auctus
1.0.0
Bei diesem Projekt handelt es sich um einen Webcrawler und eine Suchmaschine für Datensätze, die speziell für Datenerweiterungsaufgaben beim maschinellen Lernen gedacht sind. Es ist in der Lage, Datensätze in verschiedenen Repositories zu finden und sie für den späteren Abruf zu indizieren.
Die Dokumentation finden Sie hier
Es ist in mehrere Komponenten unterteilt:
datamart_geo . Diese enthält Daten über Verwaltungsgebiete, die aus Wikidata und OpenStreetMap extrahiert wurden. Es befindet sich in einem eigenen Repository und wird hier als Submodul verwendet.datamart_profiler . Dies kann von Clients installiert werden und ermöglicht der Client-Bibliothek, Datensätze lokal zu profilieren, anstatt sie an den Server zu senden. Es wird auch von den Apiserver- und Profiler-Diensten verwendet.datamart_materialize . Dies wird verwendet, um Datensätze aus den verschiedenen Quellen zu materialisieren, die Auctus unterstützt. Es kann von Clients installiert werden, wodurch diese Datensätze lokal materialisieren können, anstatt den Server als Proxy zu verwenden.datamart_augmentation . Dies führt die Verknüpfung oder Vereinigung zweier Datensätze durch und wird vom Apiserver-Dienst verwendet, könnte aber auch eigenständig verwendet werden.datamart_core . Dies enthält allgemeinen Code für Dienste. Wird nur für die Serverkomponenten verwendet. Der Dateisystem-Sperrcode wird aus Leistungsgründen separat als datamart_fslock bezeichnet (muss schnell importiert werden).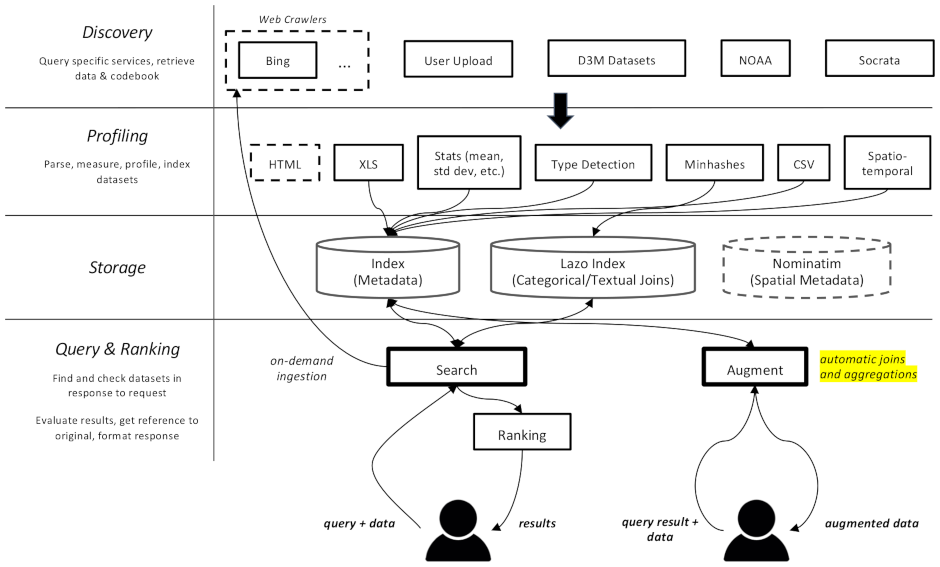
Als Suchindex wird Elasticsearch verwendet, das ein Dokument pro bekanntem Datensatz speichert.
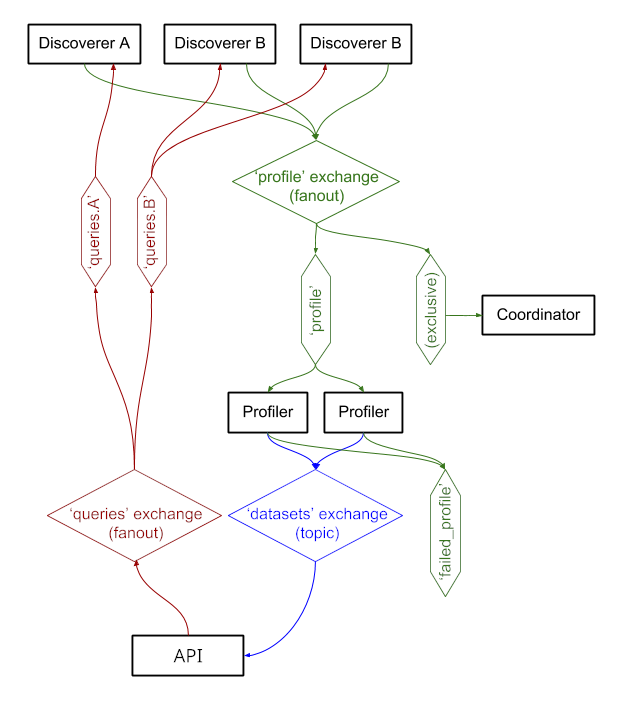
Die Dienste tauschen Nachrichten über RabbitMQ aus, sodass wir über komplexe Nachrichtenmuster mit Warteschlangen- und Wiederholungssemantik sowie über komplexe Muster wie die On-Demand-Abfrage verfügen können.
Das System läuft derzeit unter https://auctus.vida-nyu.org/. Den Systemstatus können Sie unter https://grafana.auctus.vida-nyu.org/ einsehen.
Um das System lokal mit Docker-Compose bereitzustellen, führen Sie die folgenden Schritte aus:
Stellen Sie sicher, dass Sie das Submodul mit git submodule init && git submodule update ausgecheckt haben
Stellen Sie sicher, dass Git LFS installiert und konfiguriert ist ( git lfs install ).
Kopieren Sie env.default nach .env und aktualisieren Sie die Variablen dort. Möglicherweise möchten Sie das Kennwort für eine Produktionsbereitstellung aktualisieren.
Stellen Sie sicher, dass Ihr Knoten für die Ausführung von Elasticsearch eingerichtet ist. Sie müssen wahrscheinlich das mmap-Limit erhöhen.
Die API_URL ist die URL, unter der die Apiserver-Container für Clients sichtbar sind. In einer Produktionsbereitstellung handelt es sich wahrscheinlich um eine öffentlich zugängliche HTTPS-URL. Es kann sich um dieselbe URL handeln, unter der die „Koordinator“-Komponente bereitgestellt wird, wenn ein Reverse-Proxy verwendet wird (siehe nginx.conf).
Um Skripte lokal auszuführen, können Sie die Umgebungsvariablen in Ihre Shell laden, indem Sie Folgendes ausführen: . scripts/load_env.sh (das sind Dot-Space-Skripte... )
Führen Sie scripts/setup.sh aus, um die Datenvolumes zu initialisieren. Dadurch werden die richtigen Berechtigungen für die volumes/ Unterverzeichnisse festgelegt.
Wenn Sie jemals ganz von vorne beginnen möchten, können Sie volumes/ löschen. Führen Sie anschließend jedoch unbedingt scripts/setup.sh erneut aus, um die Berechtigungen festzulegen.
$ docker-compose build --build-arg version=$(git describe) apiserver
$ docker-compose up -d elasticsearch rabbitmq redis minio lazo
Es wird einige Sekunden dauern, bis diese betriebsbereit sind. Dann können Sie die anderen Komponenten starten:
$ docker-compose up -d cache-cleaner coordinator profiler apiserver apilb frontend
Sie können die Option --scale verwenden, um weitere Profiler- oder Apiserver-Container zu starten, zum Beispiel:
$ docker-compose up -d --scale profiler=4 --scale apiserver=8 cache-cleaner coordinator profiler apiserver apilb frontend
Häfen:
$ scripts/docker_import_snapshot.sh
Dadurch wird ein Elasticsearch-Dump von auctus.vida-nyu.org heruntergeladen und in Ihren lokalen Elasticsearch-Container importiert.
$ docker-compose up -d socrata zenodo
$ docker-compose up -d elasticsearch_exporter prometheus grafana
Prometheus ist so konfiguriert, dass es die Container automatisch findet (siehe prometheus.yml).
Es wird ein benutzerdefiniertes RabbitMQ-Image mit zusätzlichen Plugins (Management und Prometheus) verwendet.


