cyac
1.0.0
Leistungsstarkes Trie- und Keyword-Match-and-Replace-Tool.
Es wird von Cython implementiert und zu cpp kompiliert. Die Trie-Datenstruktur ist Cedar, ein optimierter Doppel-Array-Trie. es unterstützt Python2.7 und 3.4+. Es unterstützt das Entleeren und Laden der Gurke.
Wenn Sie dies nützlich fanden, geben Sie bitte einen Stern!
Dieses Modul ist in Cython geschrieben. Sie müssen Cython installiert haben.
pip install cyac
Dann erstellen Sie einen Trie
>>> from cyac import Trie
>>> trie = Trie()
Schlüsselwort hinzufügen/abrufen/entfernen
>>> trie.insert(u"哈哈") # return keyword id in trie, return -1 if doesn't exist
>>> trie.get(u"哈哈") # return keyword id in trie, return -1 if doesn't exist
>>> trie.remove(u"呵呵") # return keyword in trie
>>> trie[id] # return the word corresponding to the id
>>> trie[u"呵呵"] # similar to get but it will raise exeption if doesn't exist
>>> u"呵呵" in trie # test if the keyword is in trie
Holen Sie sich alle Schlüsselwörter
>>> for key, id_ in trie.items():
>>> print(key, id_)
Präfix/Vorhersage
>>> # return the string in the trie which starts with given string
>>> for id_ in trie.predict(u"呵呵"):
>>> print(id_)
>>> # return the prefix of given string which is in the trie.
>>> for id_, len_ in trie.prefix(u"呵呵"):
>>> print(id_, len_)
Versuchen Sie es zu extrahieren und zu ersetzen
>>> python_id = trie.insert(u"python")
>>> trie.replace_longest("python", {python_id: u"hahah"}, set([ord(" ")])) # the second parameter is seperator. If you specify seperators. it only matches strings tween seperators. e.g. It won't match 'apython'
>>> for id_, start, end in trie.match_longest(u"python", set([ord(" ")])):
>>> print(id_, start, end)
Aho Corasick-Extrakt
>>> ac = AC.build([u"python", u"ruby"])
>>> for id, start, end in ac.match(u"python ruby"):
>>> print(id, start, end)
In eine Datei exportieren, dann können wir mmap verwenden, um Dateien zu laden und Daten zwischen Prozessen auszutauschen.
>>> ac = AC.build([u"python", u"ruby"])
>>> ac.save("filename")
>>> ac.to_buff(buff_object)
Init vom Python-Puffer
>>> import mmap
>>> with open("filename", "r+b") as bf:
buff_object = mmap.mmap(bf.fileno(), 0)
>>> AC.from_buff(buff_object, copy=True) # it allocs new memory
>>> AC.from_buff(buff_object, copy=False) # it shares memory
Beispiel für mehrere Prozesse
import mmap
from multiprocessing import Process
from cyac import AC
def get_mmap():
with open("random_data", "r+b") as bf:
buff_object = mmap.mmap(bf.fileno(), 0)
ac_trie = AC.from_buff(buff_object, copy=False)
# Do your aho searches here. "match" function is process safe.
processes_list = list()
for x in range(0, 6):
p = Process(
target=get_mmap,
)
p.start()
processes_list.append(p)
for p in processes_list:
p.join()
Weitere Informationen zu Multiprocessing und Speicheranalyse in Cyac finden Sie in dieser Ausgabe.
Die Funktion „match“ des AC-Automaten ist Thread-/prozesssicher. Es ist möglich, Übereinstimmungen parallel zu einem gemeinsam genutzten AC-Automaten zu finden, aber keine Muster daran zu schreiben/anzuhängen.
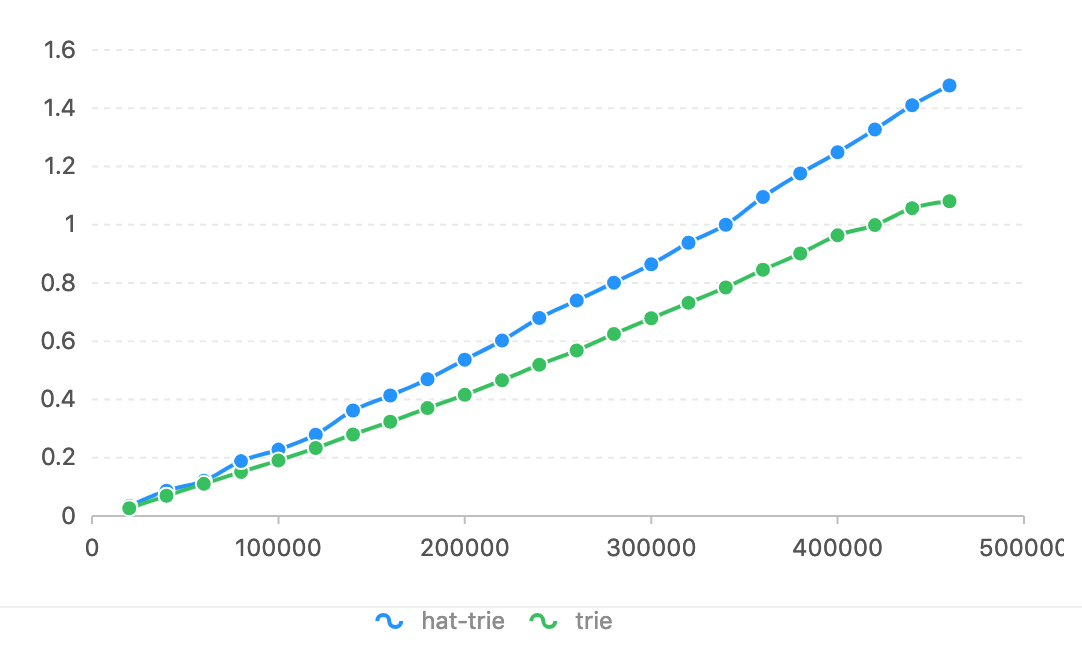
Auf Ubuntu 14.04.5/Intel(R) Core(TM) i7-4790K CPU bei 4,00 GHz.
Im Vergleich zu HatTrie ist die Horizontachse eine Token-Nummer. Auf der vertikalen Achse wird die Zeit (Sekunden) verwendet.
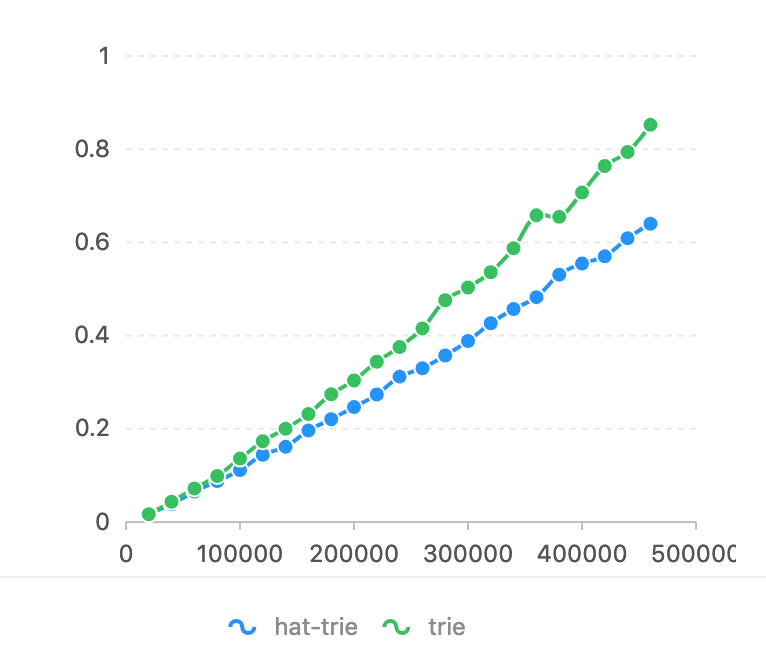
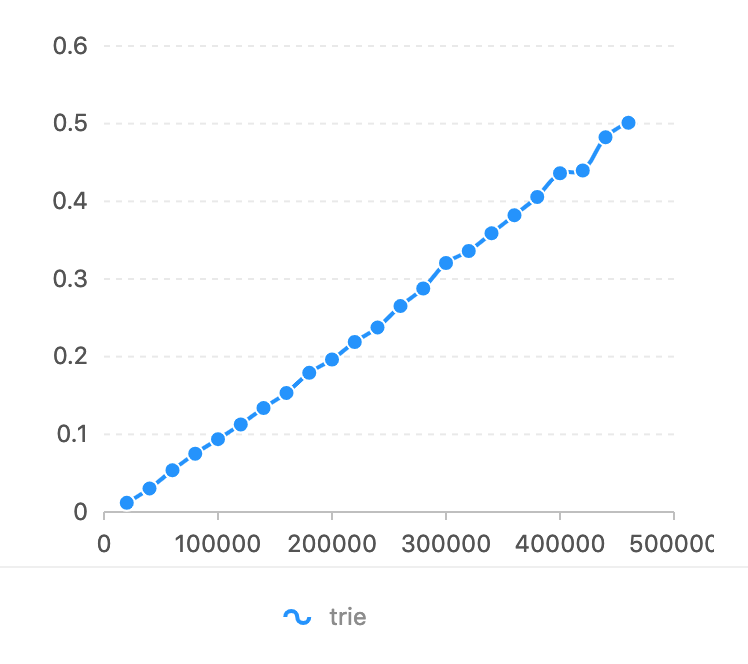
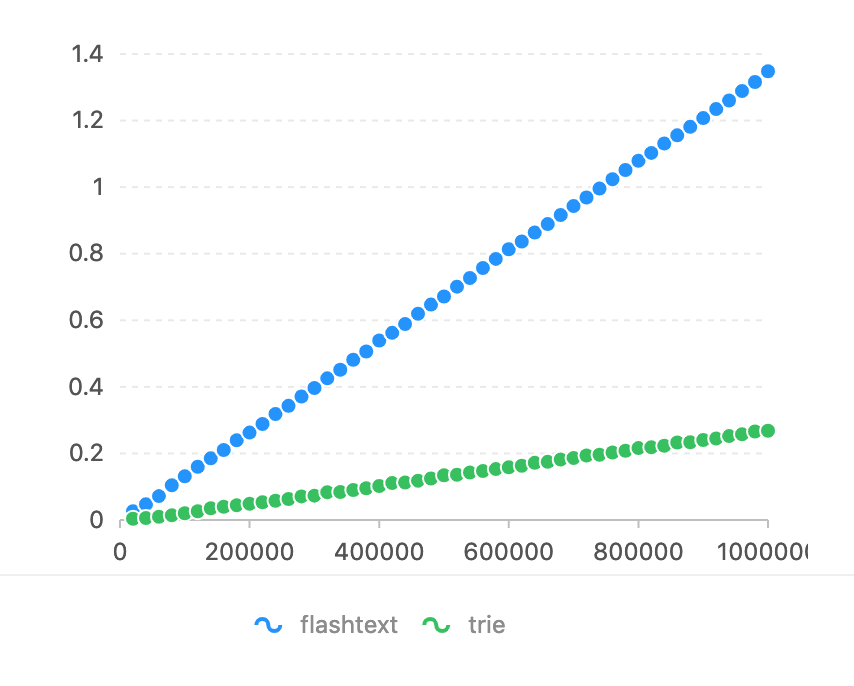
Im Vergleich zu flashText. Der reguläre Ausdruck ist bei dieser Aufgabe zu langsam (siehe Benchmark von flashText). Die zu vergleichende Zeichenzahl ist die Horizontachse. Auf der vertikalen Achse wird die Zeit (Sekunden) verwendet.
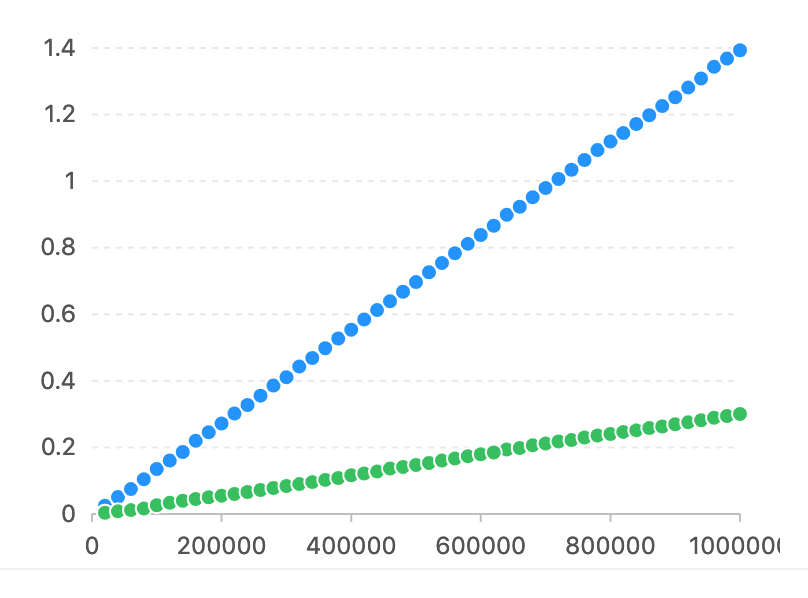
Im Vergleich zu Pyahocorasick muss die Horizon-Achse übereinstimmen. Auf der vertikalen Achse wird die Zeit (Sekunden) verwendet.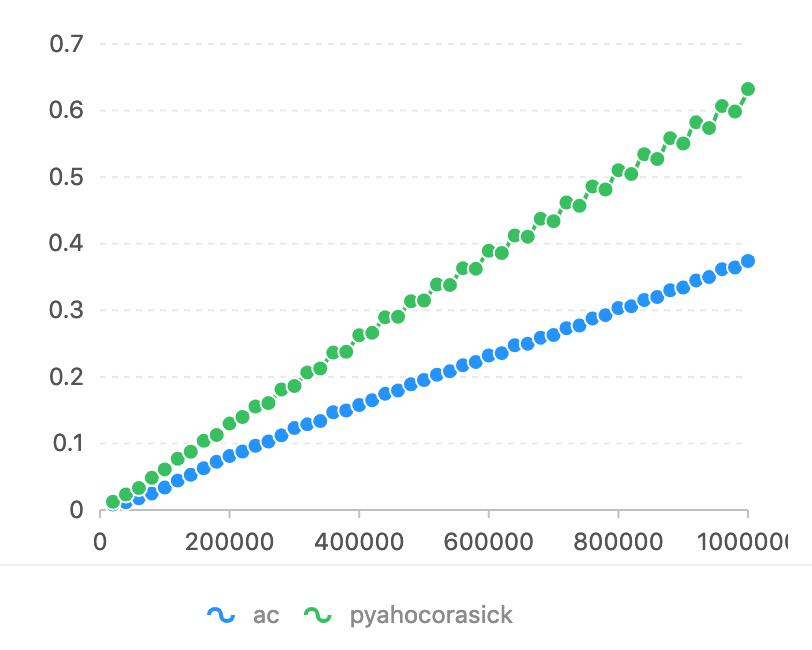
>>> len(char.lower()) == len(char) # this is always true in python2, but not in python3
>>> len(u"İstanbul") != len(u"İstanbul".lower()) # in python3
Bei einem Vergleich ohne Berücksichtigung der Groß-/Kleinschreibung kümmert sich diese Bibliothek um diese Tatsache und gibt den korrekten Offset zurück.
python setup.py build
PYTHONPATH= $( pwd ) /build/BUILD_DST python3 tests/test_all.py
PYTHONPATH= $( pwd ) /build/BUILD_DST python3 bench/bench_ * .py

