loss_function_search
1.0.0
Xiaobo Wang*, Shuo Wang*, Cheng Chi, Shifeng Zhang, Tao Mei
Dies ist die offizielle Implementierung unserer Verlustfunktionssuche zur Gesichtserkennung. Es wird von ICML 2020 akzeptiert.
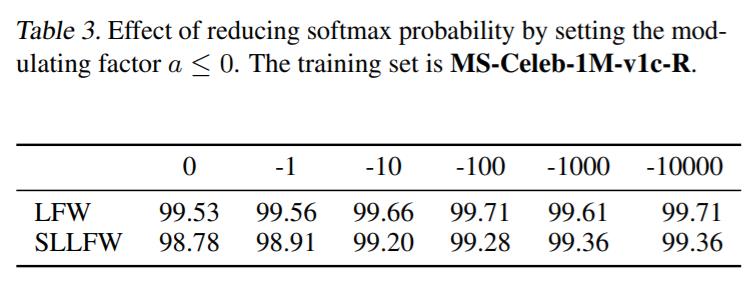
Bei der Gesichtserkennung spielt das Entwerfen randbasierter (z. B. eckiger, additiver, additiver Winkelränder) Softmax-Verlustfunktionen eine wichtige Rolle beim Erlernen diskriminierender Merkmale. Diese handgefertigten heuristischen Methoden sind jedoch nicht optimal, da sie viel Aufwand erfordern, um den großen Designraum zu erkunden. Wir analysieren zunächst, dass der Schlüssel zur Verbesserung der Merkmalsunterscheidung tatsächlich darin liegt, die Softmax-Wahrscheinlichkeit zu verringern . Anschließend entwerfen wir eine einheitliche Formulierung für die aktuellen margenbasierten Softmax-Verluste. Dementsprechend definieren wir einen neuartigen Suchraum und entwickeln eine belohnungsgesteuerte Suchmethode, um automatisch den besten Kandidaten zu finden. Experimentelle Ergebnisse verschiedener Gesichtserkennungs-Benchmarks haben die Wirksamkeit unserer Methode gegenüber modernsten Alternativen gezeigt.
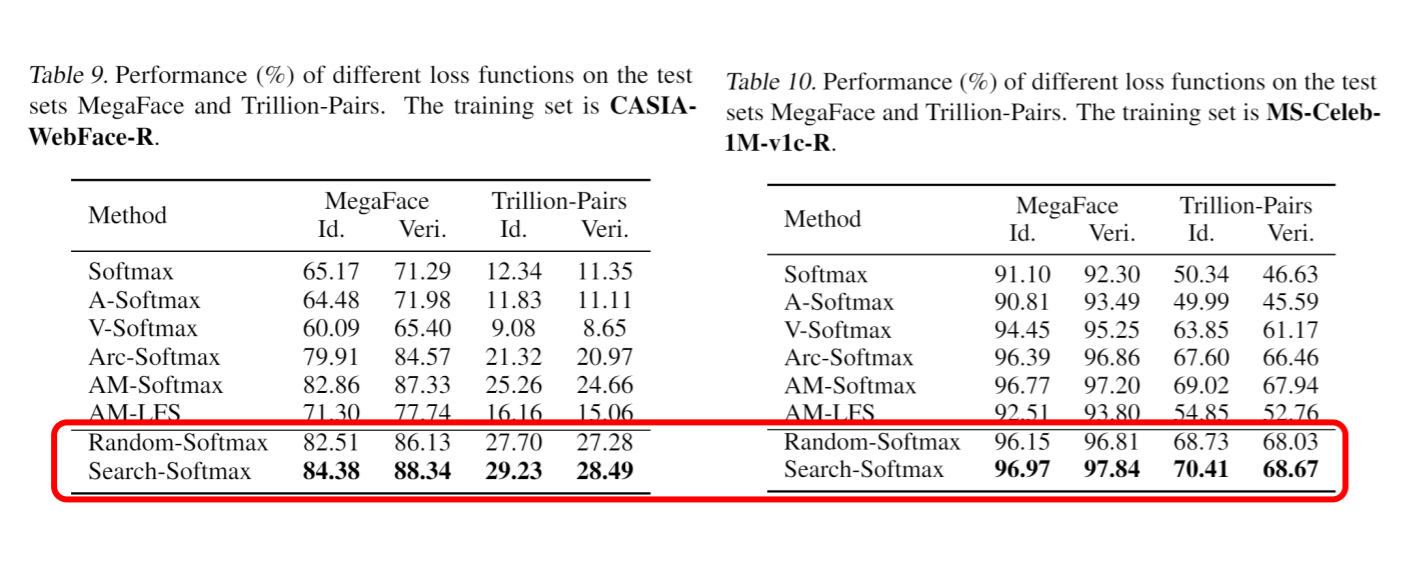

Um die Wirksamkeit unseres Suchraums zu überprüfen, können Sie einfach „Random-Softmax“ wählen. In train.sh können Sie do_search=1 setzen. Wenn wir zufälliges Softmax verwenden, um unser Netzwerk zu trainieren, erhalten wir das folgende Ergebnis.
Pytorch 1.1 oder höher ist erforderlich.
In der aktuellen Implementierung verwenden wir lmdb zum Packen unserer Trainingsbilder. Das Format unserer lmdb stammt hauptsächlich von Caffe. Und Sie könnten Ihre eigene caffe.proto-Datei wie folgt schreiben:
syntax = "proto2";
message Datum {
//the acutal image data, in bytes.
optional bytes data=1;
}
Neben der LMDB sollte eine Textdatei vorhanden sein, die die LMDB beschreibt. Jede Zeile der Textdatei enthält 2 Felder, die durch ein Leerzeichen getrennt sind. Die Zeile in der Textdatei lautet wie folgt:
lmdb_key label
./train.shSie können entweder ./train.sh verwenden. Beachten Sie, dass Sie vor der Ausführung von train.sh Ihre eigene train_source_lmdb und train_source_file bereitstellen sollten. Für mehr Nutzung bitte
python main . py - h

