elastic_transformers
1.0.0
Semantische Elasticsearch mit Satztransformatoren. Wir werden die Leistungsfähigkeit von Elastic und die Magie von BERT nutzen, um eine Million Artikel zu indizieren und eine lexikalische und semantische Suche darauf durchzuführen.
Der Zweck besteht darin, eine benutzerfreundliche Möglichkeit zum Einrichten Ihrer eigenen Elasticsearch mit nahezu modernsten Funktionen für kontextuelle Einbettungen/semantische Suche mithilfe von NLP-Transformatoren bereitzustellen.
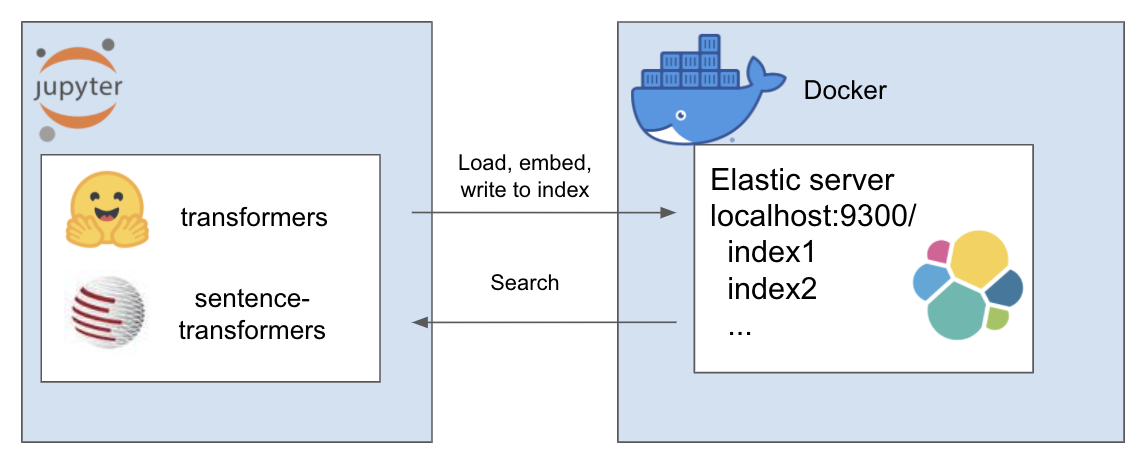
Das obige Setup funktioniert wie folgt
Meine Umgebung heißt et und ich verwende dafür Conda. Navigieren Sie in das Projektverzeichnis
conda create - - name et python = 3.7
conda install - n et nb_conda_kernels
conda activate et
pip install - r requirements . txtFür dieses Tutorial verwende ich A Million News Headlines von Rohk und lege es im Datenordner im Projektverzeichnis ab.
elastic_transformers/
├── data/
Sie werden feststellen, dass die Schritte ansonsten ziemlich abstrakt sind, sodass Sie dies auch mit dem Datensatz Ihrer Wahl tun können
Befolgen Sie die Anweisungen zum Einrichten von Elastic mit Docker auf der Elastic-Seite hier. Für dieses Tutorial müssen Sie nur die beiden Schritte ausführen:
Das Repo führt die ElasiticTransformers-Klasse ein. Dienstprogramme, die beim Erstellen, Indexieren und Abfragen von Elasticsearch-Indizes helfen, einschließlich Einbettungen
Initiieren Sie die Verbindungslinks sowie (optional) den Namen des Index, mit dem gearbeitet werden soll
et = ElasticTransformers ( url = 'http://localhost:9300' , index_name = 'et-tiny' )create_index_spec definiert die Zuordnung für den Index. Für die Stichwortsuche oder die semantische Suche (dichte Vektorsuche) können Listen relevanter Felder bereitgestellt werden. Es verfügt auch über Parameter für die Größe des dichten Vektors, da diese variieren können. create_index – verwendet die zuvor erstellte Spezifikation, um einen Index zu erstellen, der für die Suche bereit ist
et . create_index_spec (
text_fields = [ 'publish_date' , 'headline_text' ],
dense_fields = [ 'headline_text_embedding' ],
dense_fields_dim = 768
)
et . create_index ()write_large_csv – teilt eine große CSV-Datei in Blöcke auf und verwendet iterativ ein vordefiniertes Einbettungsdienstprogramm, um die Einbettungsliste für jeden Block zu erstellen und anschließend die Ergebnisse dem Index zuzuführen
et . write_large_csv ( 'data/tiny_sample.csv' ,
chunksize = 1000 ,
embedder = embed_wrapper ,
field_to_embed = 'headline_text' )Suche – ermöglicht die Auswahl entweder einer Schlüsselwortsuche („Übereinstimmung“ in Elastic) oder einer semantischen Suche (dichte Suche in Elastic). Insbesondere ist die gleiche Einbettungsfunktion erforderlich, die in write_large_csv verwendet wird
et . search ( query = 'search these terms' ,
field = 'headline_text' ,
type = 'match' ,
embedder = embed_wrapper ,
size = 1000 )Verwenden Sie nach erfolgreicher Einrichtung die folgenden Notizbücher, damit alles funktioniert
Dieses Repo vereint die folgenden erstaunlichen Werke brillanter Menschen. Bitte schauen Sie sich ihre Arbeit an, falls Sie dies noch nicht getan haben ...


