yagooglesearch
v1.10.0
yagooglesearch ist eine Python-Bibliothek zum Ausführen intelligenter, realistisch aussehender und anpassbarer Google-Suchen. Es simuliert das Suchverhalten eines echten Menschen bei Google, um eine Ratenbegrenzung durch Google (die gefürchtete HTTP 429-Antwort) zu verhindern. Wenn HTTP 429 von Google blockiert wird, ist es logisch, einen Schritt zurückzutreten und es weiter zu versuchen. Die Bibliothek verwendet nicht die Google API und basiert stark auf der Googlesearch-Bibliothek. Zu den Funktionen gehören:
requests für HTTP-Anfragen und Cookie-VerwaltungDieser Code wird so bereitgestellt, wie er ist, und Sie tragen die volle Verantwortung für die Art und Weise, wie er verwendet wird. Das Scrapen von Google-Suchergebnissen verstößt möglicherweise gegen deren Nutzungsbedingungen. Eine weitere Python-Google-Suchbibliothek enthielt einige interessante Informationen/Diskussionen:
Die bevorzugte Methode von Google ist die Verwendung ihrer API.
pip install yagooglesearchgit clone https://github.com/opsdisk/yagooglesearch
cd yagooglesearch
virtualenv -p python3 .venv # If using a virtual environment.
source .venv/bin/activate # If using a virtual environment.
pip install . # Reads from pyproject.toml import yagooglesearch
query = "site:github.com"
client = yagooglesearch . SearchClient (
query ,
tbs = "li:1" ,
max_search_result_urls_to_return = 100 ,
http_429_cool_off_time_in_minutes = 45 ,
http_429_cool_off_factor = 1.5 ,
# proxy="socks5h://127.0.0.1:9050",
verbosity = 5 ,
verbose_output = True , # False (only URLs) or True (rank, title, description, and URL)
)
client . assign_random_user_agent ()
urls = client . search ()
len ( urls )
for url in urls :
print ( url ) Auch wenn bei der Google-Suche über die GUI eine Meldung wie „Etwa 13.000.000 Ergebnisse“ angezeigt wird, bedeutet das nicht, dass yagooglesearch auch nur annähernd etwas in der Nähe findet. Tests zeigen, dass höchstens etwa 400 Ergebnisse zurückgegeben werden. Wenn Sie 400 < max_search_result_urls_to_return festlegen, wird eine Warnmeldung in den Protokollen gedruckt. Siehe Nr. 28 für die Diskussion.
Langsam und langsam ist die Strategie bei der Durchführung von Google-Suchen mit yagooglesearch . Wenn Sie HTTP 429-Antworten erhalten, hat Google Sie zu Recht als Bot erkannt und blockiert Ihre IP für einen festgelegten Zeitraum. yagooglesearch ist nicht in der Lage, CAPTCHA zu umgehen, Sie können dies jedoch manuell tun, indem Sie eine Google-Suche über einen Browser durchführen und nachweisen, dass Sie ein Mensch sind.
Die Kriterien und Schwellenwerte für die Blockierung sind unbekannt, aber im Allgemeinen sollte es ausreichen, den Benutzeragenten zufällig auszuwählen, genügend Zeit zwischen seitenbezogenen Suchergebnissen (7–17 Sekunden) und zwischen verschiedenen Google-Suchen (30–60 Sekunden) zu warten. Ihr Kilometerstand wird jedoch definitiv variieren. Wenn Sie diese Bibliothek mit Tor verwenden, werden Sie wahrscheinlich schnell blockiert.
Wenn yagooglesearch eine HTTP 429-Antwort von Google erkennt, wird es für http_429_cool_off_time_in_minutes Minuten in den Ruhezustand versetzt und es dann erneut versuchen. Jedes Mal, wenn ein HTTP 429 erkannt wird, erhöht sich die Wartezeit um den Faktor http_429_cool_off_factor .
Das Ziel besteht darin, dass sich yagooglesearch um die Erkennung und Wiederherstellung von HTTP 429 kümmert und nicht das Skript, das es verwendet, belastet.
Wenn Sie nicht möchten, dass yagooglesearch HTTP 429s verarbeitet, sondern lieber selbst damit umgehen möchten, übergeben Sie beim Instanziieren des yagooglesearch-Objekts yagooglesearch_manages_http_429s=False . Wenn ein HTTP 429 erkannt wird, wird die Zeichenfolge „HTTP_429_DETECTED“ zu einem Listenobjekt hinzugefügt, das zurückgegeben wird, und es liegt an Ihnen, wie der nächste Schritt aussehen soll. Das Listenobjekt enthält alle URLs, die vor der Erkennung von HTTP 429 gefunden wurden.
import yagooglesearch
query = "site:twitter.com"
client = yagooglesearch . SearchClient (
query ,
tbs = "li:1" ,
verbosity = 4 ,
num = 10 ,
max_search_result_urls_to_return = 1000 ,
minimum_delay_between_paged_results_in_seconds = 1 ,
yagooglesearch_manages_http_429s = False , # Add to manage HTTP 429s.
)
client . assign_random_user_agent ()
urls = client . search ()
if "HTTP_429_DETECTED" in urls :
print ( "HTTP 429 detected...it's up to you to modify your search." )
# Remove HTTP_429_DETECTED from list.
urls . remove ( "HTTP_429_DETECTED" )
print ( "URLs found before HTTP 429 detected..." )
for url in urls :
print ( url )
yagooglesearch unterstützt die Verwendung eines Proxys. Der bereitgestellte Proxy wird für den gesamten Lebenszyklus der Suche verwendet, um sie menschlicher zu gestalten, anstatt für verschiedene Teile der Suche durch verschiedene Proxys zu wechseln. Der allgemeine Suchlebenszyklus ist:
google.com Um einen Proxy zu verwenden, geben Sie beim Initialisieren eines yagooglesearch.SearchClient -Objekts eine Proxy-Zeichenfolge an:
client = yagooglesearch . SearchClient (
"site:github.com" ,
proxy = "socks5h://127.0.0.1:9050" ,
) Unterstützte Proxy-Schemata basieren auf denen, die in der Python- requests -Bibliothek (https://docs.python-requests.org/en/master/user/advanced/#proxies) unterstützt werden:
httphttpssocks5 – „bewirkt, dass die DNS-Auflösung auf dem Client und nicht auf dem Proxyserver erfolgt.“ Sie möchten dies wahrscheinlich nicht , da alle DNS-Suchen von dort stammen würden, wo yagooglesearch ausgeführt wird, und nicht vom Proxy.socks5h – „Wenn Sie die Domänen auf dem Proxyserver auflösen möchten, verwenden Sie sock5h als Schema.“ Dies ist die beste Option, wenn Sie SOCKS verwenden, da die DNS-Suche und die Google-Suche von der Proxy-IP-Adresse ausgehen. Wenn Sie ein selbstsigniertes Zertifikat für einen HTTPS-Proxy verwenden, müssen Sie wahrscheinlich die SSL/TLS-Überprüfung deaktivieren, wenn:
yagooglesearch.SearchClient Objekts: import yagooglesearch
query = "site:github.com"
client = yagooglesearch . SearchClient (
query ,
proxy = "http://127.0.0.1:8080" ,
verify_ssl = False ,
verbosity = 5 ,
) query = "site:github.com"
client = yagooglesearch . SearchClient (
query ,
proxy = "http://127.0.0.1:8080" ,
verbosity = 5 ,
)
client . verify_ssl = False Wenn Sie mehrere Proxys verwenden möchten, liegt diese Belastung beim Skript, das die yagooglesearch -Bibliothek verwendet, um ein neues yagooglesearch.SearchClient Objekt mit dem anderen Proxy zu instanziieren. Unten sehen Sie ein Beispiel für das Durchlaufen einer Liste von Proxys:
import yagooglesearch
proxies = [
"socks5h://127.0.0.1:9050" ,
"socks5h://127.0.0.1:9051" ,
"http://127.0.0.1:9052" , # HTTPS proxy with a self-signed SSL/TLS certificate.
]
search_queries = [
"python" ,
"site:github.com pagodo" ,
"peanut butter toast" ,
"are dragons real?" ,
"ssh tunneling" ,
]
proxy_rotation_index = 0
for search_query in search_queries :
# Rotate through the list of proxies using modulus to ensure the index is in the proxies list.
proxy_index = proxy_rotation_index % len ( proxies )
client = yagooglesearch . SearchClient (
search_query ,
proxy = proxies [ proxy_index ],
)
# Only disable SSL/TLS verification for the HTTPS proxy using a self-signed certificate.
if proxies [ proxy_index ]. startswith ( "http://" ):
client . verify_ssl = False
urls_list = client . search ()
print ( urls_list )
proxy_rotation_index += 1 Wenn Sie über einen Cookie-Wert GOOGLE_ABUSE_EXEMPTION verfügen, kann dieser beim Instanziieren des SearchClient Objekts an google_exemption übergeben werden.
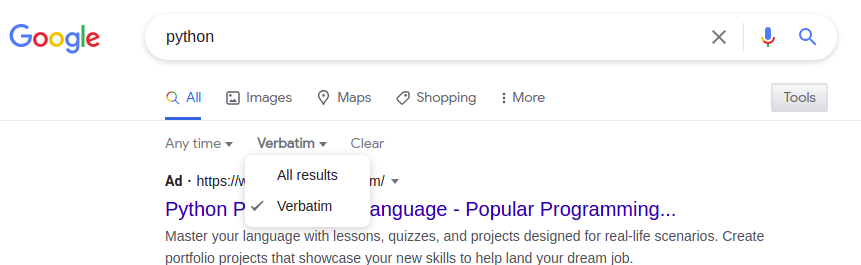
Der Parameter &tbs= wird verwendet, um entweder wörtliche oder zeitbasierte Filter anzugeben.
&tbs=li:1
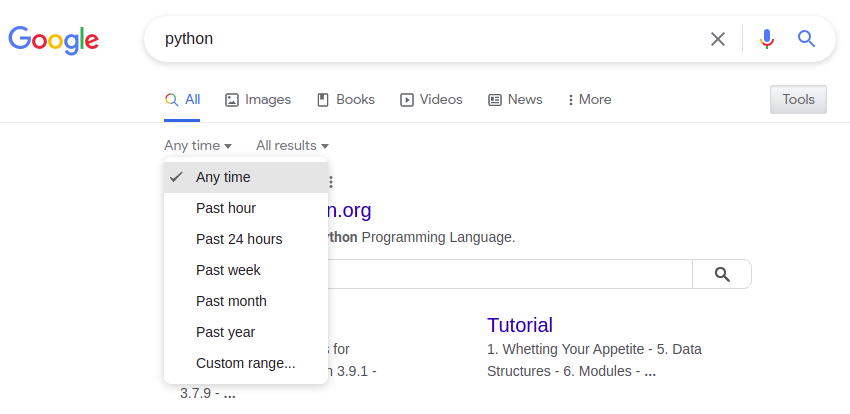
| Zeitfilter | &tbs= URL-Parameter | Notizen |
|---|---|---|
| Letzte Stunde | qdr:h | |
| Vergangener Tag | qdr:d | Letzte 24 Stunden |
| Letzte Woche | qdr:w | |
| Letzten Monat | qdr:m | |
| Letztes Jahr | qdr:y | |
| Brauch | cdr:1,cd_min:01.01.2021,cd_max:01.06.2021 | Siehe Funktion yagooglesearch.get_tbs() |
Derzeit entfernt die Funktion .filter_search_result_urls() alle URLs, die das Wort „google“ enthalten. Dadurch soll verhindert werden, dass die zurückgegebenen Such-URLs mit Google-URLs verunreinigt werden. Beachten Sie dies, wenn Sie explizit nach Ergebnissen suchen möchten, deren URL möglicherweise „google“ enthält, z. B. site:google.com computer
Verteilt unter der BSD-3-Klausel-Lizenz. Weitere Informationen finden Sie unter LIZENZ.
@opsdisk
Projektlink: https://github.com/opsdisk/yagooglesearch


