenn wir nun in Dokumenten nach dem Wort correct suchen, das zu den handgeschriebenen Wörtern gehört, wird die Live-Suche es finden:
Es wird davon ausgegangen, dass diese Suche nicht nur in der Admin-Oberfläche von Wagtail verfügbar sein sollte, sondern auch in einer öffentlich zugänglichen Suchansicht, für die wir ein Codebeispiel bereitstellen.
Wir verwenden dieses Paket seit August 2018 in der Produktion auf https://nuffic.nl.
wagtail_textract zu Ihren Anforderungen hinzu und/oder pip install wagtail_textractINSTALLED_APPS zu Ihrem Django hinzu.WAGTAILDOCS_DOCUMENT_MODEL = "wagtail_textract.document" in Ihre Django-Einstellungen ein.Hinweis: Während der Installation von wagtail_texttract (Wagtail 2.0.1 installiert) wird eine Inkompatibilitätswarnung angezeigt:
requests 2.18.4 has requirement chardet<3.1.0,>=3.0.2, but you'll have chardet 2.3.0 which is incompatible.
textract 1.6.1 has requirement beautifulsoup4==4.5.3, but you'll have beautifulsoup4 4.6.0 which is incompatible.
Wir haben nicht gesehen, dass dies zu Problemen führt, aber es ist etwas, das man im Hinterkopf behalten sollte.
Damit textract Tesseract verwendet, was passiert, wenn reguläres textract keinen Text findet, müssen Sie die Datendateien hinzufügen, auf denen Tesseract seinen Wortabgleich basieren kann.
Erstellen Sie in Ihrem Projektverzeichnis ein tessdata Verzeichnis und laden Sie die gewünschten Sprachen herunter.
Die Transkription erfolgt nach dem Speichern des Dokuments automatisch in einem asyncio -Executor, um ein Blockieren der Antwort während der Verarbeitung zu verhindern.
Um alle vorhandenen Dokumente zu transkribieren, führen Sie den Verwaltungsbefehl aus:
./manage.py transcribe_documents
Das kann natürlich lange dauern.
Hier ist ein Codebeispiel für eine Suchansicht (außerhalb der Admin-Oberfläche von Wagtail), die sowohl Seiten- als auch Dokumentergebnisse anzeigt.
from itertools import chain
from wagtail . core . models import Page
from wagtail . documents . models import get_document_model
def search ( request ):
# Search
search_query = request . GET . get ( 'query' , None )
if search_query :
page_results = Page . objects . live (). search ( search_query )
document_results = Document . objects . search ( search_query )
search_results = list ( chain ( page_results , document_results ))
# Log the query so Wagtail can suggest promoted results
Query . get ( search_query ). add_hit ()
else :
search_results = Page . objects . none ()
# Render template
return render ( request , 'website/search_results.html' , {
'search_query' : search_query ,
'search_results' : search_results ,
}) Ihre Vorlage sollte eine andere Handhabung von Dokumenten als von Seiten ermöglichen, da Sie für ein Dokument kein pageurl result ausführen können:
{% if result . file %}
< a href = " {{ result.url }} " >{{ result }}</ a >
{% else %}
< a href = " {% pageurl result %} " >{{ result }}</ a >
{% endif %} Um wagtail_texttract zu verwenden, sollte Ihr CustomizedDocument -Modell dasselbe tun wie das Dokument von wagtail_texttract:
TranscriptionMixinsearch_fields ändern from wagtail_textract . models import TranscriptionMixin
class CustomizedDocument ( TranscriptionMixin , ...):
"""Extra fields and methods for Document model."""
search_fields = ... + [
index . SearchField (
'transcription' ,
partial_match = False ,
),
] Beachten Sie, dass die erste Klasse zur Unterklasse TranscriptionMixin sein sollte, sodass save() Vorrang vor den anderen übergeordneten Klassen hat.
Um Tests auszuführen, checken Sie dieses Repository aus und:
make test
Ein Abdeckungsbericht wird in ./coverage_html_report/ generiert.


