SeekStorm
v0.11.0

SeekStorm ist eine Open-Source-Bibliothek für die Volltextsuche im Submillisekundenbereich und ein mandantenfähiger Server, der in Rust implementiert ist.
Die Entwicklung begann im Jahr 2015, in Produktion seit 2020, Rust-Port im Jahr 2023, Open Source im Jahr 2024, in Arbeit.
SeekStorm ist Open Source und unterliegt der Apache-Lizenz 2.0
Blog-Beiträge: SeekStorm ist jetzt Open Source und SeekStorm erhält Facettensuche, geografische Nähesuche und Ergebnissortierung
Abfragetypen
Ergebnistypen
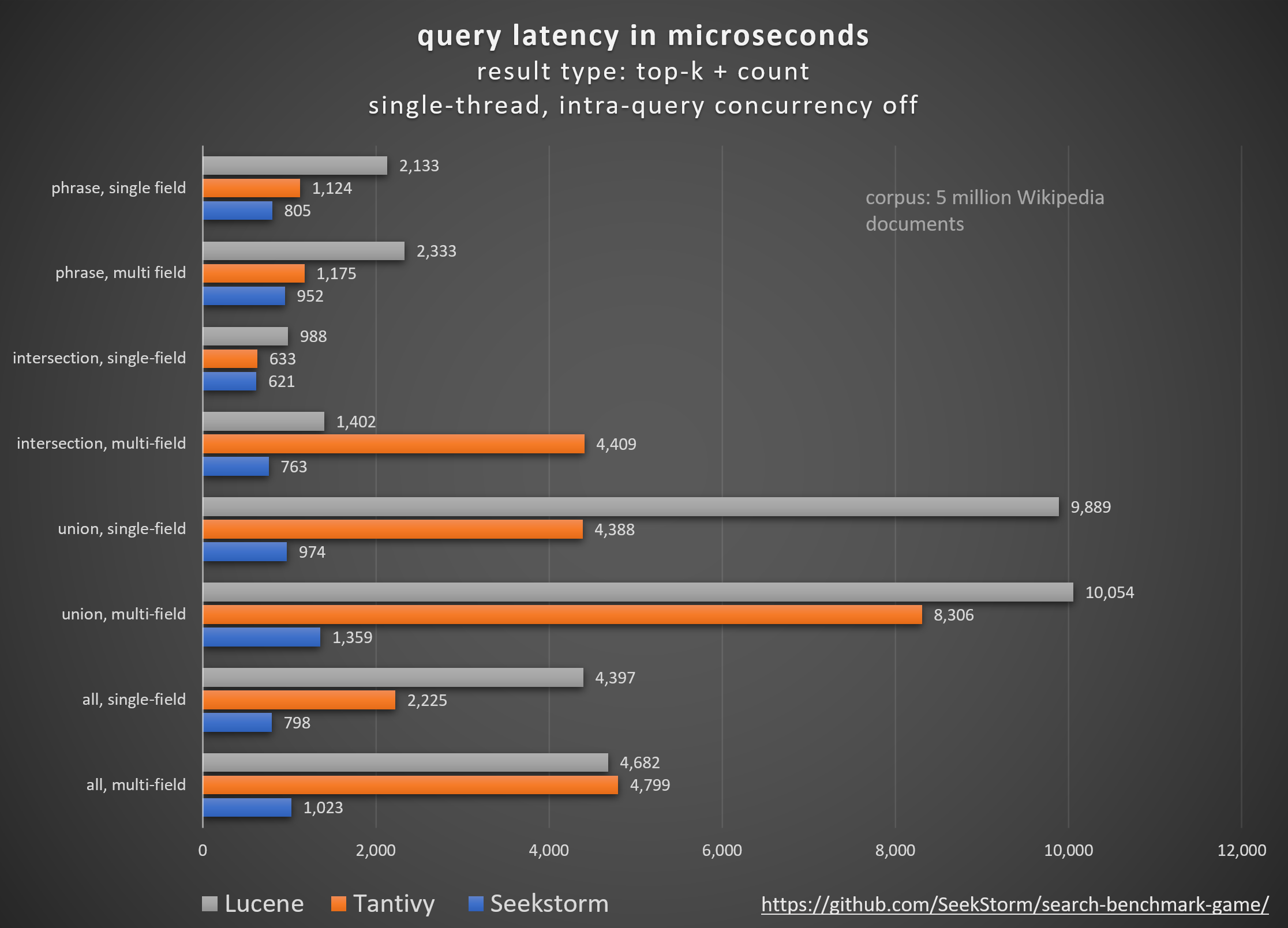
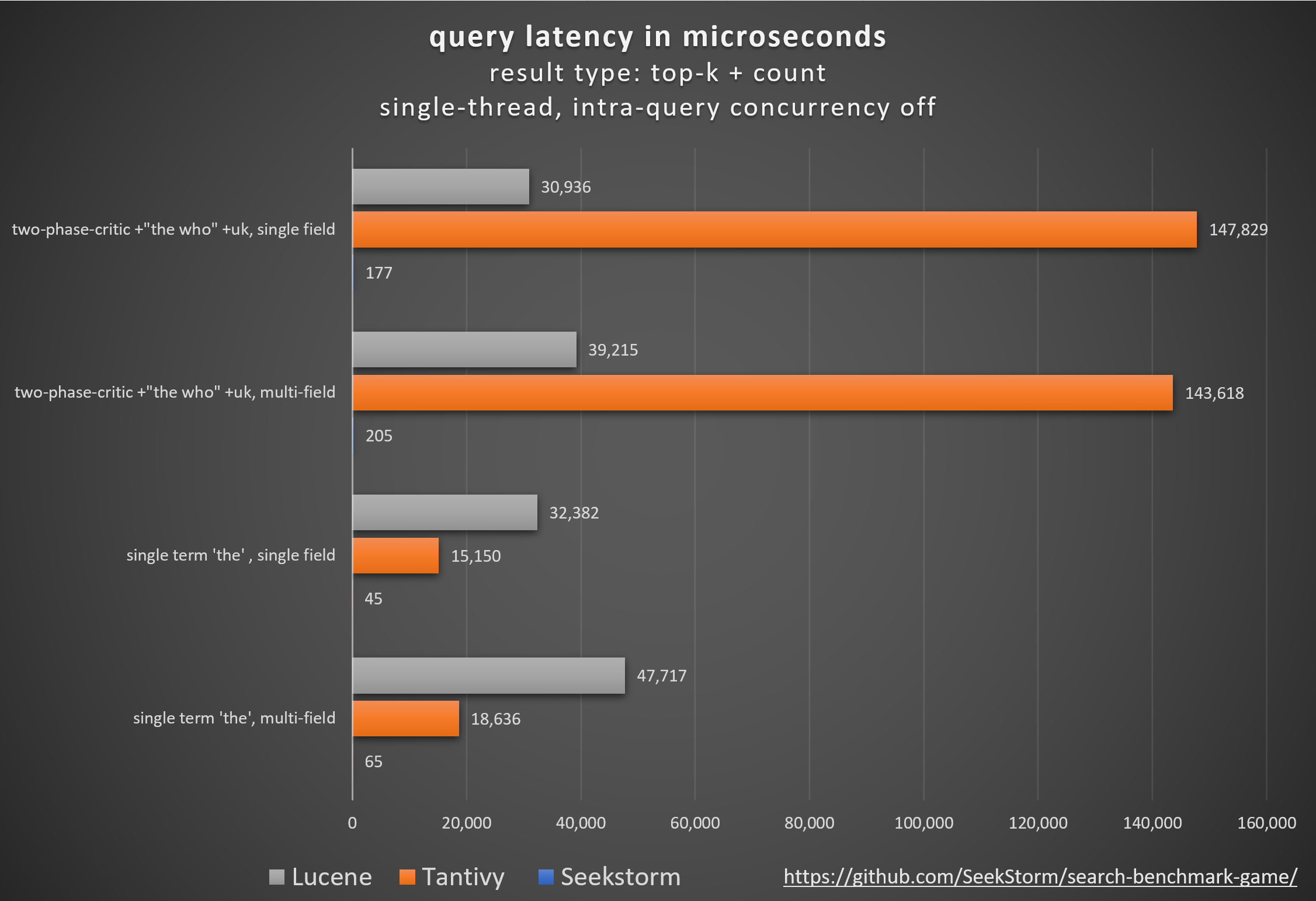
Leistung
Geringere Latenz, höherer Durchsatz, geringere Kosten und Energieverbrauch, insb. für Mehrfeld- und gleichzeitige Abfragen.
Geringe Tail-Latenzen sorgen für ein reibungsloses Benutzererlebnis und verhindern Kunden- und Umsatzverluste.
Während einige auf proprietäre Hardwarebeschleuniger (FPGA/ASIC) oder Cluster setzen, um die Leistung zu verbessern,
SeekStorm erreicht einen ähnlichen Boost algorithmisch auf einem einzelnen Commodity-Server.
Konsistenz
Keine unvorhersehbare Abfragelatenz während und nach der Indizierung großer Mengen, da SeekStorm keine ressourcenintensiven Segmentzusammenführungen erfordert.
Stabile Latenzen – keine Kaltstartkosten durch Just-in-Time-Kompilierung, keine unvorhersehbaren Verzögerungen bei der Garbage Collection.
Skalierung
Gewährleistet eine niedrige Latenz, einen hohen Durchsatz und einen geringen RAM-Verbrauch, selbst bei Indizes im Milliardenmaßstab.
Unbegrenzte Feldanzahl, Feldlänge und Indexgröße.
Relevanz
Das Begriffsnäheranking liefert im Vergleich zu BM25 relevantere Ergebnisse.
Echtzeit
Echte Echtzeitsuche im Gegensatz zu NRT: Jedes indizierte Dokument ist sofort durchsuchbar, sogar vor und während des Commits.
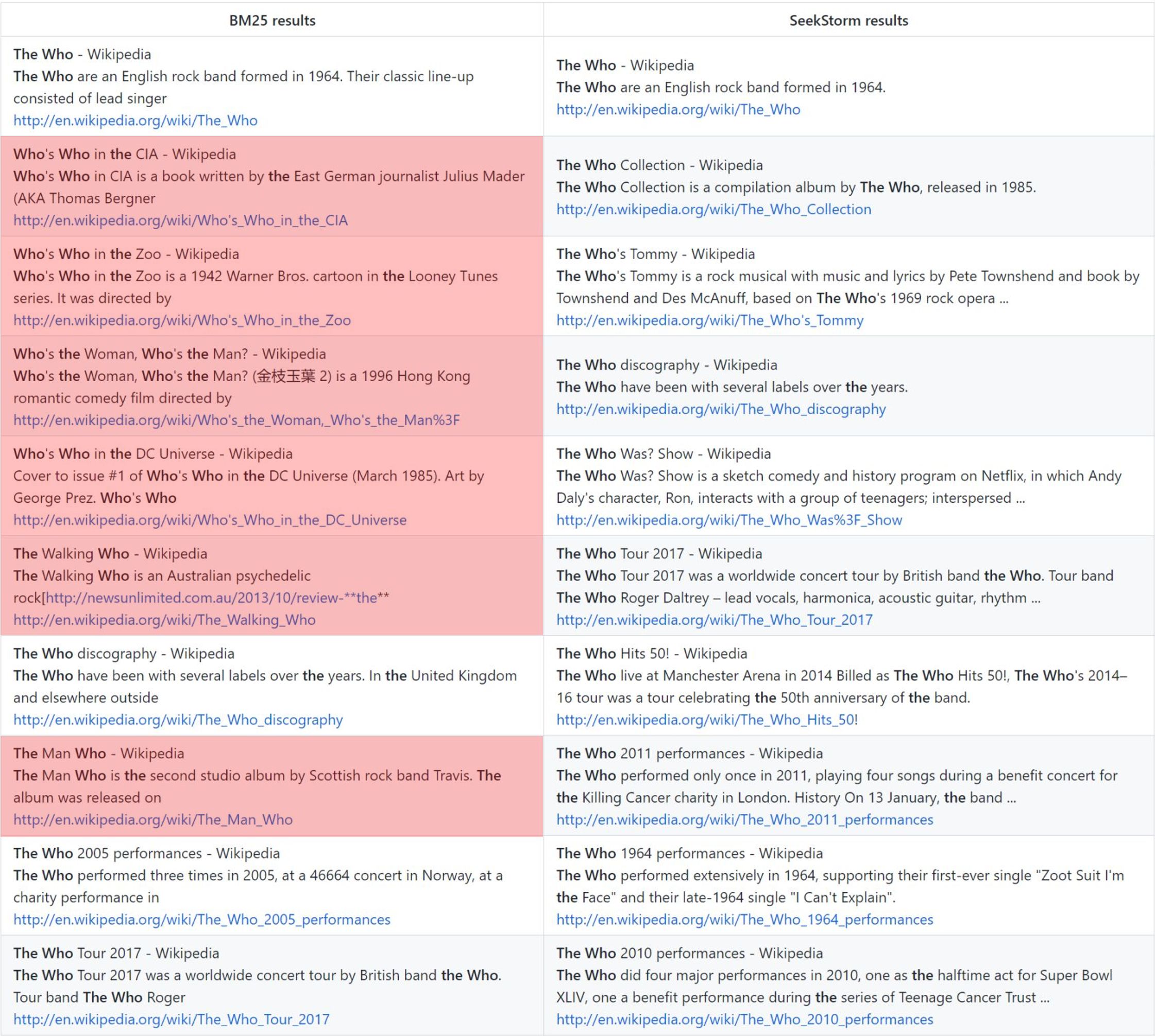
the who: Vanilla BM25-Rangliste vs. SeekStorm-Proximity-Rangliste
Methodik
Vergleich verschiedener Open-Source-Suchmaschinenbibliotheken (lexikalische Suche BM25) mithilfe des von Tantivy und Jason Wolfe entwickelten Open-Source -Suchbenchmarkspiels .
Vorteile
Detaillierte Benchmark-Ergebnisse https://seekstorm.github.io/search-benchmark-game/
Benchmark-Code-Repository https://github.com/SeekStorm/search-benchmark-game/
Ausführlichere Informationen finden Sie in unseren Blog-Beiträgen : SeekStorm ist jetzt Open Source und SeekStorm erhält Facettensuche, geografische Nähesuche und Ergebnissortierung
Ungeachtet dessen, was die Hype-Cycles https://www.bitecode.dev/p/hype-cycles Sie glauben machen wollen, ist die Schlüsselwortsuche nicht tot, da NoSQL nicht der Tod von SQL war.
Sie sollten einen Werkzeugkasten pflegen und das beste Werkzeug für Ihre Aufgabe auswählen. https://seekstorm.com/blog/vector-search-vs-keyword-search1/
Die Schlüsselwortsuche ist lediglich ein Filter für eine Reihe von Dokumenten, der diejenigen zurückgibt, in denen bestimmte Schlüsselwörter vorkommen, normalerweise kombiniert mit einer Ranking-Metrik wie BM25. Eine sehr grundlegende Kernfunktionalität, deren skalierbare Implementierung mit geringer Latenz eine große Herausforderung darstellt. Da die Funktionalität so einfach ist, gibt es eine unbegrenzte Anzahl von Anwendungsfeldern. Es handelt sich um eine Komponente, die zusammen mit anderen Komponenten verwendet werden kann. Es gibt Anwendungsfälle, die heute besser mit Vektorsuche und LLMs gelöst werden können, aber für viele weitere ist die Schlüsselwortsuche immer noch die beste Lösung. Die Stichwortsuche ist präzise, verlustfrei und sehr schnell, mit besserer Skalierung, besserer Latenz, geringeren Kosten und geringerem Energieverbrauch. Die Vektorsuche arbeitet mit semantischer Ähnlichkeit und liefert Ergebnisse innerhalb einer bestimmten Nähe und Wahrscheinlichkeit.
Wenn Sie nach genauen Ergebnissen wie Eigennamen, Nummern, Nummernschildern, Domänennamen und Phrasen (z. B. Plagiatserkennung) suchen, ist die Stichwortsuche Ihr Freund. Bei der Vektorsuche hingegen wird das genaue Ergebnis, nach dem Sie suchen, unter einer Vielzahl von Ergebnissen vergraben, die nur irgendwie semantisch miteinander in Zusammenhang stehen. Wenn Sie jedoch die genauen Begriffe nicht kennen oder an einem umfassenderen Thema, einer Bedeutung oder einem Synonym interessiert sind, wird die Stichwortsuche unabhängig davon, welche genauen Begriffe verwendet werden, scheitern.
- works with text data only
- unable to capture context, meaning and semantic similarity
- low recall for semantic meaning
+ perfect recall for exact keyword match
+ perfect precision (for exact keyword match)
+ high query speed and throughput (for large document numbers)
+ high indexing speed (for large document numbers)
+ incremental indexing fully supported
+ smaller index size
+ lower infrastructure cost per document and per query, lower energy consumption
+ good scalability (for large document numbers)
+ perfect for exact keyword and phrase search, no false positives
+ perfect explainability
+ efficient and lossless for exact keyword and phrase search
+ works with new vocabulary out of the box
+ works with any language out of the box
+ works perfect with long-tail vocabulary out of the box
+ works perfect with any rare language or domain-specific vocabulary out of the box
+ RAG (Retrieval-augmented generation) based on keyword search offers unrestricted real-time capabilities.Die Vektorsuche eignet sich perfekt, wenn Sie die genauen Suchbegriffe nicht kennen oder an einem umfassenderen Thema, einer Bedeutung oder einem Synonym interessiert sind, unabhängig davon, welche genauen Suchbegriffe verwendet werden. Wenn Sie jedoch nach genauen Begriffen suchen, z. B. Eigennamen, Nummern, Kennzeichen, Domainnamen und Phrasen (z. B. Plagiatserkennung), sollten Sie immer die Stichwortsuche verwenden. Bei der Vektorsuche wird das genaue Ergebnis, nach dem Sie suchen, nur unter einer Vielzahl von Ergebnissen vergraben, die nur irgendwie miteinander in Zusammenhang stehen. Es hat einen guten Rückruf, aber eine geringe Präzision und eine höhere Latenz. Es ist anfällig für Fehlalarme, z. B. bei der Plagiatserkennung, da genaue Wörter und Wortreihenfolge verloren gehen.
Mit der Vektorsuche können Sie nicht nur nach ähnlichem Text suchen, sondern nach allem, was in einen Vektor umgewandelt werden kann: Text, Bilder (Gesichtserkennung, Fingerabdrücke), Audio und ermöglicht Ihnen, magische Dinge wie Königin – Frau + Mann = König zu tun .
+ works with any data that can be transformed to a vector: text, image, audio ...
+ able to capture context, meaning, and semantic similarity
+ high recall for semantic meaning (90%)
- lower recall for exact keyword match (for Approximate Similarity Search)
- lower precision (for exact keyword match)
- lower query speed and throughput (for large document numbers)
- lower indexing speed (for large document numbers)
- incremental indexing is expensive and requires rebuilding the entire index periodically, which is extremely time-consuming and resource intensive.
- larger index size
- higher infrastructure cost per document and per query, higher energy consumption
- limited scalability (for large document numbers)
- unsuitable for exact keyword and phrase search, many false positives
- low explainability makes it difficult to spot manipulations, bias and root cause of retrieval/ranking problems
- inefficient and lossy for exact keyword and phrase search
- Additional effort and cost to create embeddings and keep them updated for every language and domain. Even if the number of indexed documents is small, the embeddings have to created from a large corpus before nevertheless.
- Limited real-time capability due to limited recency of embeddings
- works only with vocabulary known at the time of embedding creation
- works only with the languages of the corpus from which the embeddings have been derived
- works only with long-tail vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- works only with rare language or domain-specific vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- RAG (Retrieval-augmented generation) based on vector search offers only limited real-time capabilities, as it can't process new vocabulary that arrived after the embedding generationDie Vektorsuche ist kein Ersatz für die Stichwortsuche, sondern eine ergänzende Ergänzung – am besten für den Einsatz in einer Hybridlösung, bei der die Stärken beider Ansätze kombiniert werden. Die Stichwortsuche ist nicht veraltet, sondern bewährt .
Wir haben die SeekStorm-Codebasis (teilweise) von C# nach Rust portiert
Rust eignet sich hervorragend für leistungskritische Anwendungen, die mit großen Datenmengen und/oder vielen gleichzeitigen Benutzern arbeiten. Schnelle Algorithmen werden mit einer performancebewussten Programmiersprache noch mehr glänzen?
siehe ARCHITECTURE.md
cargo build --release
WARNUNG : Stellen Sie sicher, dass Sie die Umgebungsvariable MASTER_KEY_SECRET auf ein Geheimnis setzen, da sonst Ihre generierten API-Schlüssel gefährdet werden.
https://docs.rs/seekstorm
Erstellen Sie eine Dokumentation
cargo doc --no-deps
Greifen Sie lokal auf die Dokumentation zu
SeekStormtargetdocseekstormindex.html
SeekStormtargetdocseekstorm_serverindex.html
Fügen Sie Ihrem Projekt die erforderlichen Kisten hinzu
cargo add seekstorm
cargo add tokio
cargo add serde_json use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;Verwenden Sie eine asynchrone Rust-Laufzeit
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {Index erstellen
let index_path= Path :: new ( "C:/index/" ) ;
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":false,"indexed":false}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let _index_arc = Arc :: new ( RwLock :: new ( index ) ) ;Index öffnen (alternativ Index erstellen)
let index_path= Path :: new ( "C:/index/" ) ;
let mut index_arc= open_index ( index_path , false ) . await . unwrap ( ) ; Indexdokumente
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1"},
{"title":"title2","body":"body2 test","url":"url2"},
{"title":"title3 test","body":"body3 test","url":"url3"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; Dokumente festschreiben
index_arc . commit ( ) . await ;Suchindex
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter ) . await ;Ergebnisse anzeigen
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_string ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter= Some ( highlighter ( & index_arc , highlights , result_object . query_term_strings ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let mut index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}Multithread-Suche
let query_vec= vec ! [ "house" .to_string ( ) , "car" .to_string ( ) , "bird" .to_string ( ) , "sky" .to_string ( ) ] ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Union ;
let result_type= ResultType :: TopkCount ;
let thread_number = 4 ;
let permits = Arc :: new ( Semaphore :: new ( thread_number ) ) ;
for query in query_vec {
let permit_thread = permits . clone ( ) . acquire_owned ( ) . await . unwrap ( ) ;
let query_clone = query . clone ( ) ;
let index_arc_clone = index_arc . clone ( ) ;
let query_type_clone = query_type . clone ( ) ;
let result_type_clone = result_type . clone ( ) ;
let offset_clone = offset ;
let length_clone = length ;
tokio :: spawn ( async move {
let rlo = index_arc_clone
. search (
query_clone ,
query_type_clone ,
offset_clone ,
length_clone ,
result_type_clone ,
false ,
Vec :: new ( ) ,
)
. await ;
println ! ( "result count {}" , rlo.result_count ) ;
drop ( permit_thread ) ;
} ) ;
}Indexieren Sie die JSON-Datei im JSON-, Newline-Delimited-JSON- und Concatenated-JSON-Format
let file_path= Path :: new ( "wiki_articles.json" ) ;
let _ =index_arc . ingest_json ( file_path ) . await ;Indizieren Sie alle PDF-Dateien im Verzeichnis und in Unterverzeichnissen
ingest -Befehl erstellt): [
{
"field" : " title " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text " ,
"boost" : 10
},
{
"field" : " body " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text "
},
{
"field" : " url " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Text "
},
{
"field" : " date " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Timestamp " ,
"facet" : true
}
] let file_path= Path :: new ( "C:/Users/johndoe/Downloads" ) ;
let _ =index_arc . ingest_pdf ( file_path ) . await ;Index-PDF-Datei
let file_path= Path :: new ( "C:/test.pdf" ) ;
let file_date= Utc :: now ( ) . timestamp ( ) ;
let _ =index_arc . index_pdf_file ( file_path ) . await ;Indiziert PDF-Dateibytes
let file_date= Utc :: now ( ) . timestamp ( ) ;
let document = fs :: read ( file_path ) . unwrap ( ) ;
let _ =index_arc . index_pdf_bytes ( file_path , file_date , & document ) . await ;PDF-Dateibytes abrufen
let doc_id= 0 ;
let file=index . get_file ( doc_id ) . unwrap ( ) ;übersichtlicher Index
index . clear_index ( ) ;Index löschen
index . delete_index ( ) ;Index schließen
index . close_index ( ) ;Versionszeichenfolge der Seekstorm-Bibliothek
let version= version ( ) ;
println ! ( "version {}" ,version ) ;Facetten werden an drei verschiedenen Stellen definiert:
Ein minimales Arbeitsbeispiel für die Facettenindizierung und -suche erfordert nur 60 Codezeilen. Aber es könnte mühsam sein, alles allein anhand der Dokumentation zusammenzusetzen. Aus diesem Grund stellen wir Ihnen hier ein Schnellstartbeispiel zur Verfügung:
Fügen Sie Ihrem Projekt die erforderlichen Kisten hinzu
cargo add seekstorm
cargo add tokio
cargo add serde_jsonNutzungserklärungen hinzufügen
use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;Verwenden Sie eine asynchrone Rust-Laufzeit
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {Index erstellen
let index_path= Path :: new ( "C:/index/" ) ; //x
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":true,"indexed":false},
{"field":"town","field_type":"String","stored":false,"indexed":false,"facet":true}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let mut index_arc = Arc :: new ( RwLock :: new ( index ) ) ;Indexdokumente
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1","town":"Berlin"},
{"title":"title2","body":"body2 test","url":"url2","town":"Warsaw"},
{"title":"title3 test","body":"body3 test","url":"url3","town":"New York"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; Dokumente festschreiben
index_arc . commit ( ) . await ;Suchindex
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let query_facets = vec ! [ QueryFacet :: String { field: "age" .to_string ( ) ,prefix: "" .to_string ( ) ,length: u16 :: MAX } ] ;
let facet_filter= Vec :: new ( ) ;
//let facet_filter = vec![FacetFilter::String { field: "town".to_string(),filter: vec!["Berlin".to_string()],}];
let facet_result_sort= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter , query_facets , facet_filter ) . await ;Ergebnisse anzeigen
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_owned ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter2= Some ( highlighter ( & index_arc , highlights , result_object . query_terms ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter2 , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}Facetten darstellen
println ! ( "{}" , serde_json::to_string_pretty ( &result_object.facets ) .unwrap ( ) ) ;Ende der Hauptfunktion
Ok ( ( ) )
} Eine kurze Schritt-für-Schritt-Anleitung zum Erstellen einer Wikipedia-Suchmaschine aus einem Wikipedia-Korpus mithilfe des SeekStorm-Servers in 5 einfachen Schritten.

Laden Sie SeekStorm herunter
Laden Sie SeekStorm aus dem GitHub-Repository herunter
Entpacken Sie es in ein Verzeichnis Ihrer Wahl und öffnen Sie es im Visual Studio-Code.
oder alternativ
git clone https://github.com/SeekStorm/SeekStorm.git
Erstellen Sie SeekStorm
Installieren Sie Rust (falls noch nicht vorhanden): https://www.rust-lang.org/tools/install
Geben Sie im Terminal von Visual Studio Code Folgendes ein:
cargo build --release
Holen Sie sich den Wikipedia-Korpus
Vorverarbeitetes englisches Wikipedia-Korpus (5.032.105 Dokumente, 8,28 GB dekomprimiert). Obwohl wiki-articles.json die Erweiterung .JSON hat, handelt es sich nicht um eine gültige JSON-Datei. Es handelt sich um eine Textdatei, in der jede Zeile ein JSON-Objekt mit URL-, Titel- und Textattributen enthält. Das Format heißt ndjson („Newline delimited JSON“).
Laden Sie das Wikipedia-Korpus herunter
Dekomprimiert den Wikipedia-Korpus.
https://gnuwin32.sourceforge.net/packages/bzip2.htm
bunzip2 wiki-articles.json.bz2
Verschieben Sie die dekomprimierte Datei wiki-articles.json in das Release-Verzeichnis
Starten Sie den SeekStorm-Server
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
Indizierung
Geben Sie „ingest“ in die Befehlszeile des laufenden SeekStorm-Servers ein:
ingest
Dadurch wird der Demo-Index erstellt und die lokale Wikipedia-Datei indiziert.
Beginnen Sie mit der Suche in der eingebetteten WebUI
Öffnen Sie die eingebettete Web-Benutzeroberfläche im Browser: http://127.0.0.1
Geben Sie eine Suchanfrage in das Suchfeld ein
Testen der REST-API-Endpunkte
Öffnen Sie src/seekstorm_server/test_api.rest in VSC zusammen mit der VSC-Erweiterung „Rest Client“, um API-Aufrufe auszuführen und Antworten zu überprüfen
Beispiele für interaktive API-Endpunkte
Legen Sie den „individuellen API-Schlüssel“ in test_api.rest auf den API-Schlüssel fest, der in der Serverkonsole angezeigt wird, als Sie oben „index“ eingegeben haben.
Demo-Index entfernen
Geben Sie „delete“ in die Befehlszeile des laufenden SeekStorm-Servers ein:
delete
Server herunterfahren
Geben Sie „quit“ in die Befehlszeile des laufenden SeekStorm-Servers ein.
quit
Anpassen
Möchten Sie etwas Ähnliches für Ihr eigenes Projekt verwenden? Schauen Sie sich die Ingest- und Web-UI-Dokumentation an.
Eine kurze Schritt-für-Schritt-Anleitung zum Erstellen einer PDF-Suchmaschine aus einem Verzeichnis, das PDF-Dateien enthält, mithilfe des SeekStorm-Servers.
Machen Sie alle Ihre wissenschaftlichen Arbeiten, E-Books, Lebensläufe, Berichte, Verträge, Dokumentationen, Handbücher, Briefe, Kontoauszüge, Rechnungen und Lieferscheine durchsuchbar – zu Hause oder in Ihrer Organisation.
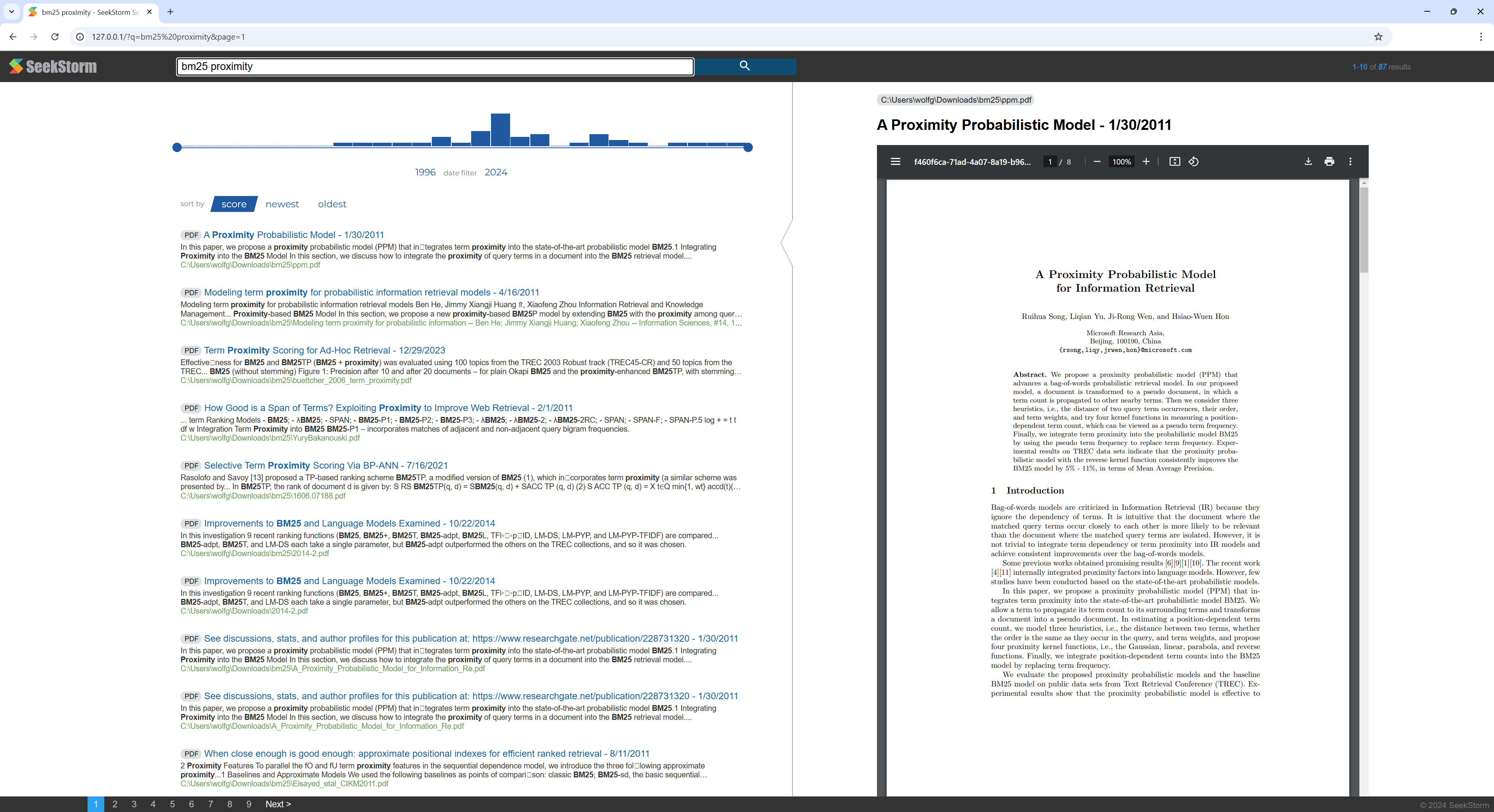
Erstellen Sie SeekStorm
Installieren Sie Rust (falls noch nicht vorhanden): https://www.rust-lang.org/tools/install
Geben Sie im Terminal von Visual Studio Code Folgendes ein:
cargo build --release
Laden Sie PDFium herunter
Laden Sie die Pdfium-Bibliothek herunter und kopieren Sie sie in denselben Ordner wie seestorm_server.exe: https://github.com/bblanchon/pdfium-binaries
Starten Sie den SeekStorm-Server
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
Indizierung
Wählen Sie ein Verzeichnis, das PDF-Dateien enthält, die Sie indizieren und durchsuchen möchten, z. B. Ihre Dokumente oder das Download-Verzeichnis.
Geben Sie „ingest“ in die Befehlszeile des laufenden SeekStorm-Servers ein:
ingest C:UsersJohnDoeDownloads
Dadurch wird der pdf_index erstellt und alle PDF-Dateien aus dem angegebenen Verzeichnis einschließlich der Unterverzeichnisse indiziert.
Beginnen Sie mit der Suche in der eingebetteten WebUI
Öffnen Sie die eingebettete Web-Benutzeroberfläche im Browser: http://127.0.0.1
Geben Sie eine Suchanfrage in das Suchfeld ein
Demo-Index entfernen
Geben Sie „delete“ in die Befehlszeile des laufenden SeekStorm-Servers ein:
delete
Server herunterfahren
Geben Sie „quit“ in die Befehlszeile des laufenden SeekStorm-Servers ein.
quit
Volltextsuche 30 Mio. Hacker-Newsbeiträge UND verlinkte Webseiten
DeepHN.org
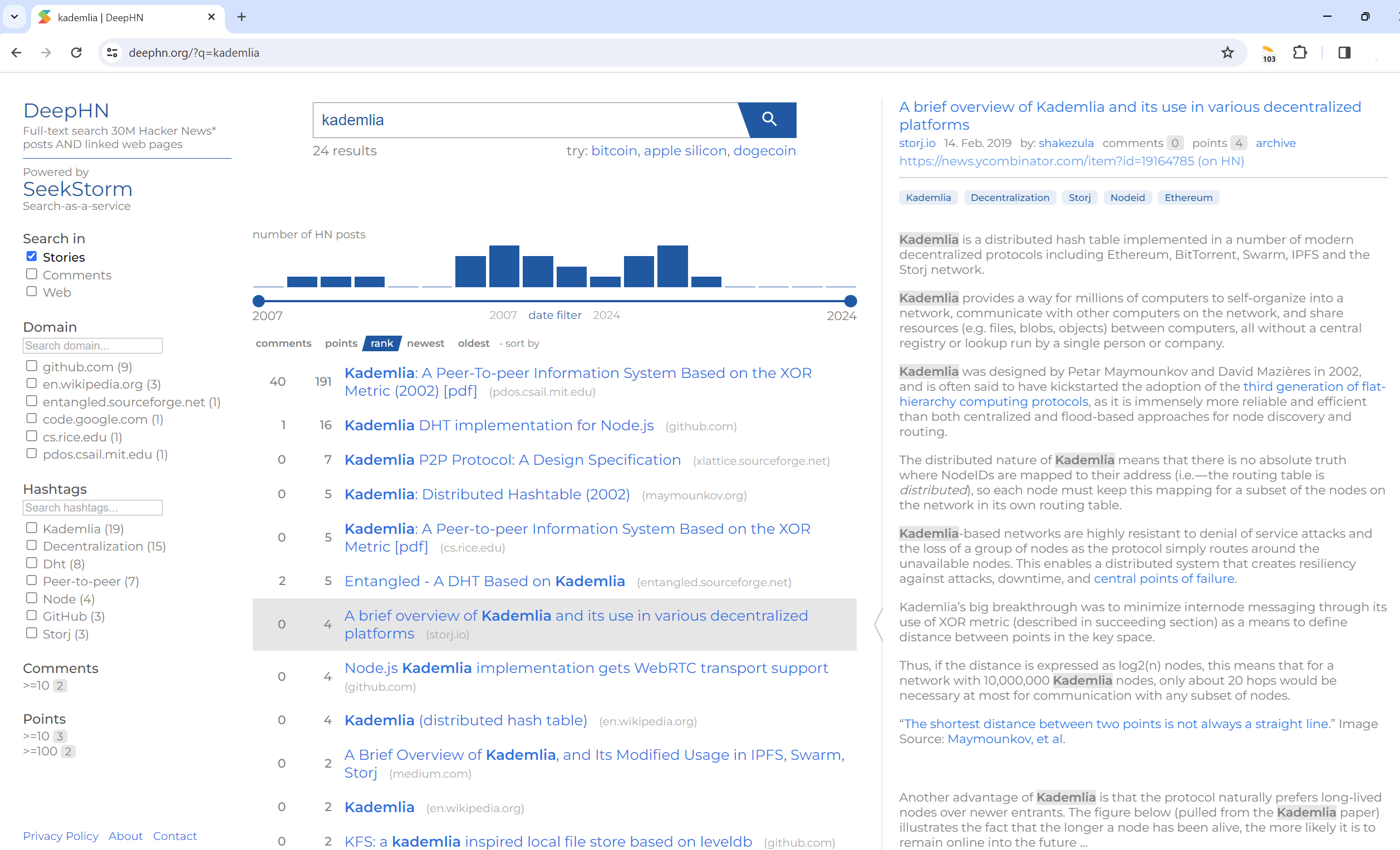
Die DeepHN-Demo basiert weiterhin auf der SeekStorm C#-Codebasis.
Wir portieren derzeit alle erforderlichen fehlenden Funktionen.
Siehe Roadmap unten.
Der Rust-Port ist noch nicht vollständig ausgestattet. Die folgenden Funktionen werden derzeit portiert.
Portierung
Verbesserungen
Neue Funktionen


